
编译原理
编译原理
研究翻译的科学.
高级语言 -> 低级语言 -> 机器语言(二进制)
让计算机理解更高级的语言并执行.
给人提供更好的思考方式(抽象).
一个范畴映射到另外一个范畴.

编译原理其它用途
- 专家系统(prolog)
- 内置脚本(lua, javascript)
- 领域建模(HTML, SQL, 业务语言)
编译原理的[翻译]能力只能作用在 形式语言 上, 是上下文无关的, 这样就可以抽象语法树.
计算机语言提供了新的思考方式. 例如: 基于OOP语言的思考领域 – 万事万物.
学习多门语言是有必要的, 每门语言有各自的思考方式.
编译器和解析器
编译器
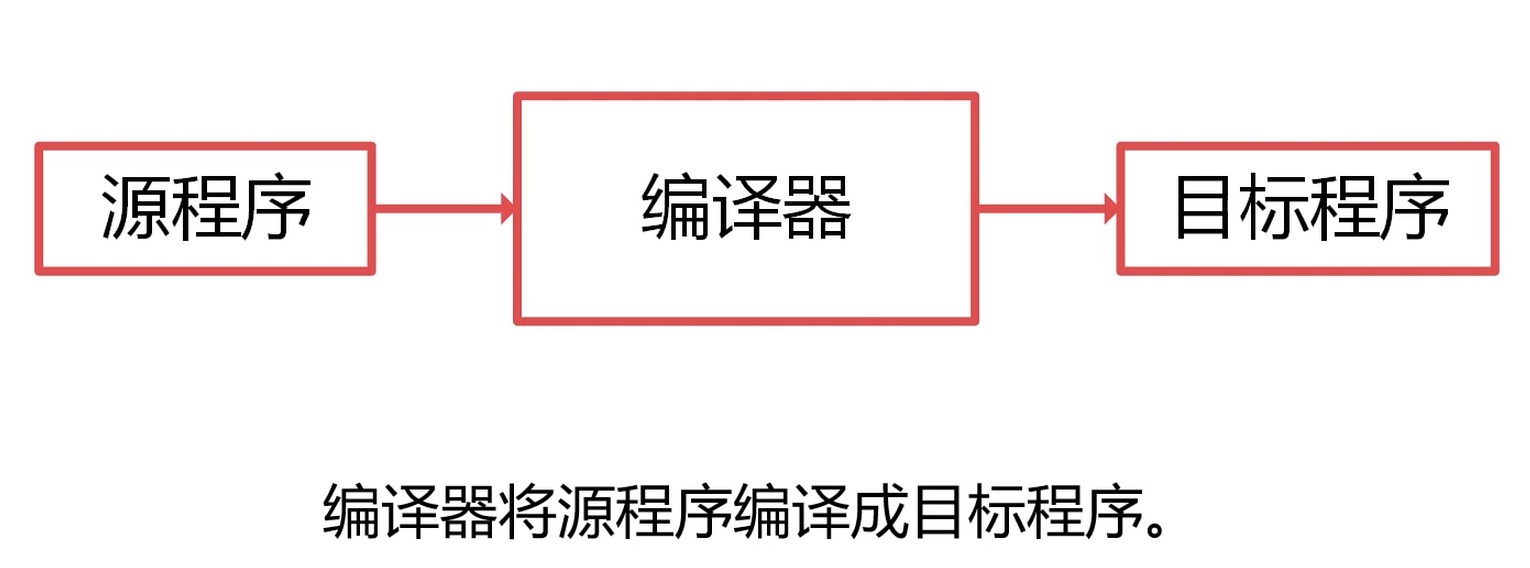
程序其实就是一个输入映射成输出的过程? 不是, 和函数有区别. 程序虽然没有输出, 但是也有改变客观世界.
解释器
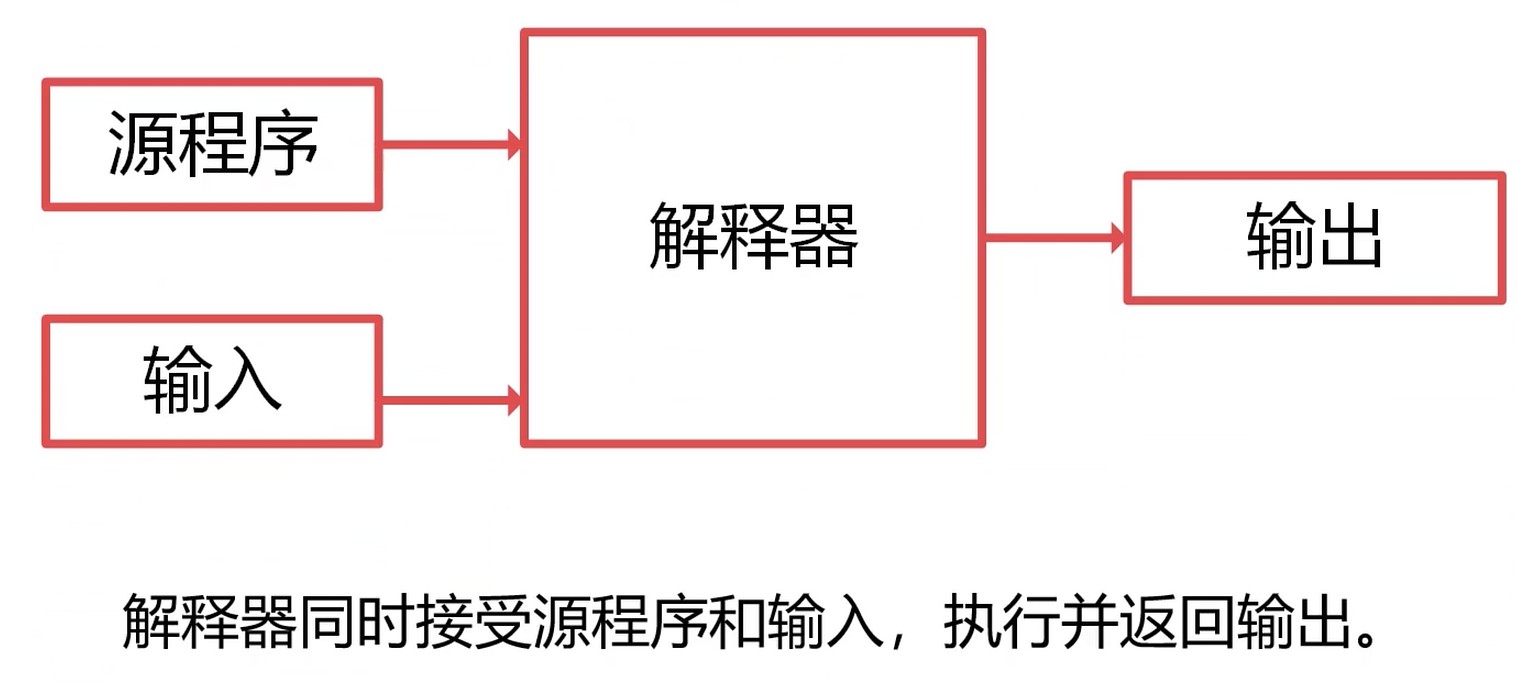
例如: 早期的 JavaScript 是解释执行的.
混合编译器
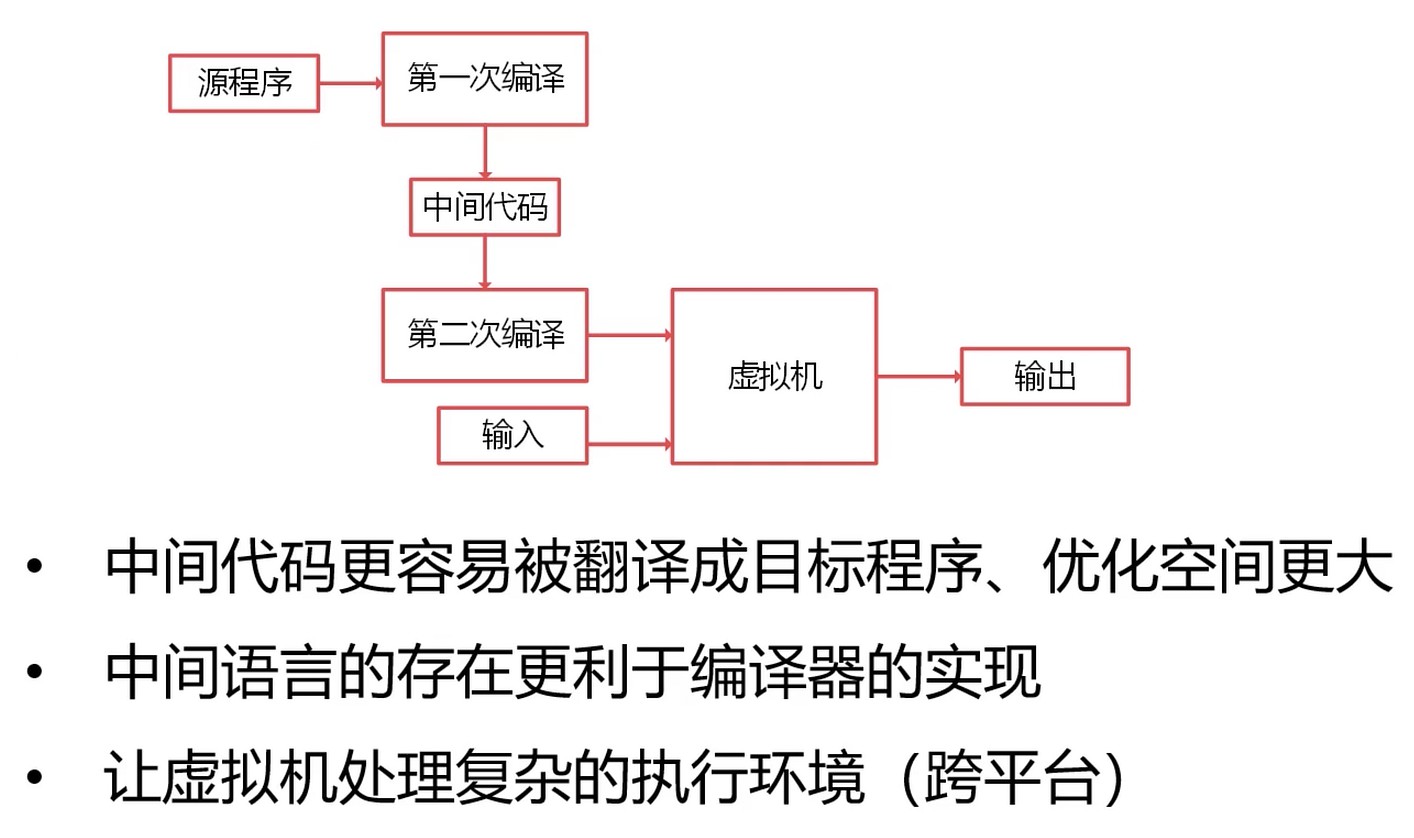
例如: java. 中间代码更容易被翻译成目标程序, 优化空间更大. 一份代码不用编译到不同平台.
即时编译器(Just-in-time compiler)
- 一种提高效率的方法, 中间代码不是直接执行, 而是先被编译成机器码再执行.
- 例如: Java的一个类型的字节码第一次执行时被编译成了机器码, 第二次执行的时候不需要再编译.
- 优点: 提高执行效率(50%以上)
交叉编译
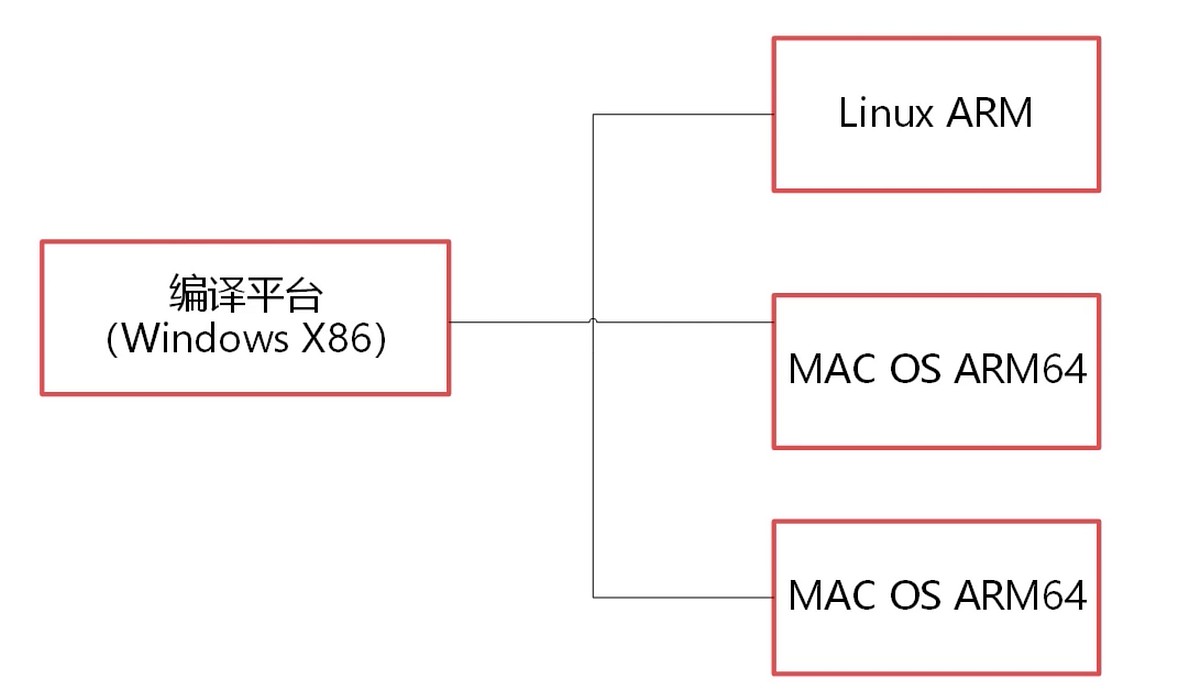
一个平台编译产生多个平台的可执行代码.
不同方式的优劣势
- 解释执行有性能问题, 但也异常灵活, 例如支持eval函数, 意味程序可以动态修改.
- 直接交叉编译技术难度高, 跨平台问题多. 一次编译多个包会有分发问题–产品问题.
- 虚拟化技术提供了更好的体验, 但是没有提供更好的性能(JIT完美解决了这一点, 平摊时间).
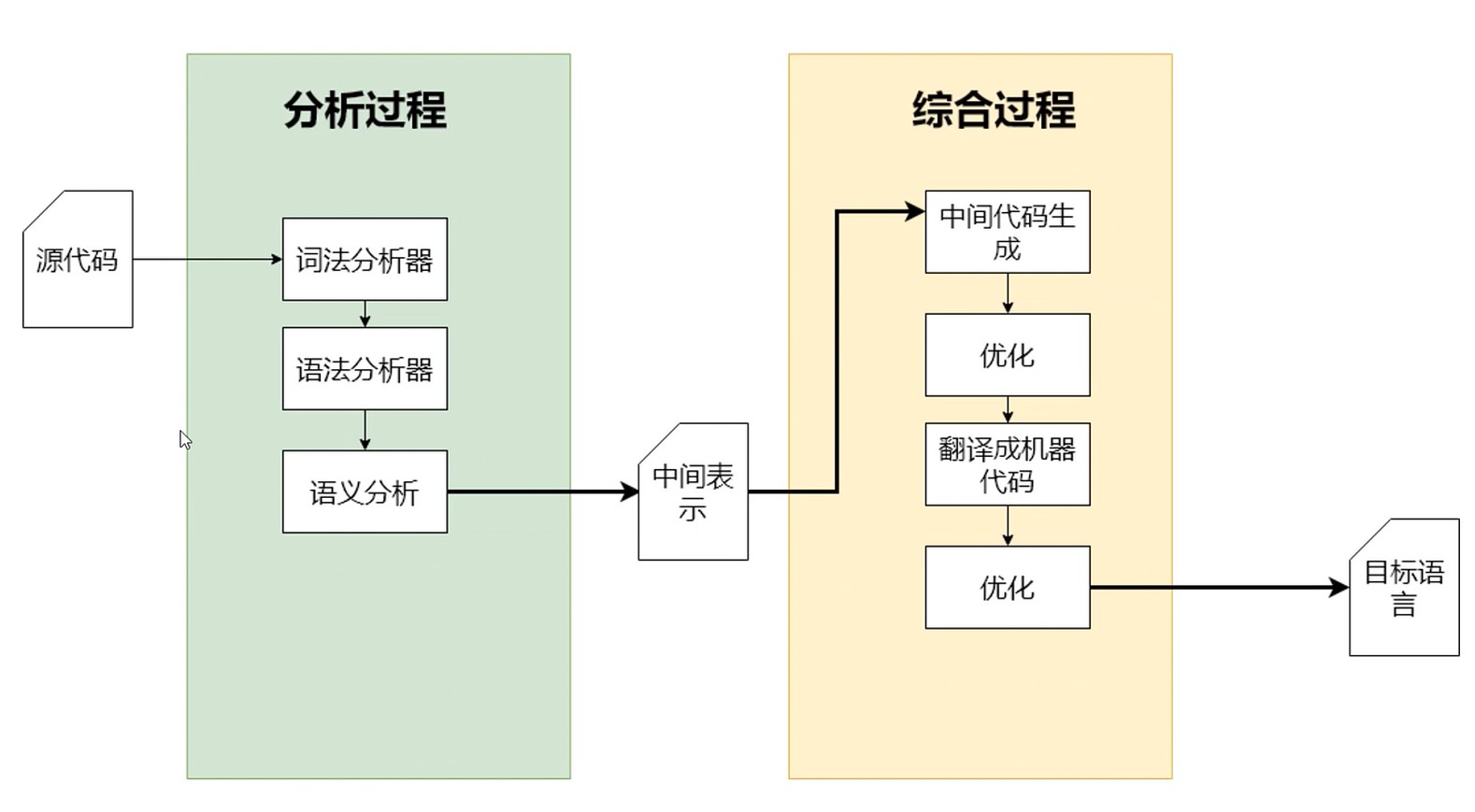
编译的流程
关注点分离
词法分析
一个分词断句+判断词性的过程.
语法分析
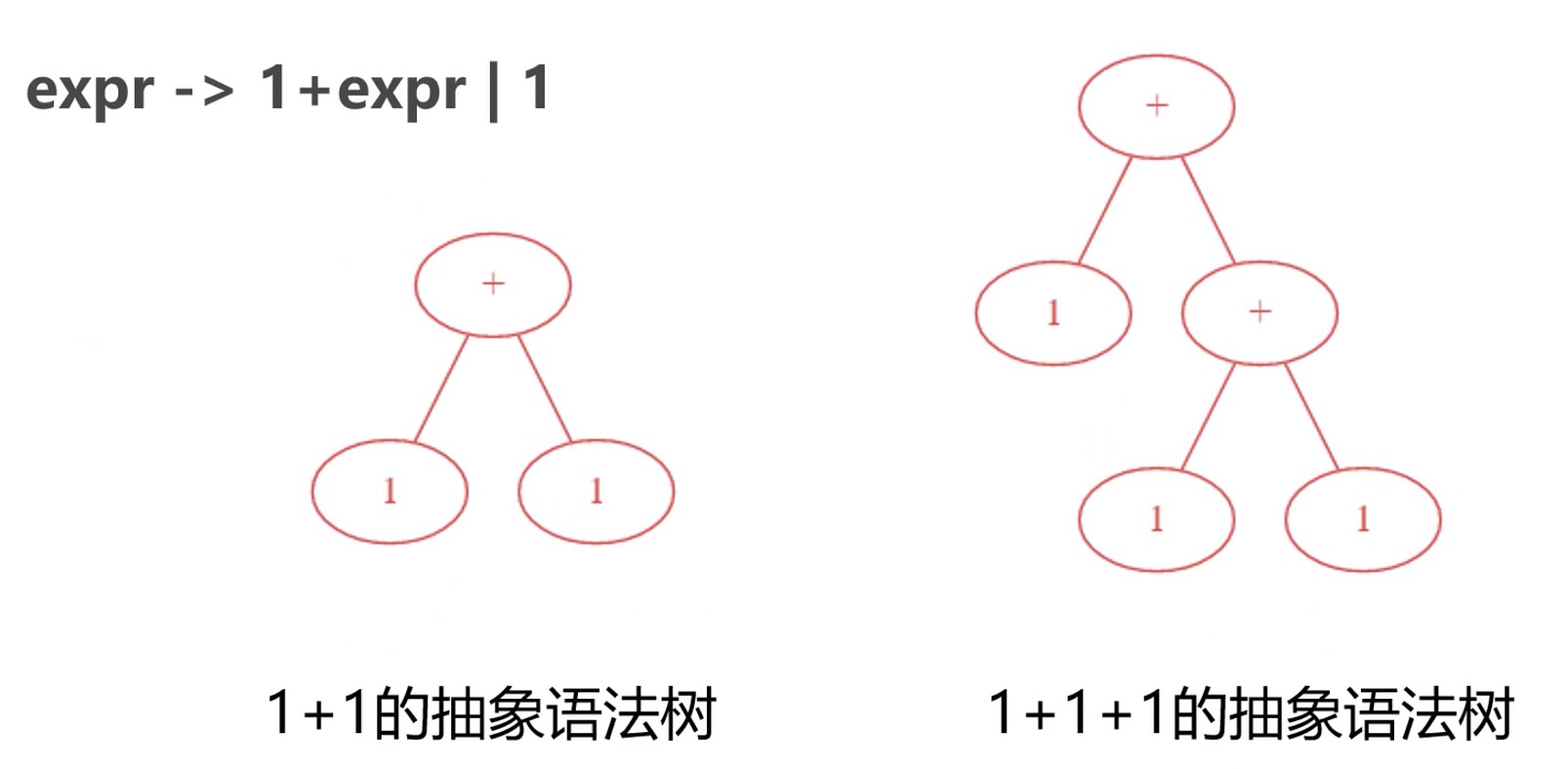
把词法分析结果转成抽象语法树(Abstract Syntax Tree, AST).

语法规则
语义分析
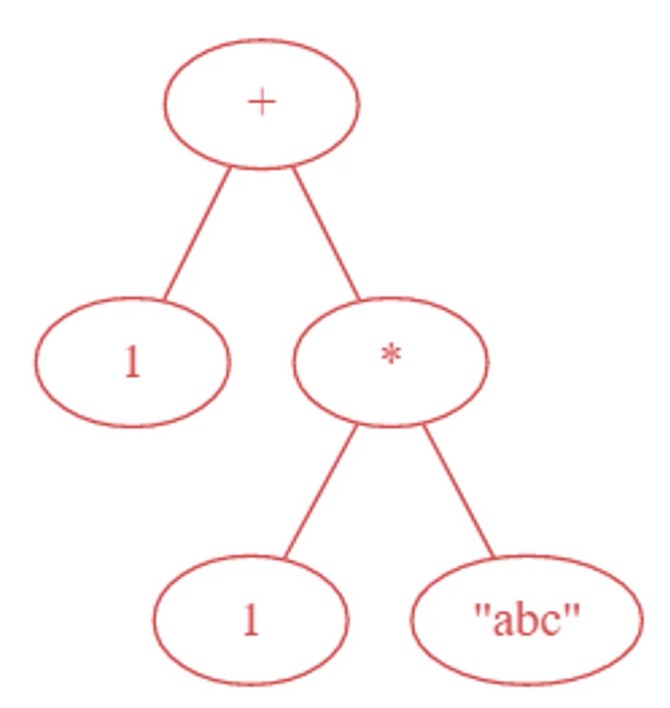
- 通过语义分析对抽象语法树进行语法检查非常重要
- 图中通过语法检查模块可以看到
*不能作用到整数和字符串
综合部分


运行时环境
- 有的编译器将代码编译成机器码, 按照操作系统的约定编译成一个应用, 运行成为操作系统的进程.
- 有的编译器将代码编译器中间代码(字节码, 三地址代码等), 然后在操作系统中启动一个虚拟容器(进程)来执行它们.
- JIT编译器一边执行中间代码, 一边编译它们.
编译器处理的两大过程

分层设计是最常见的软件架构
- 关注度分离, 每一层都有意义, 有产出, 可以独立使用
- 层足够强大, 每一层都用[优质的]算法数据结构, 架构技巧解决大量共性问题
词法分析详解
- 将字符流转换成符号流. 输入: 源代码(字符流) 输出: 符号流
- 词法分析过程类似语文的[词性标注], 每个符号是一个元组, 应该至少包括一个字符和一个词性描述.
符号(词法单元)
- 词法分析器的结果是一个个的符号, 英文 Token, 也叫 词法单元.
- 数学上符号是一个元组, 例如 整数 123 可以表示为(123, Integer).

实现词法分析器的基本接口
- 实现符号类型枚举
- 实现关键词字典
- 定义词法分析器的程序接口
实现流
流, 随着时间推移逐渐产生的可用数据序列. 流的使用者是不知道流有多少的.
类比: 工厂流水线上需要处理一个个的产品, 每个工人从流中拿起物件进行加工再放回去, 每个工人就是流的处理节点.
作用: 抽象出像工厂一样处理数据的标准过程.
流的标准接口
- 一般情况下, 流需要提供获取下一个数据的接口(next, hasNext方法).
- next 方法读取到一个数据后, 这个数据就相当于流过去了, 因此是无法重复读取的.
peek 和 putBack
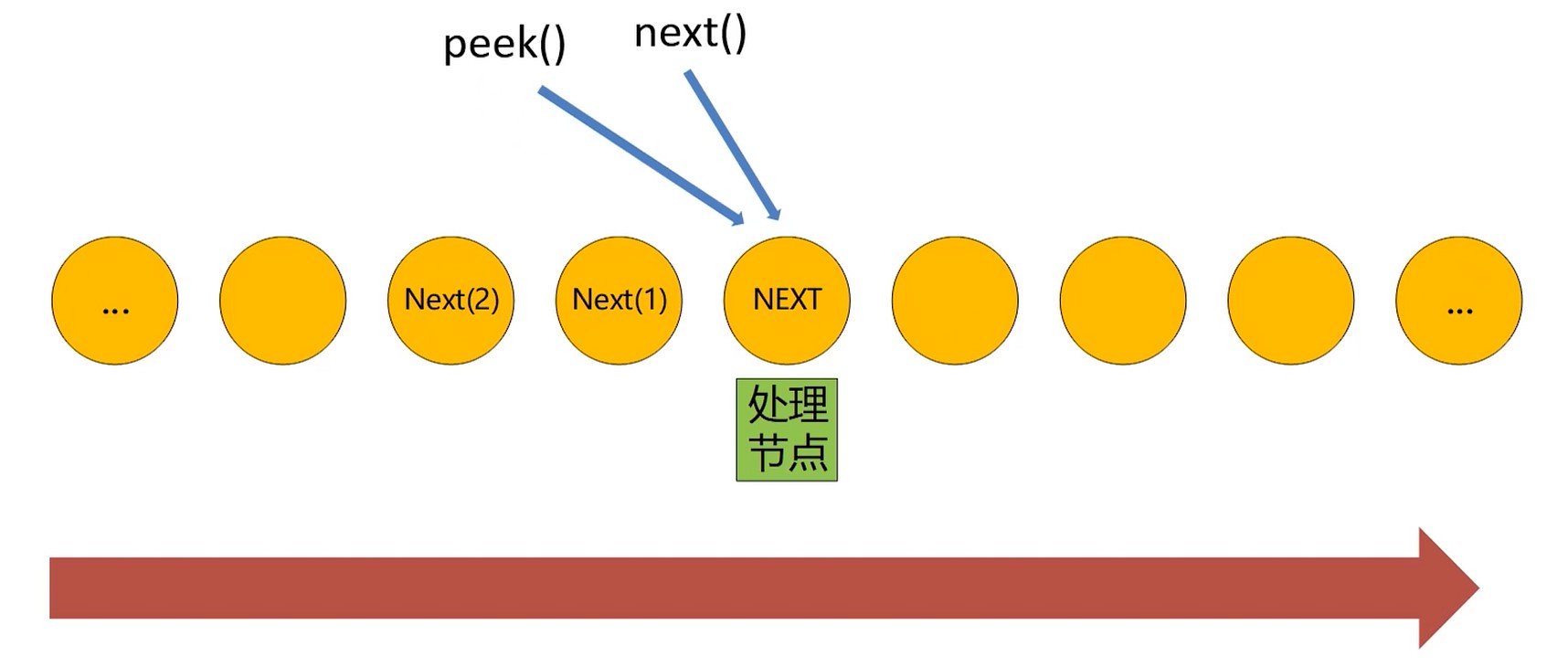
peek 获取元素, 但是没有消耗掉.
流的实现
- 词法分析器需要对流中字符执行 peek 和 putBack 操作
- 实现流的 peek 和 putBack 操作
词法和语法
- 词法就是构词的方法; 语法就是造句的方法
- 编译器制作过程中, 通常用 正则表达式 来表述词法; 然后用 状态机 来实现正则表达式
串和语言
- 字母表(alphabet): 语言L允许的所有字符(如: ansii, utf8)
- 串(string) 是语言L字母表中字母的一个有穷序列, 通常用希腊字母代表空串
- 不可能所有的串都是语言支持的, 因此通常用一些约束规则来描述串, 其中就有正则表达式
词法分析器的目标
- 给定程序语言(L)以及所有L支持的词汇, 从中找出这些词汇并为他标注词性.
- 如果源代码中有语言(L)不支持的词汇, 报错并提示用户.
正则表达式
- 用于正则语言(一种形式语言)的词法, 用一串字符串来描述正则语言L接受哪些词语, 而不需要理解这些词语.
- 在Unix采用后被大众认可(grep, sed等).
- 正则语言可以被 确定的, 有限状态的 自动机 理解.
正则描述词法
可以使用正则表达式描述一类词法单元(符号)
- 关键词 – if|else|return|for…
- 整数 – [+-]?[0-9]+
- 运算符 – +|-|*|/|^|||
区分关键词和变量名
- 关键词和变量名都以字母下划线开头, 但又有所区别
- 正则表示: [_a-zA-Z] [_a-zA-Z0-9]*
- 状态机描述. 圆: 状态. 边: 状态转换函数.
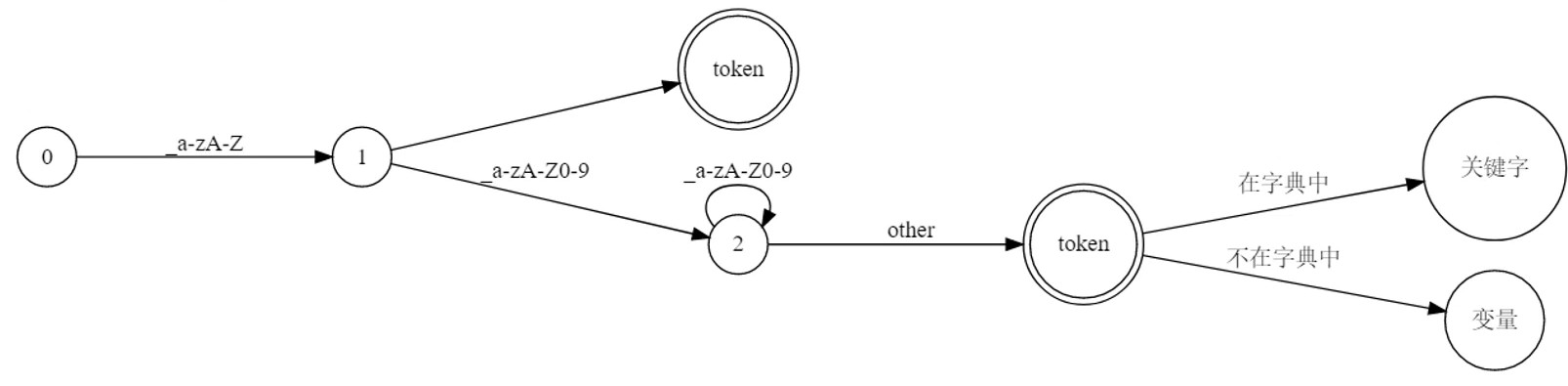
给定一个输入, 状态转换是确定的.
状态的个数是有限的.
实现思考
- 各个语言都提供正则表达式, 从一个字符串(源代码)中提取字符串容易, 但是词法分析过程需要提取大量字符串.
状态机提取词语
有穷状态机实现词法提取.
- 提取关键字和变量名
- 提取字符串
- 提取操作符
- 提取数字
预读, 流过去就不回来了, 所以要用到 lookahead.
多个状态机合并成一个词法分析器
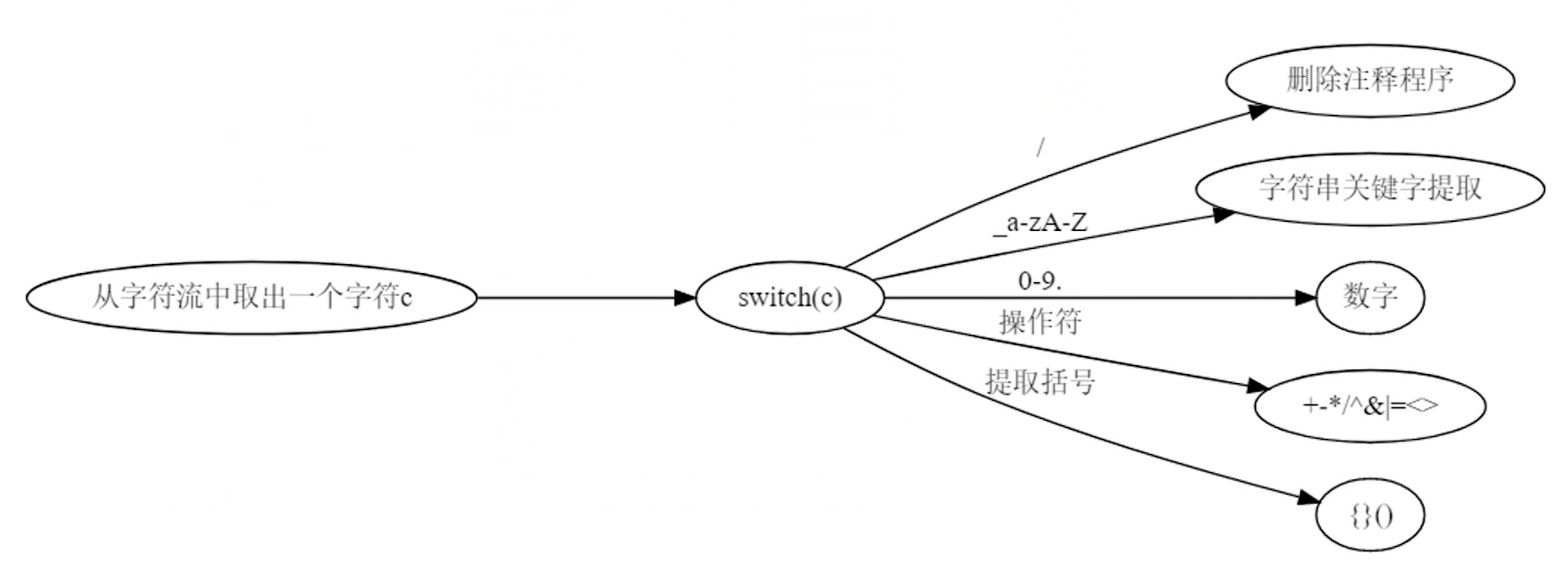
判断过程是 lookahead 的(向前看).
测试案例
- 单元测试(unit testing), 对软件中最小的组成部分进行测试
- 集成测试(integration testing), 对子系统, 完整系统进行测试
单元测试: 任何情况下
集成测试: 测试覆盖率 80~90%, 且设计合理
集成测试出现 bug 怎么处理? 返回增加单元测试!
如果程序没办法单元测试? 重构程序确保可以进行单元测试.
语法分析详解
数据结构: 用特定得方法组织数据, 从而使得他们可以被高效地使用.
跳跃结构的比喻: 字典, 数据地址到数据的映射.
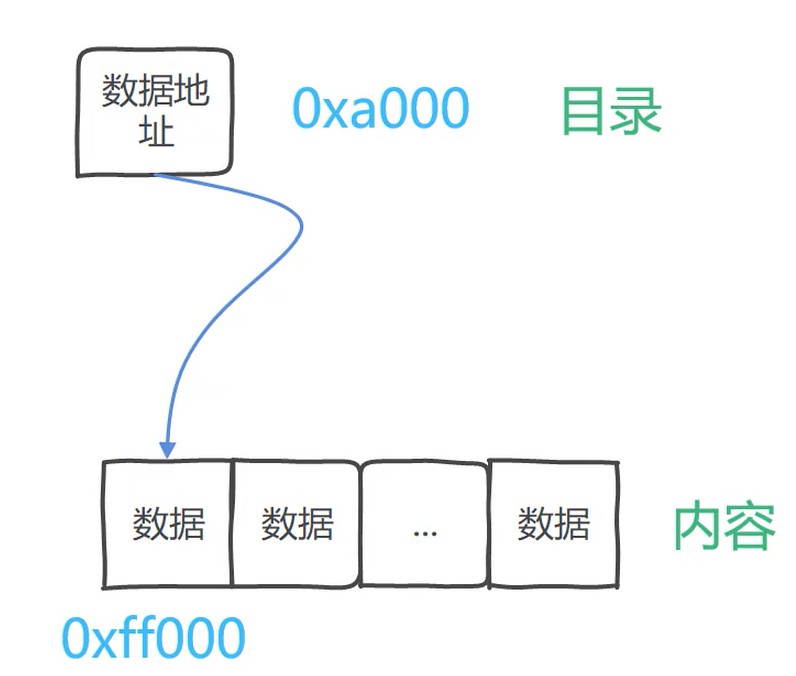
数组: 内存中连续的存储空间.
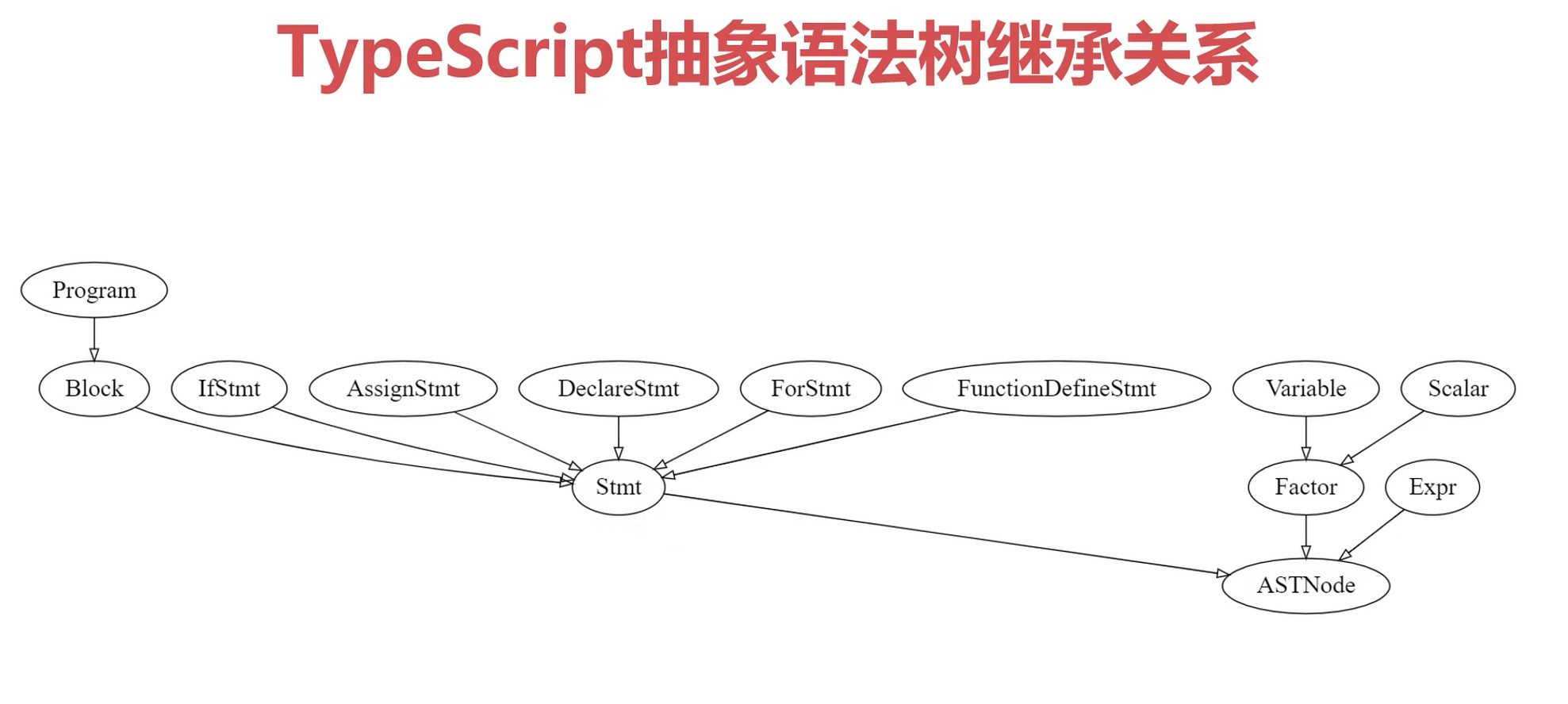
树和抽象语法树
链表和树
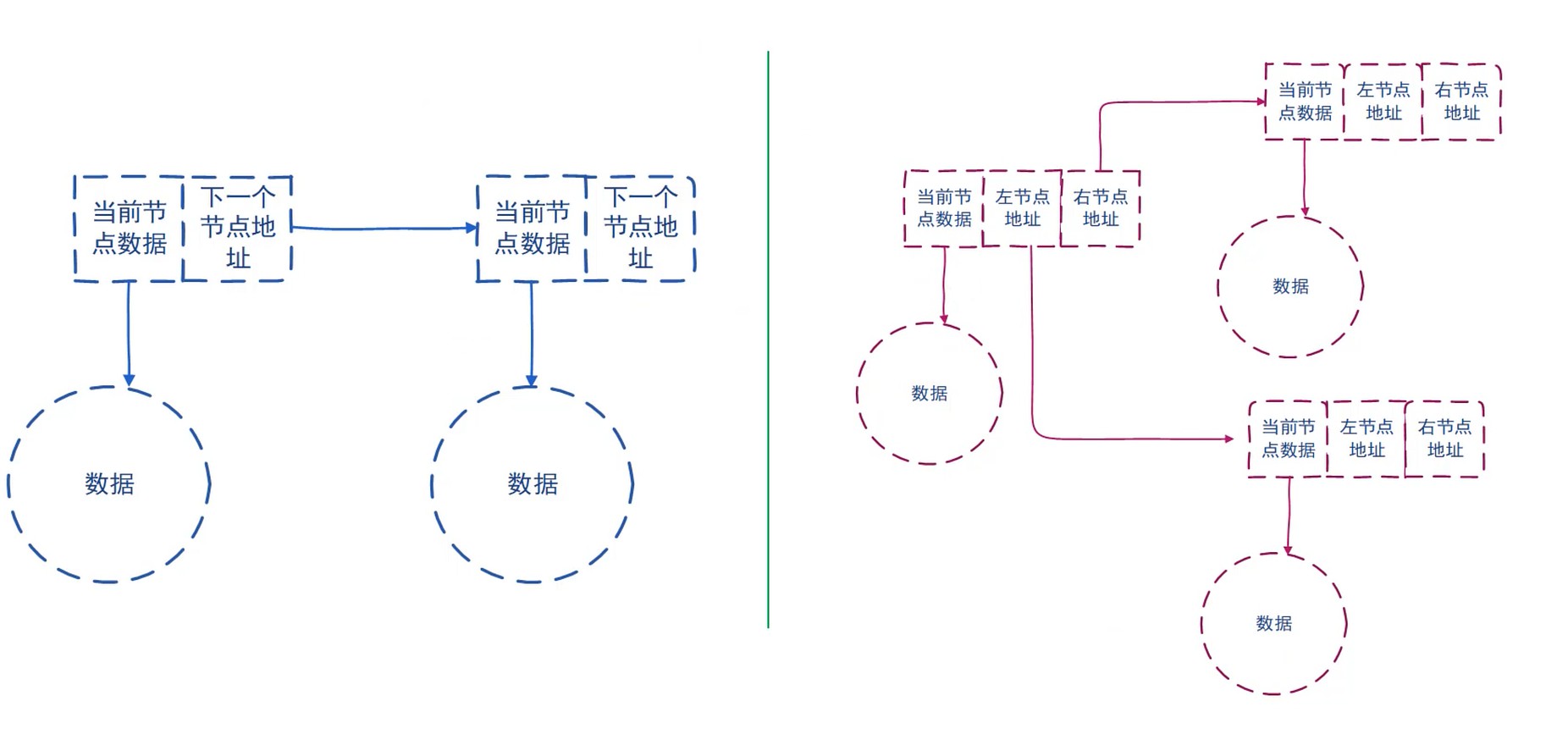
链表是一种特殊的树, 每个节点只有一个子节点.
树和图
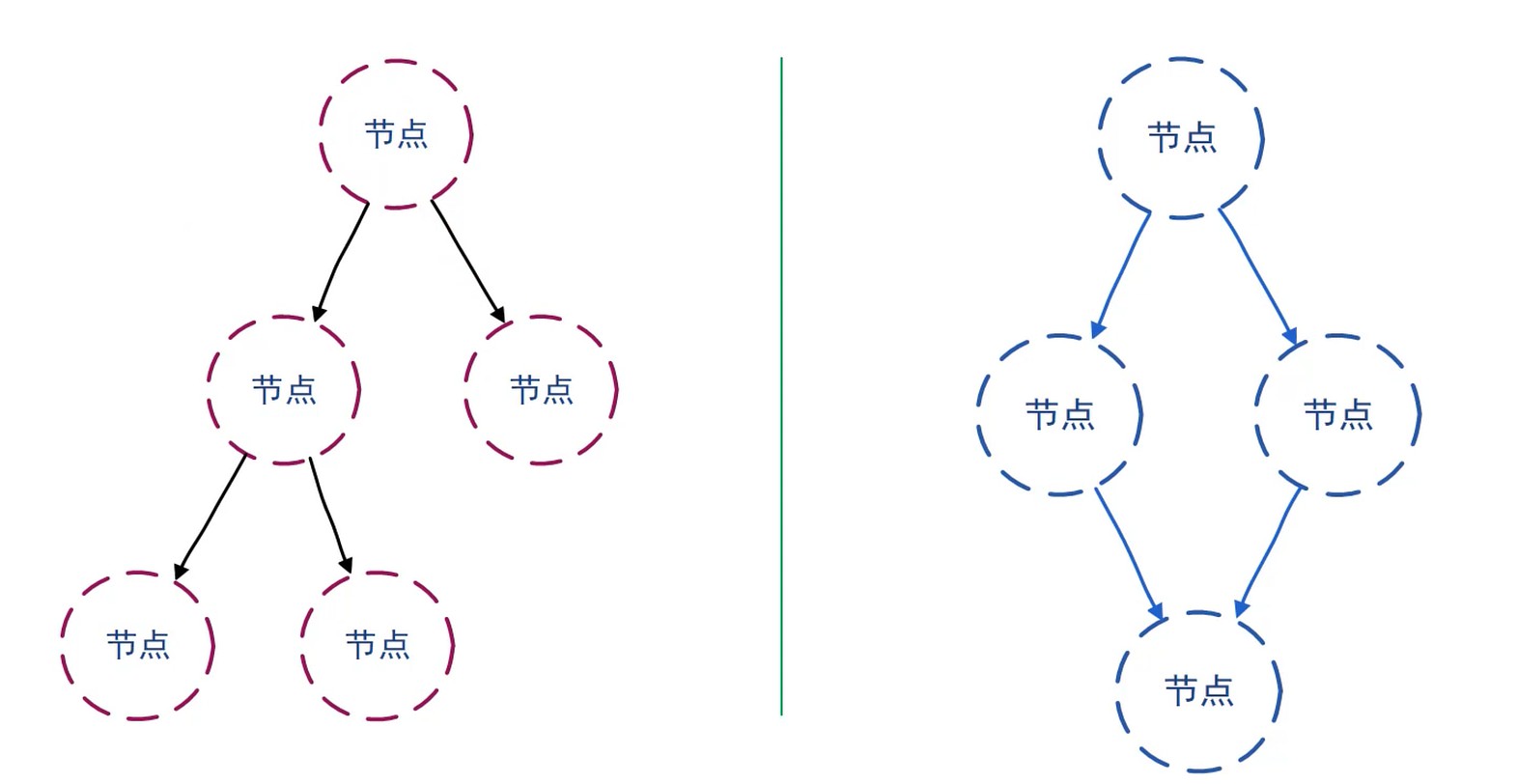
图是特殊的一种树.
图的遍历
决策模型
集合是一种抽象的数据类型. 例如: 栈(先入–push()后出–pop())
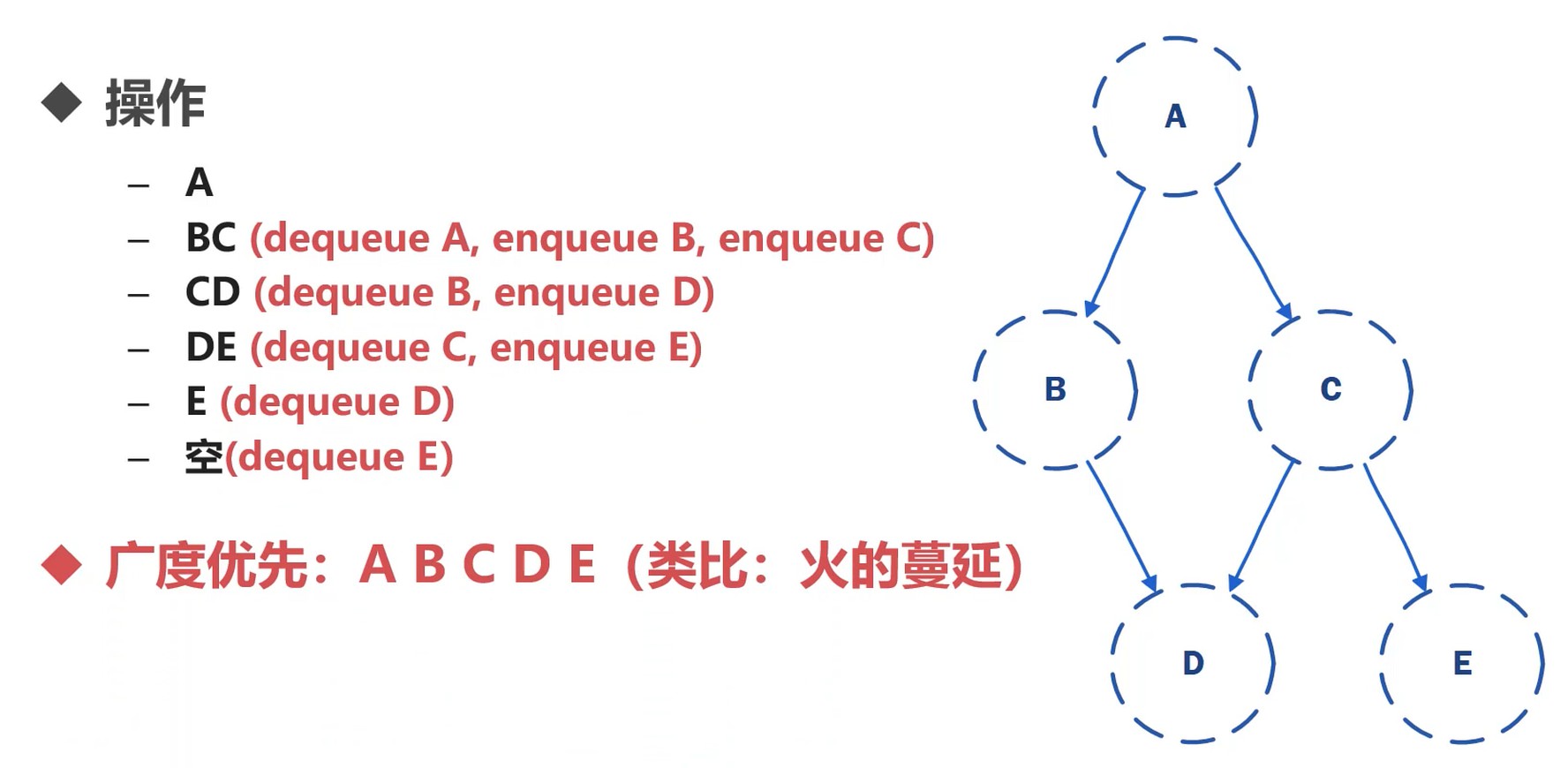
队列, 先进先出
B可以找到D.
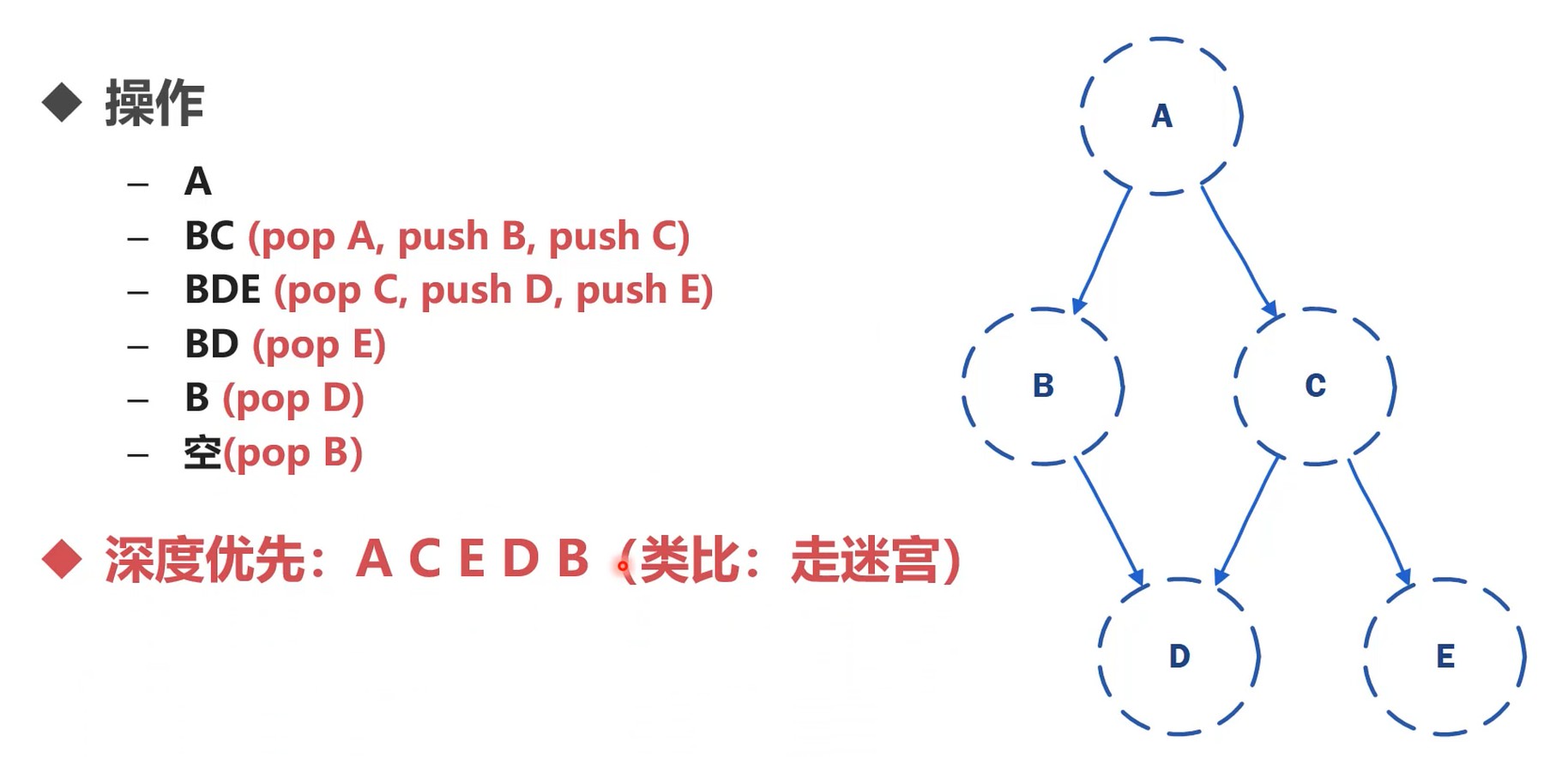
递归函数底层使用了栈, 所以是深度优先.
函数的调用是先把参数压栈.
子叶: 没有子节点的节点
根节点: 没有父节点的节点.
树的高度: 节点到根节点的最短距离.
抽象语法树
理解事物的本质就可以进行抽象了.
- 源代码结构的抽象
- Abstract Syntax Tree, 也称作分析树(Pase Tree)
- 抽象: 隐藏细节.
- 树
- 每个节点是源代码中的一种结构(语句块, 表达式)
- 每个节点都携带了源代码中的一些关键信息
- 每个节点的字节点代表着语言上的关系
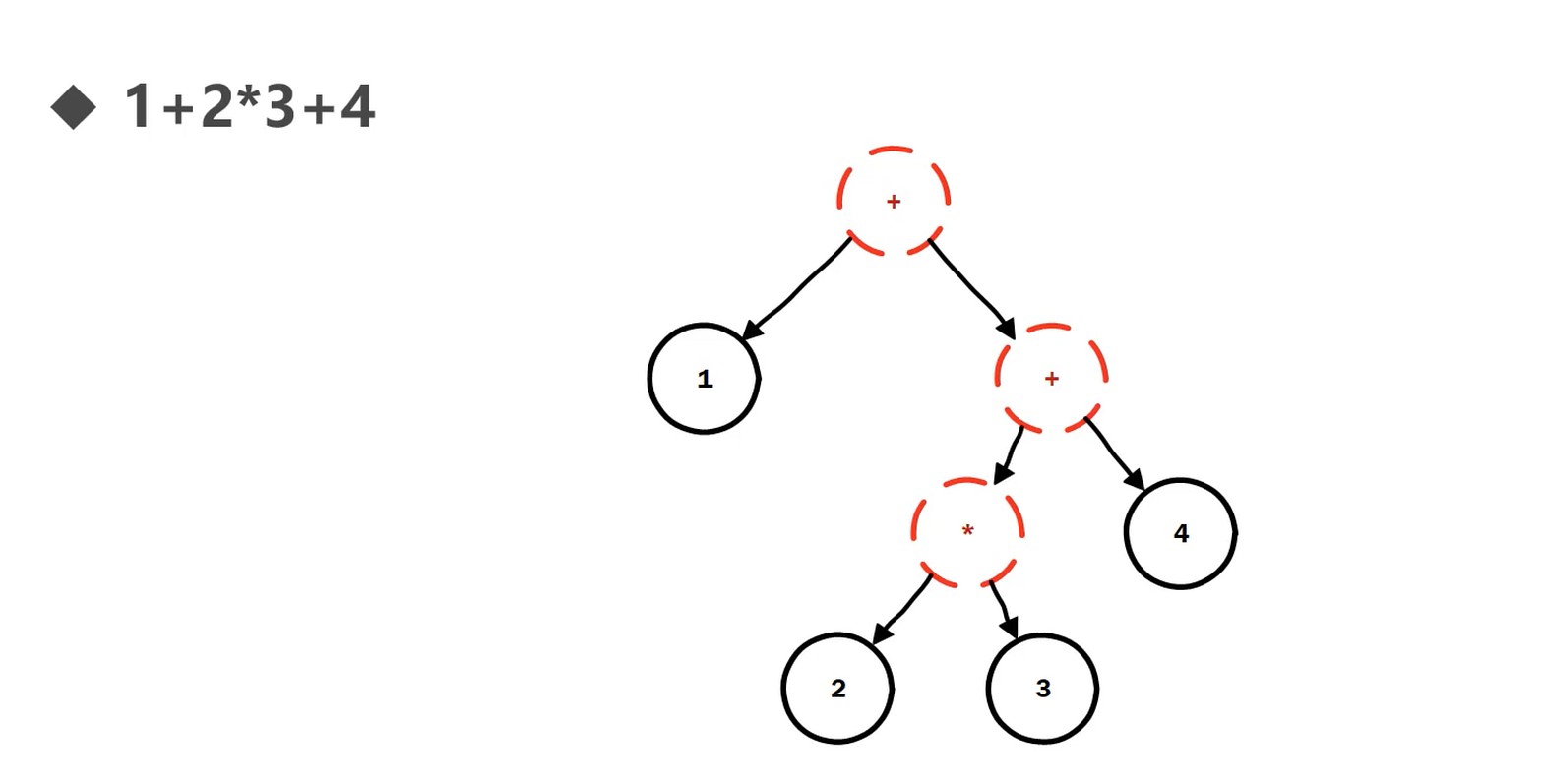
语法分析器
- 语法分析器(parser): 根据语法规则, 将符号(词法单元, lexeme, token)流, 转换成抽象语法树.
- 类比: 中文分析句子成分.
和自然语言不同, 编译器只能识别[上下文无关文法]
一个文法是上下文无关, 也就是说, 不需要理解这个语言, 给定任意这个语言的句子, 可以得到一个合理的抽象语法树.
通常用产生式描述语法规则.
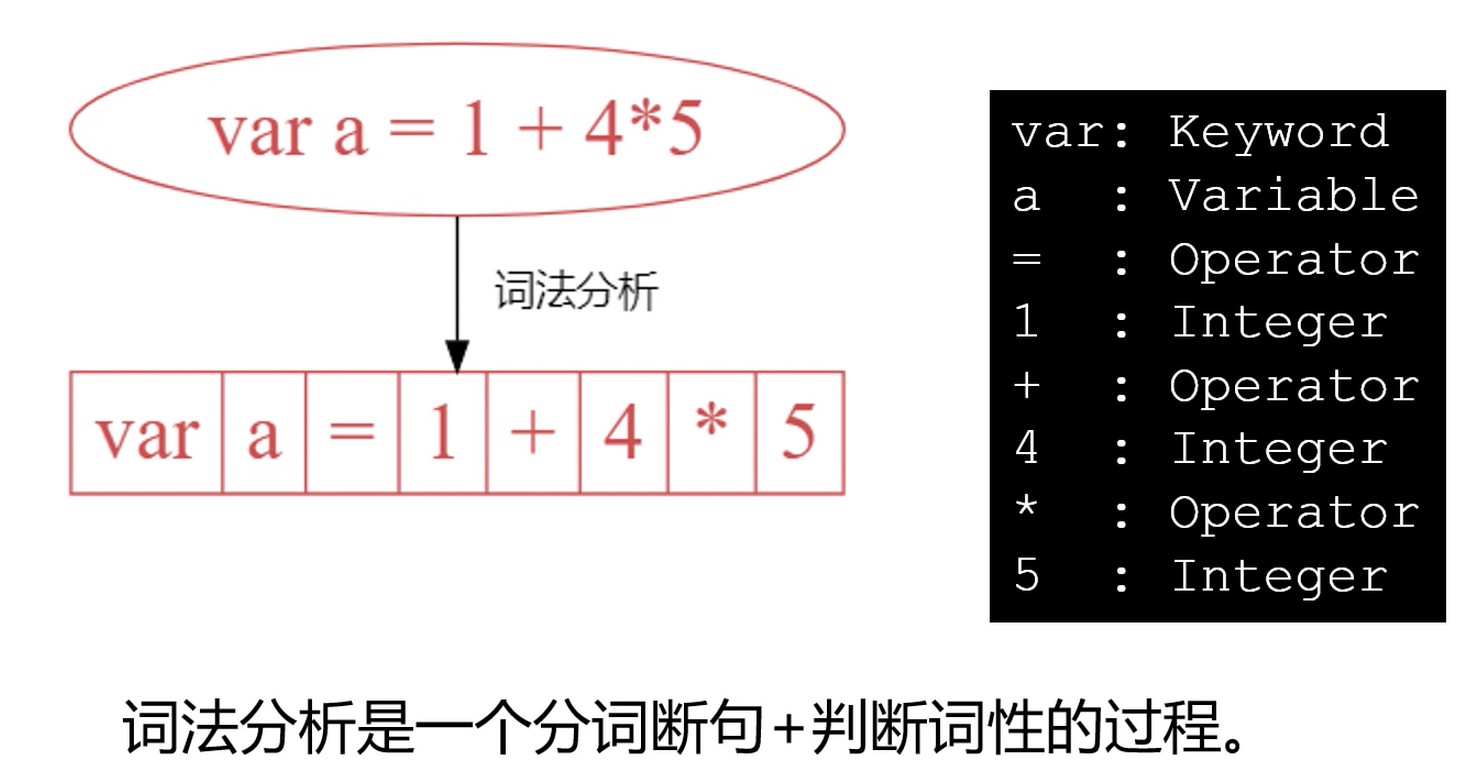
产生式: Expr -> Expr + 1 | 1 读作 Expr 可以推导出 Expr + 1 或 1. ( -> 解析成推导出)
上面的 Expr 是非终结符, 1 是终结符, 终结符对应词法单元.
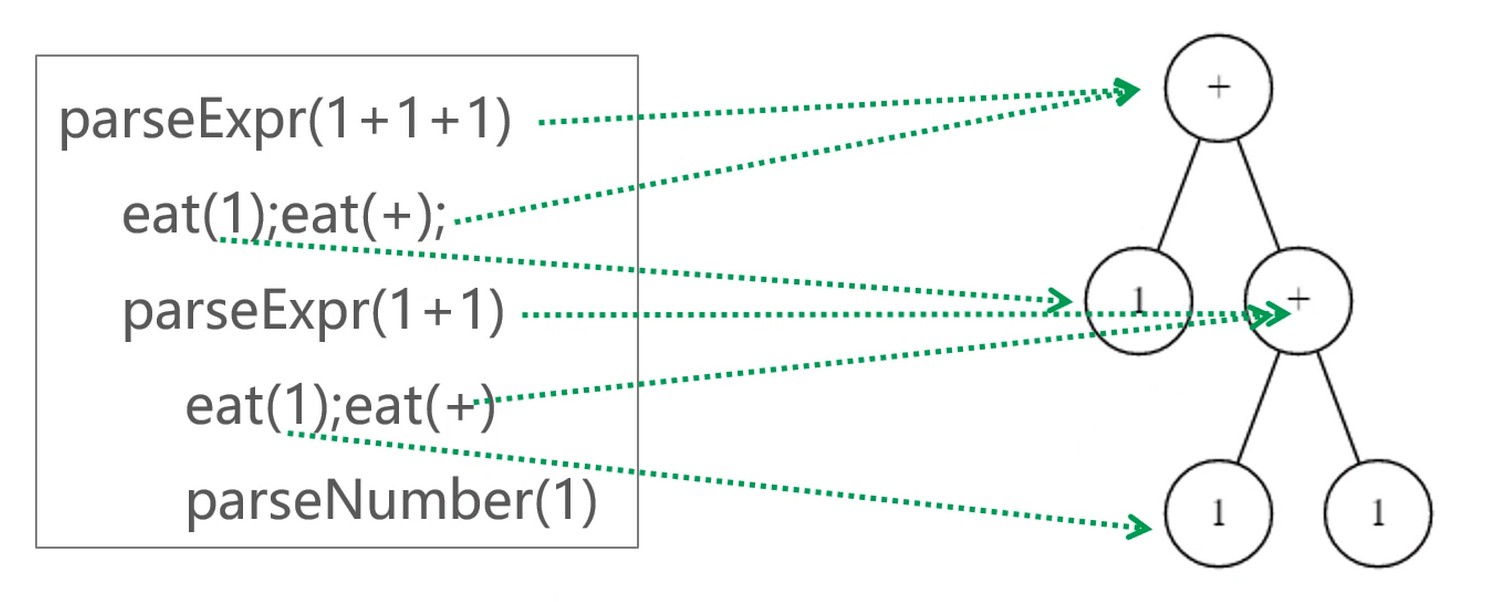
递归法求抽象语法树
- Expr -> Expr + 1 | 1 可以拆分成两步
- 非终结符(递归)函数: parseExpr(生成一个非子叶节点)
- 终结符: parseNumber(生成一个子叶节点)
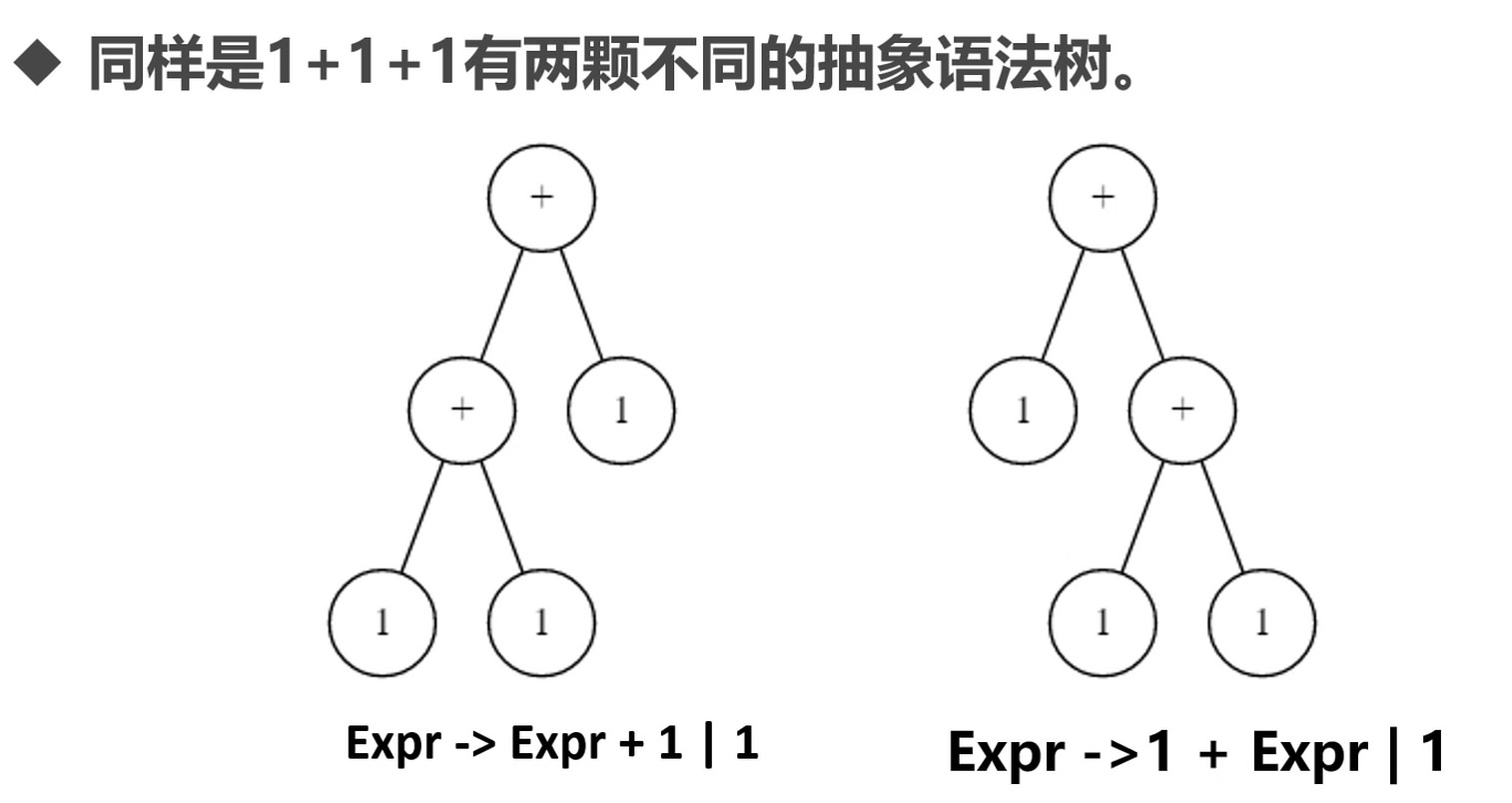
左递归问题如何解决?
转换成 右递归形式 : Expr -> 1 + Expr | 1.
例如

生成抽象语法树的过程
左结合和右结合. 两棵树是互为翻转的关系. 一个是左边是表达式, 一个是右边是表达式. 一个是先算左边, 一个是先算右边.
高阶能力是很多基础能力的拼接, 程序就像搭积木一样.
程序如果写难了, 那就是写错了.
左递归和优先级
左递归: 从左到右推导.
无法使用自顶向下递归法.

∈代表空.
换成右递归的话, 每次都可以减少一个字符, 从而减少符号流, 从而得到抽象语法树.
- Expr -> Expr + 1 | 1 求解左递归
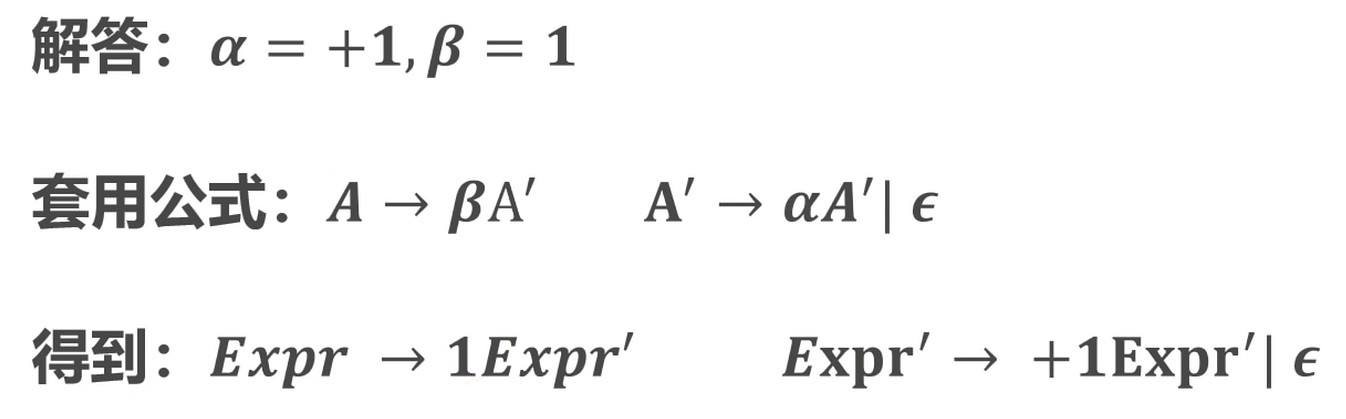
总结: 一般情况下的左递归处理

例题
下列产生式
- E -> E + E | E - E | d
- d -> 0 | 1 | 2 | 3 | 4 | 5 | 7 | 8 | 9
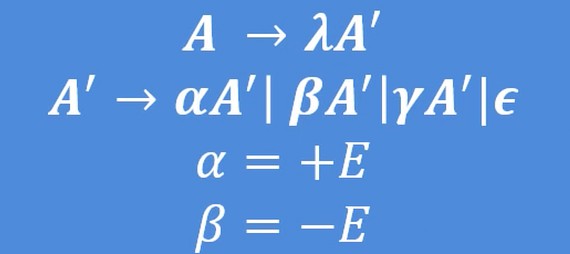
λ 代表 d.
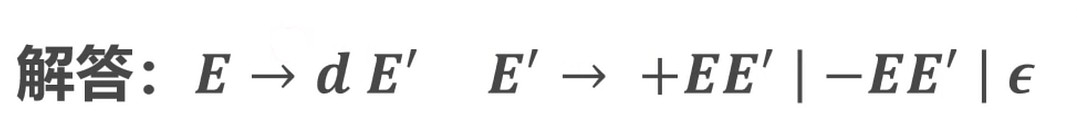
转换成递归向下
程序的优先级
按照上面的方式, 每个表达式都是同级的.
例如: 1 * 3 + 2

使用两级产生式解决优先级问题.


多级优先级问题(6级, 从低到高)
- & | ^
- == != > < >= <=
- + -
- / *
- << >>
- () ++ – !
从特殊到一般


表达式解析
- 优先级表
- 按照优先级解析表达式
要点
- 采用递归向下方法, 每个产生式的非终结符号对应一个函数
- E() 表达式, E_() 左递归转换的产出, U() 一元表达式, F() 因子
- 产生式的关系对应一个高阶函数
- 合并关系, 如: E() E_() -> combine(() -> E(), () -> E_())
- 竞争关系, 如: E | F -> race(() -> E(), () -> F())
递归很抽象–也需要抽象的思考
递归从思考到表达是很高效.
如果平时写业务的时候, 很少使用递归, 那么可以从侧面反应出效率是很低的.
表达式树的验证
- 后序表达式
- 根据后序表达式验证正确性

后序遍历可以用来求值, 使用栈的特性, 先入后出
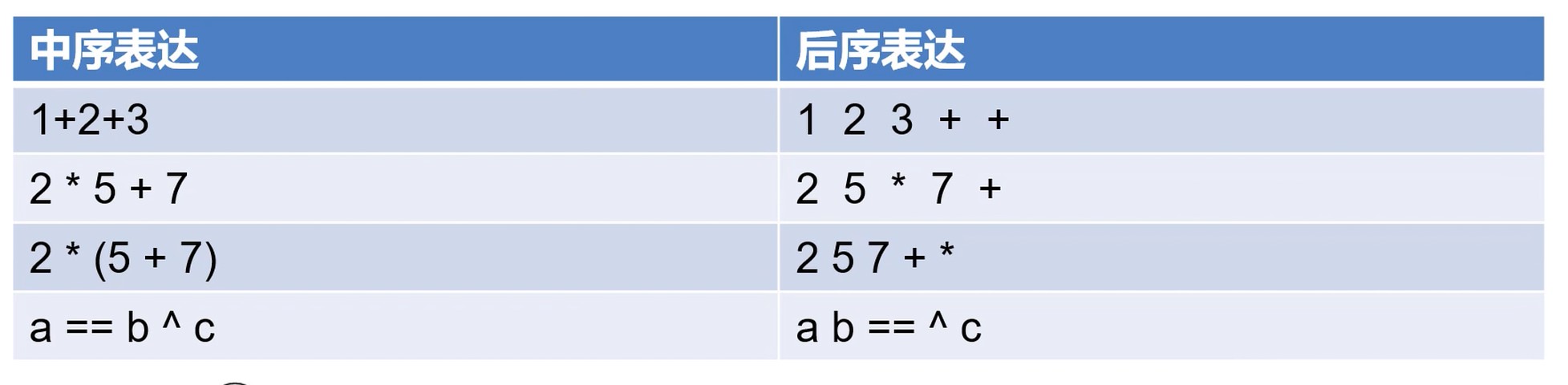
通常用的表达式时表达式数的中序遍历的结果.
后序表达式时表达式树的后序遍历结果.
语法分析器的整体
定义语句块和语句
程序是抽象语法树的根节点.
Program -> Stmts -> Stmt Stmts | ∊
Stmt -> IfStmt | WhileStmt | ForStmt | Function … | Block
Block -> { Stmts }
从顶向下的结构
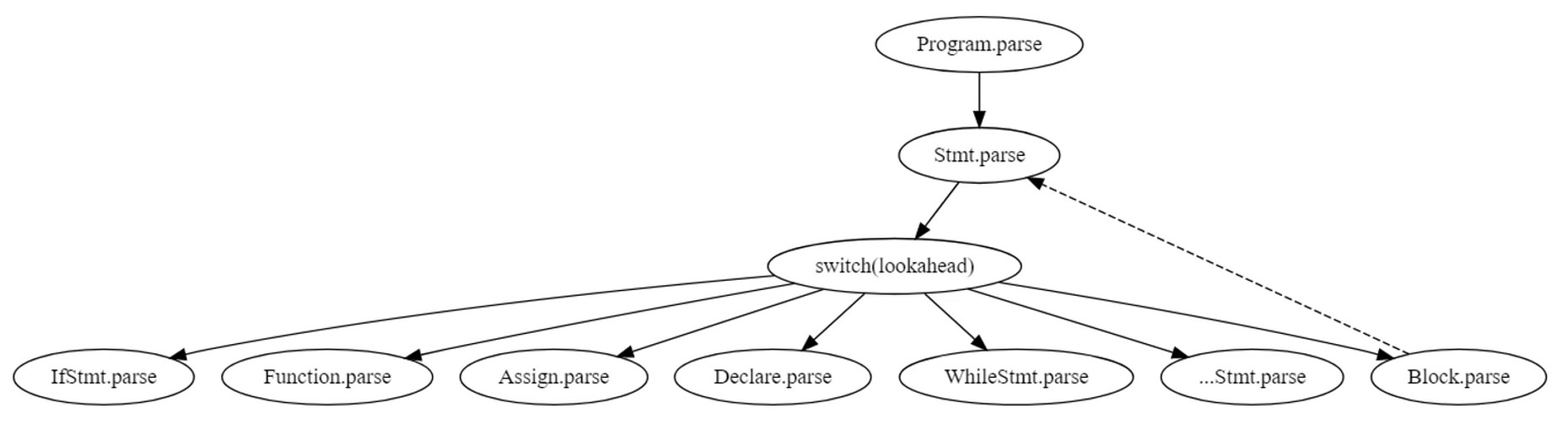
通过往前看一个符号, 判断是什么 Stmt
考虑公共前缀

简化后
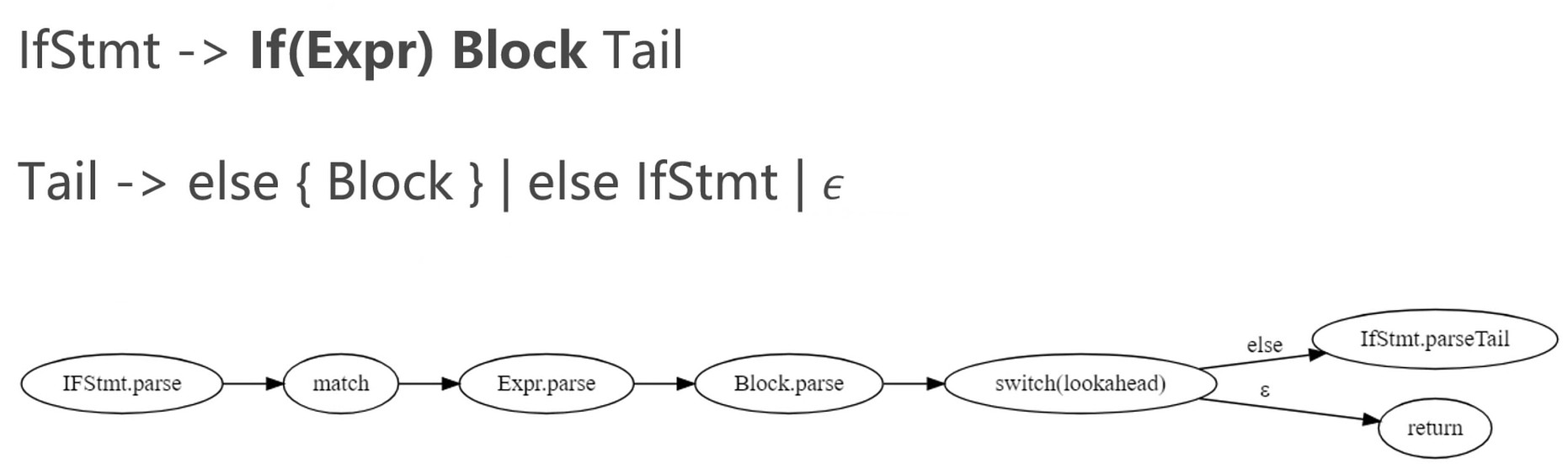
Function 定义
整体实现
- 定义和赋值
- Program
- Block
- Stmt/IfStmt/FunctionStmt
- 测试
没有底层的东西是不健壮的!!
软件重构
- 对软件内部结构进行改造
- 使其更容易理解
- 修改成本更低
必须: 自动化测试作为基础.
构造其实就是分配内存.
函数式编程最怕调试.
循环引用: Stmt 引用 IfStmt, IfStmt 引用 Stmt
js 是一行一行执行的, 而不是在抽象成语法树整体形成之后再去分析代码之间的关系.
递归复习
要了解递归, 必须了解递归.
周而复始, 重复自己.
典型的递归问题–汉诺塔问题
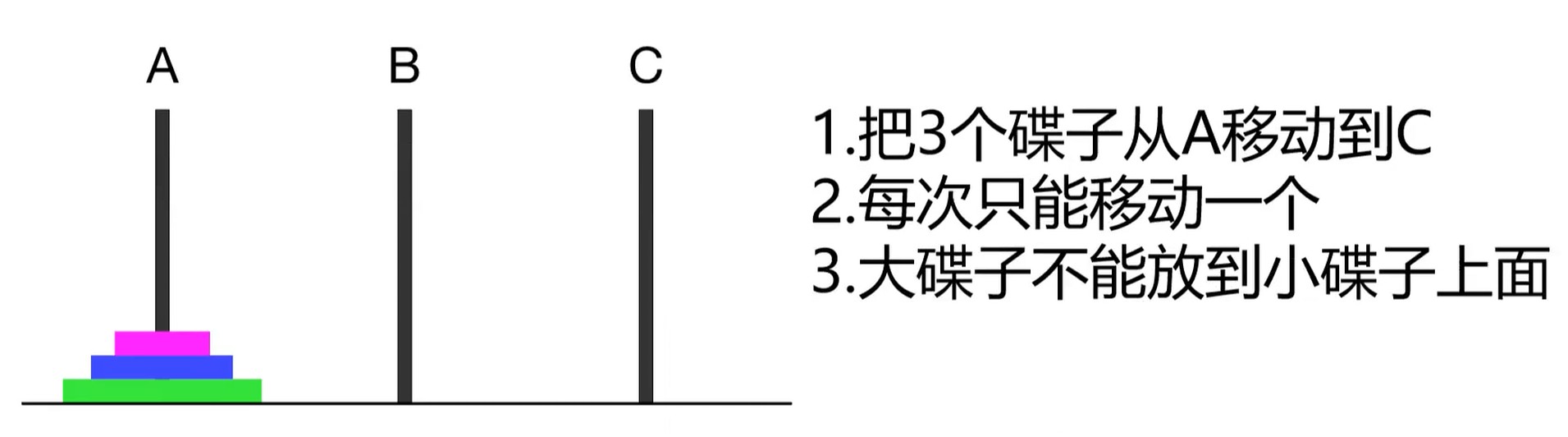
重点: 不要陷入细节思考
- 抽象出递归节点(递归函数)
- 抽象出终止条件
- 递归式一种决策模型
- 每次做一个决策
决策模型1
决策树–穷举
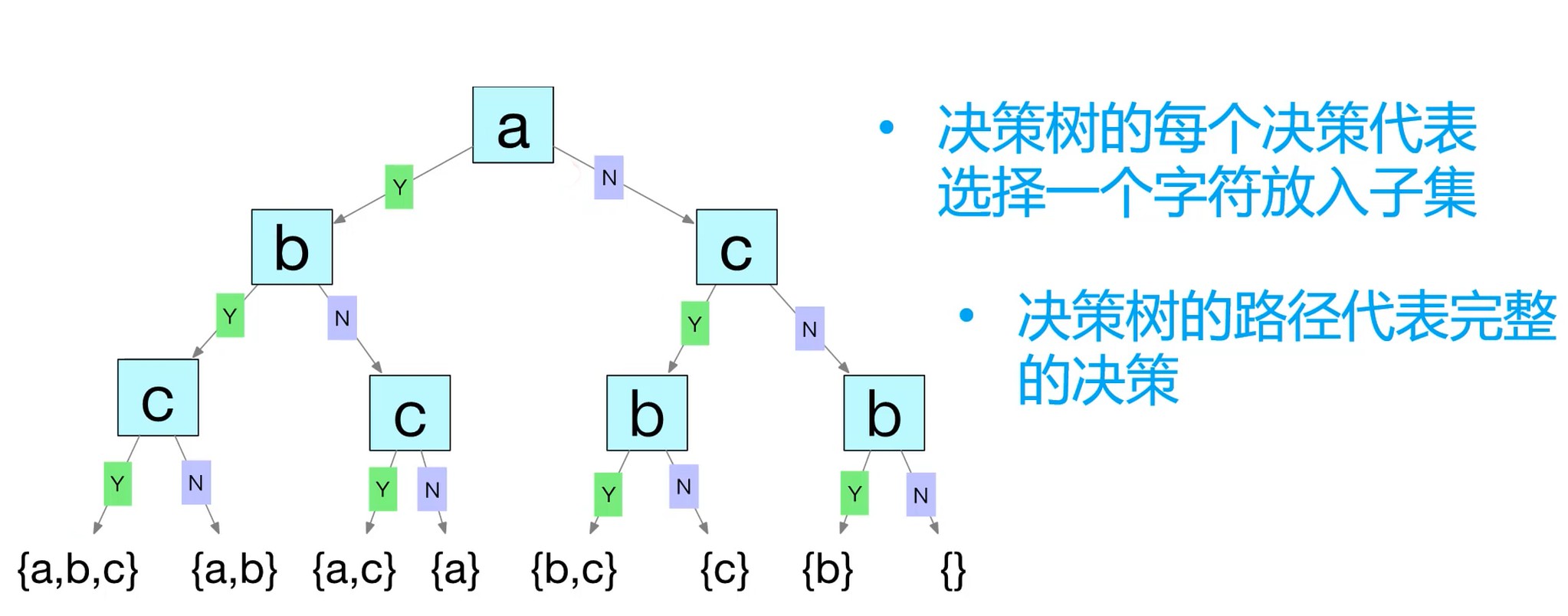
- 决策树的每个决策代表选择一个字符放入子集
- 决策树的路径代表完整决策
决策模型2
全排列
求字符串abc的全排列. 3的阶乘, 6种.
思路: 将枚举问题转换成决策树遍历问题
枚举: 一一列举, 是一个可以被列举的有穷集合. 以及不可变性, 每次列举出来的内容都是不一样的.
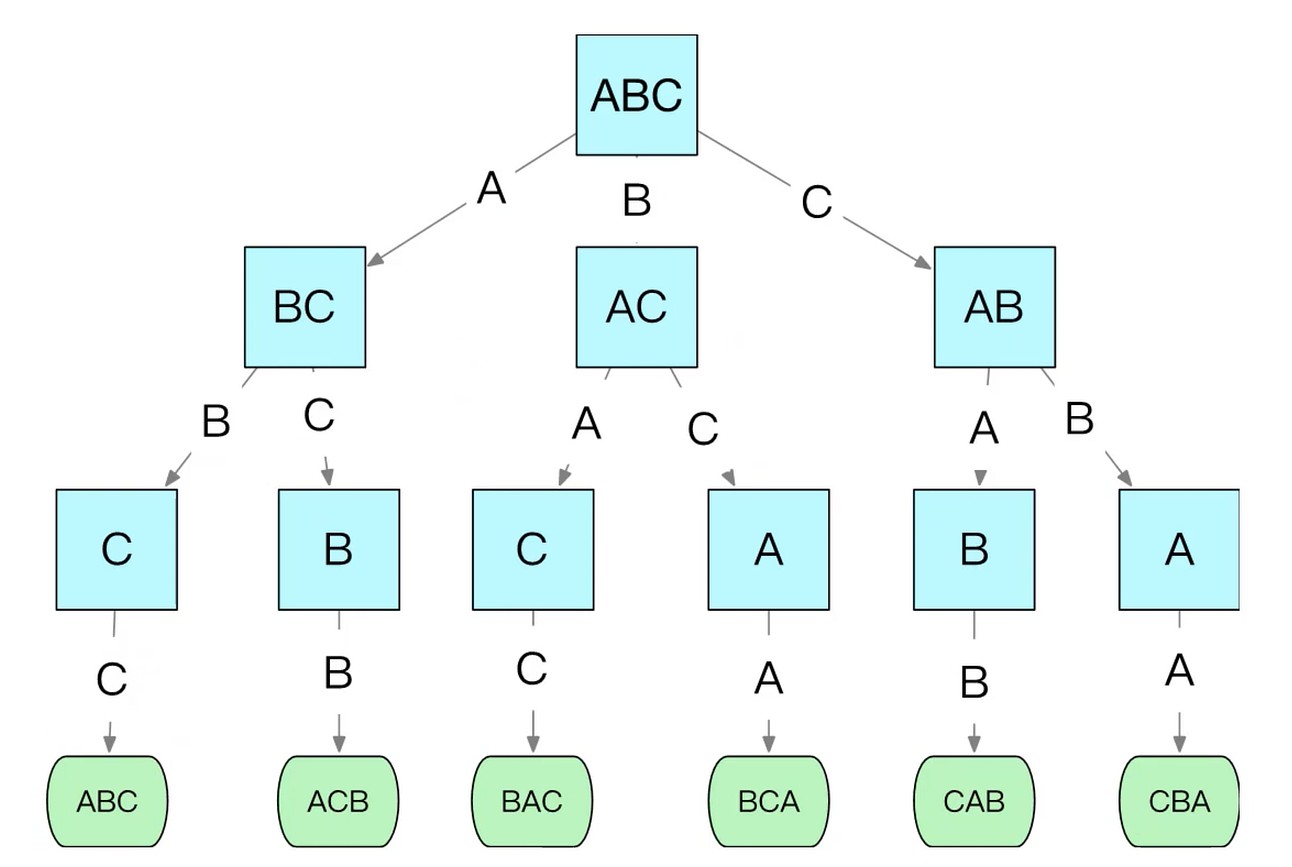
决策模型转成程序
- 决策节点: 递归函数
- 到达目标: 递归终止条件
func permutation(str) {
if(len(str) == 0){return ""}
// 遍历每一种决策的可选项
for(var i=0; i<len(str); i++){
// [:i] 从第0个位置取到第i个位置, 不包括i
// 也就是说, 下面的语句把 i 从字符串中去掉了
yield str[i] + permutation(str[:i]+str[i+1:])
}
}
回溯算法
Backtracking
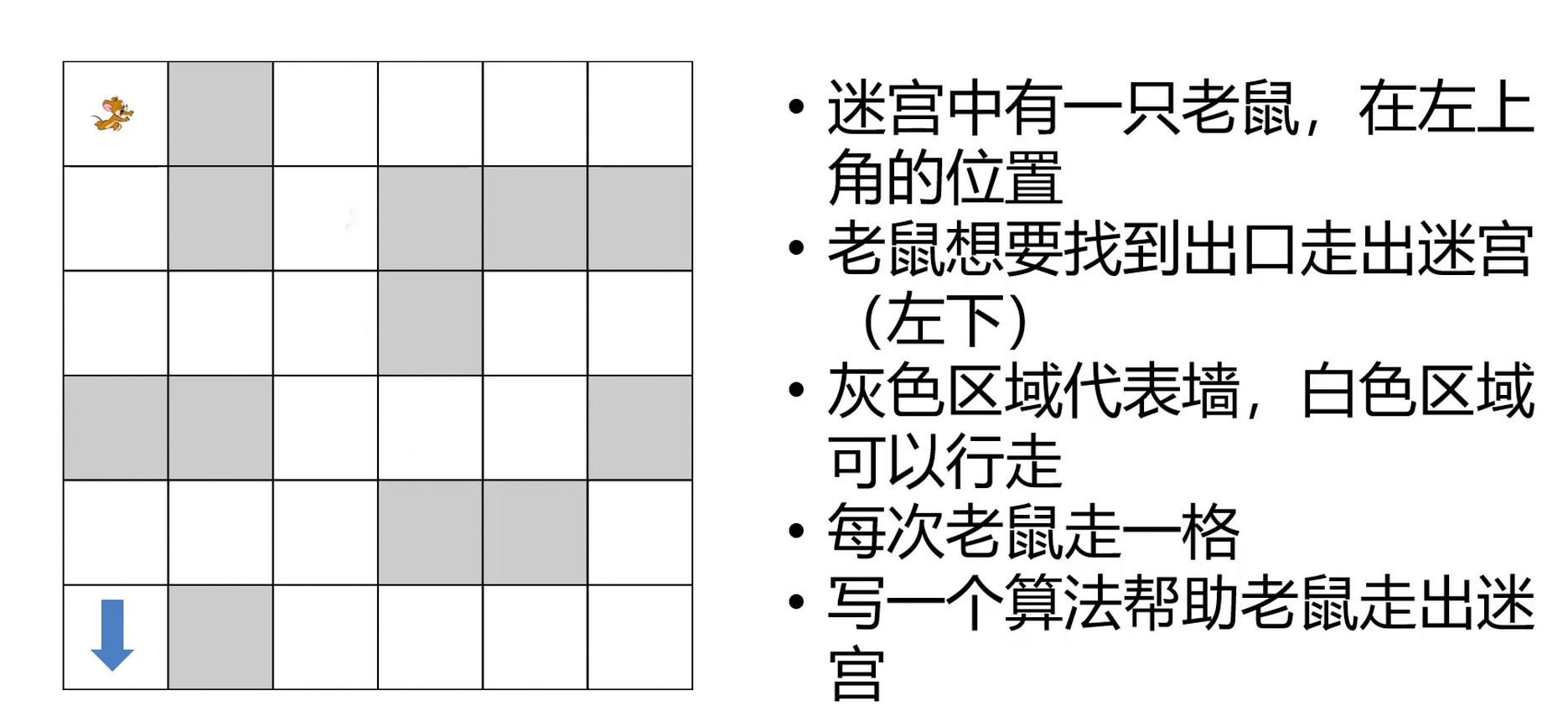

回溯: 尝试一条分支, 如果不成功就回来, 尝试另外一条分支. 是一个深度优先的模型.
八皇后问题. 一个 8*8 的国际象棋棋盘, 如何放置 8 个皇后, 互相不能攻击.
64的阶乘.
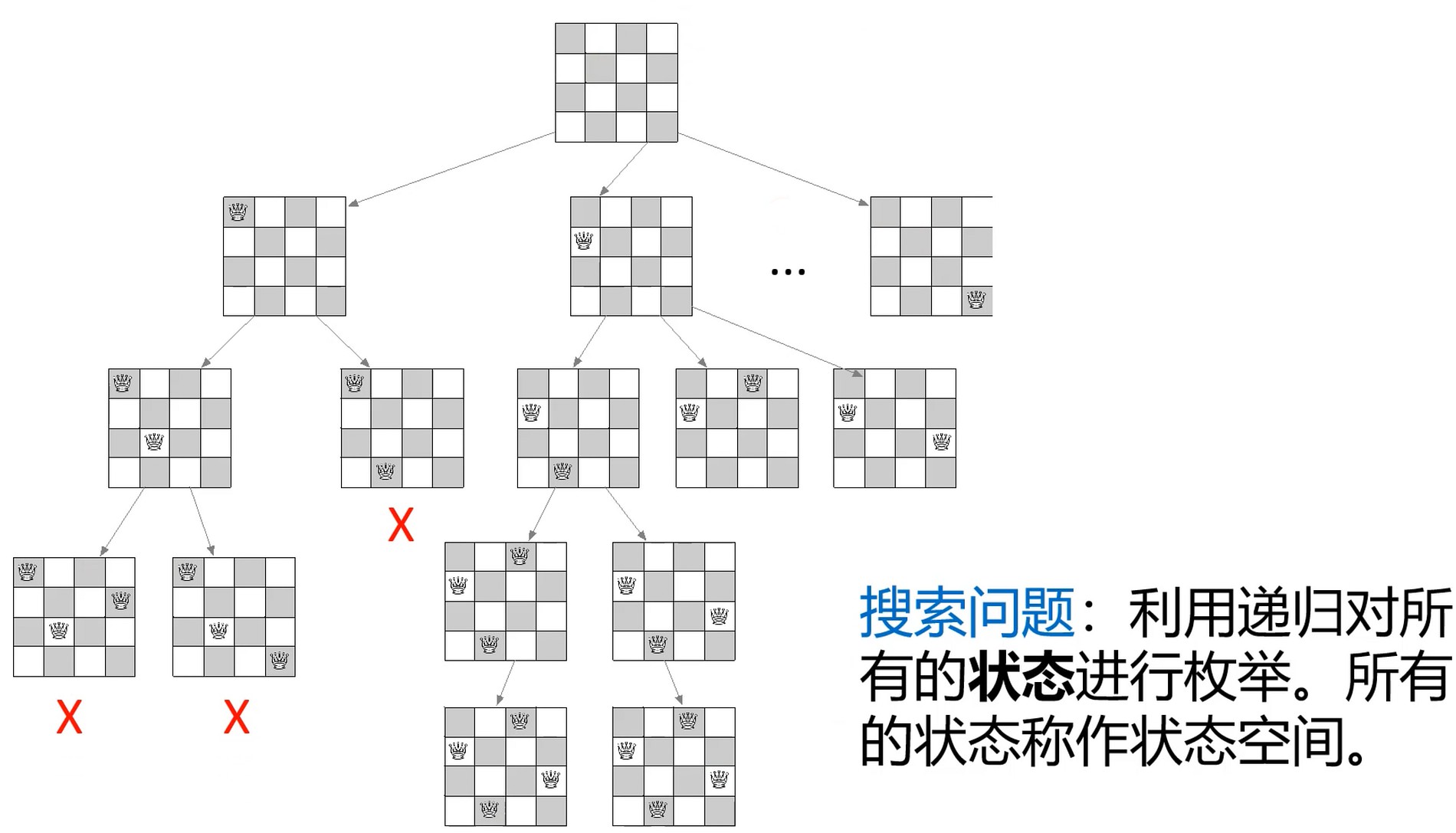
递归和回溯也是一个在状态空间进行搜索的问题.
- 每个递归函数最好又承载函数背后有现实的意思
- 决策有成千上亿, 递归就是只思考决策树上的一个节点
- 要抽象, 要抽象…
前端讲究组件化, 组件上讲流程化, 工程化, 服务端讲究领域化, 领域模型建设.
领域驱动设计
领域驱动的架构
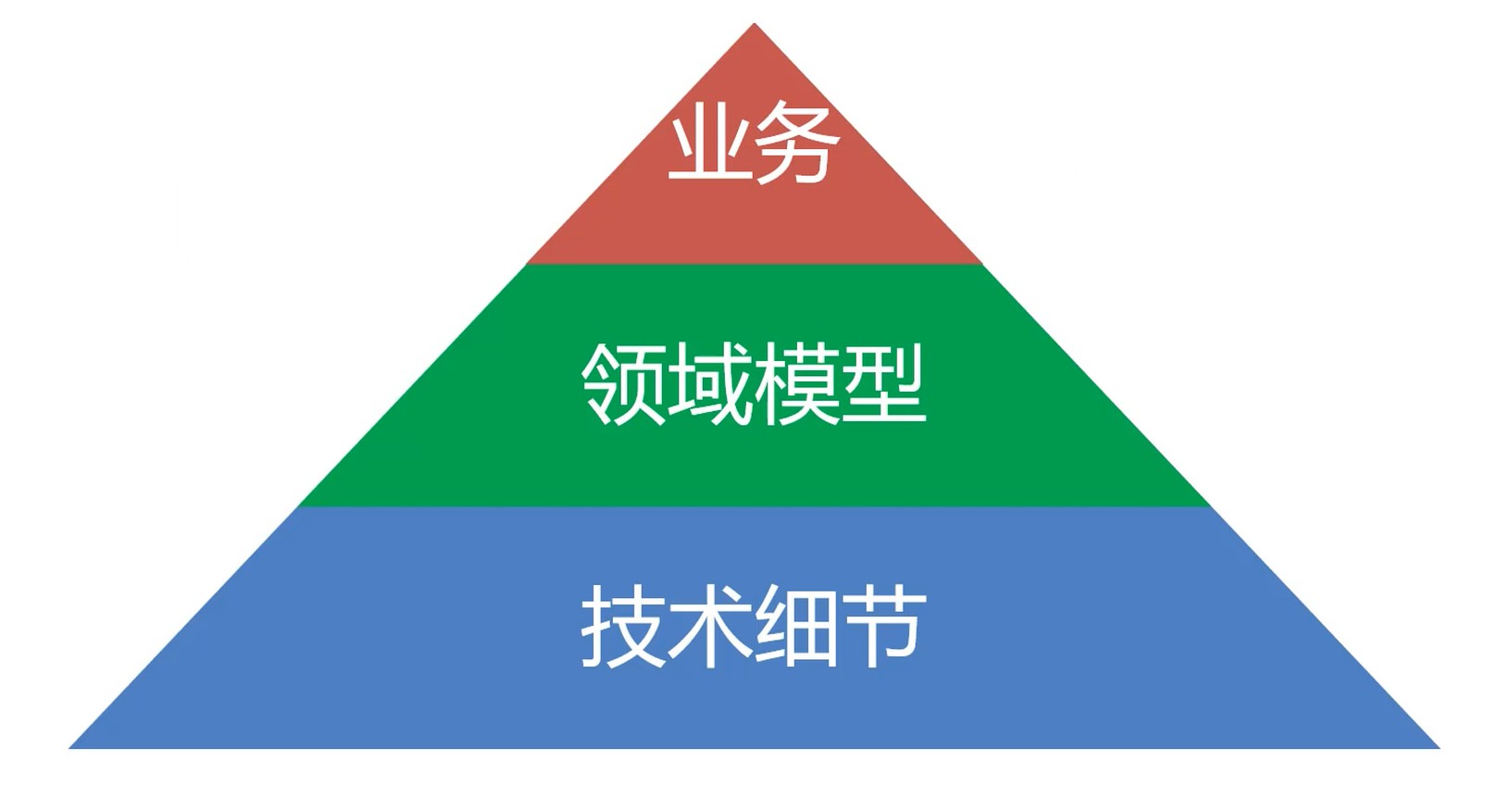
编译器 其实就是一个很经典的领域模型拆分过程. 编译的过程, 不是简单的一个函数把源代码转换成树, 而这个工程不是数据结构和算法决定的.
词法分析器的结构抽象成符号, 语法分析器结果抽象成语法树. 这是因为在现实世界中有可依托的现象, 这个现象就是大家在做中文, 英文的分析过程中依然在依据这样的行为, 所以才产生这样的模型.
如果要把 TinyScript 换成 java, 会发现要改的地方并不多, 而可以很快进行替换的原因在于对这个领域进行了建模.
无论是前端还是服务端, 都在划分自己的领域.
把一个领域的模型做得越来越透彻就是工程师的职责和价值. 让代码可以很清楚明白地描述现实世界中发生的客观现象.
系统够不够健壮, 就是对这理解得够不够透彻. 领域每一处的设计是否符合客观现实, 是否真正抓住业务核心. 当真正抓住的时候, 会发现, 没有需求是业务给的, 而是系统给业务事情做.
而具体实现, 例如词法分析器, 可以是自顶向下的设计, 也可以是自下向上没有递归的设计. 这就会有大量的数据结构和算法, 这些工程师的功底, 就像古文说的 世之奇伟, 瑰怪, 非常之观, 常在于险远, 然力不足者, 亦不能至也.
所以, 即使领域模型建设得很好, 但是没有扎实的技术, 也落实不了这些模式, 最后还是会千里之堤溃于蚁穴.
如果技术到位, 那么整个系统是一个积木型的结构, 可以不停地组装重组重构, 可以不断发展, 驱动业务, 而业务只是思考如何把手头的资源最大化来进行盈利, 而这个就叫做领域驱动开发.
中间语言翻译器
中间代码生成.
三地址代码
对于 var a = 1*2+3 cpu需要计算几次?
- 1*2
- 2+3
实际有几次指令?
- 1 读入寄存器
- 2 读入寄存器
- 计算 1*2, 写入寄存器
- 计算 2+3, 写入寄存器
- 读入寄存器到内存
2次计算转换成5个CPU指令需要一个中间表示形式–三地址代码
- var a= 1*2 + 3 本来就需要先拆分成两步
- p1 = 1*2
- p2 = p1 + 3
- 将上述两个步骤映射到CPU指令也会更容易
定义: 一行最多有3个地址的代码
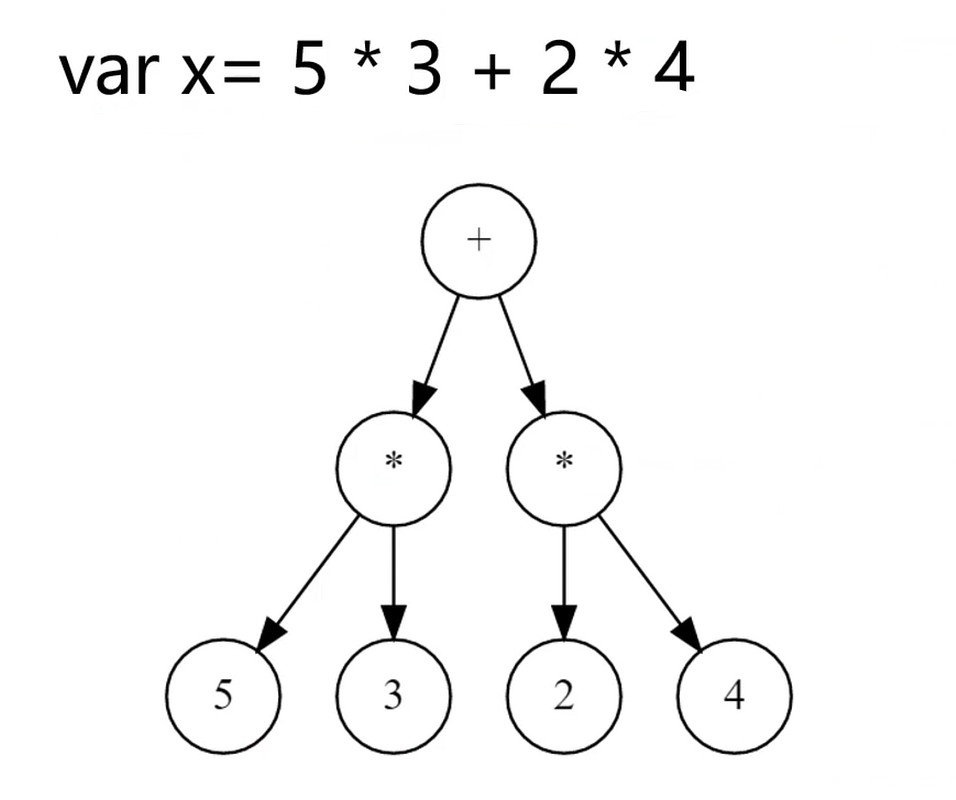
- p0 = 5 * 3
- p1 = 2 * 4
- x = p0 + p1
等价的递归求解

思考递归的时候, 首先思考终止条件
递归先自顶向下到终止条件, 再自下向上回溯
if语句
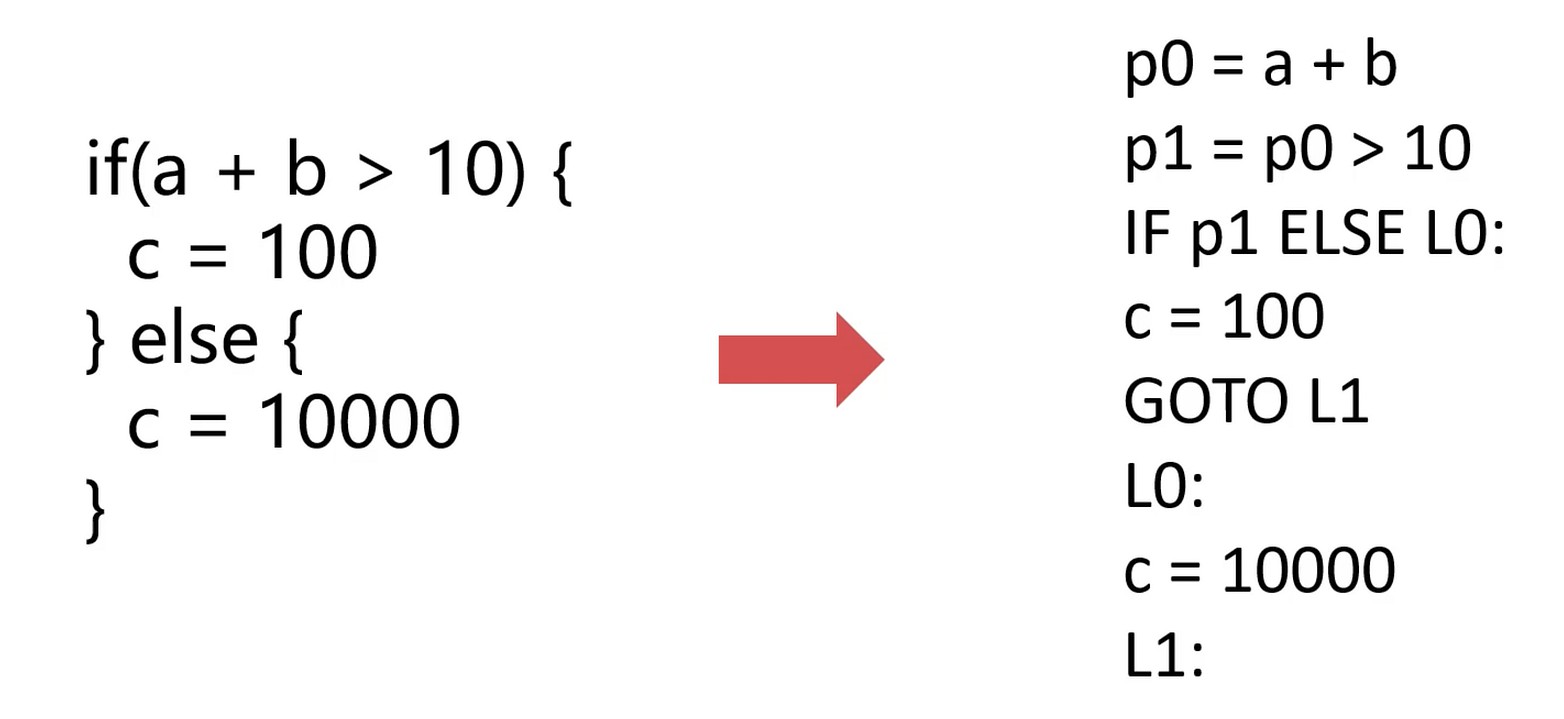
L0: Label 的意思
for循环
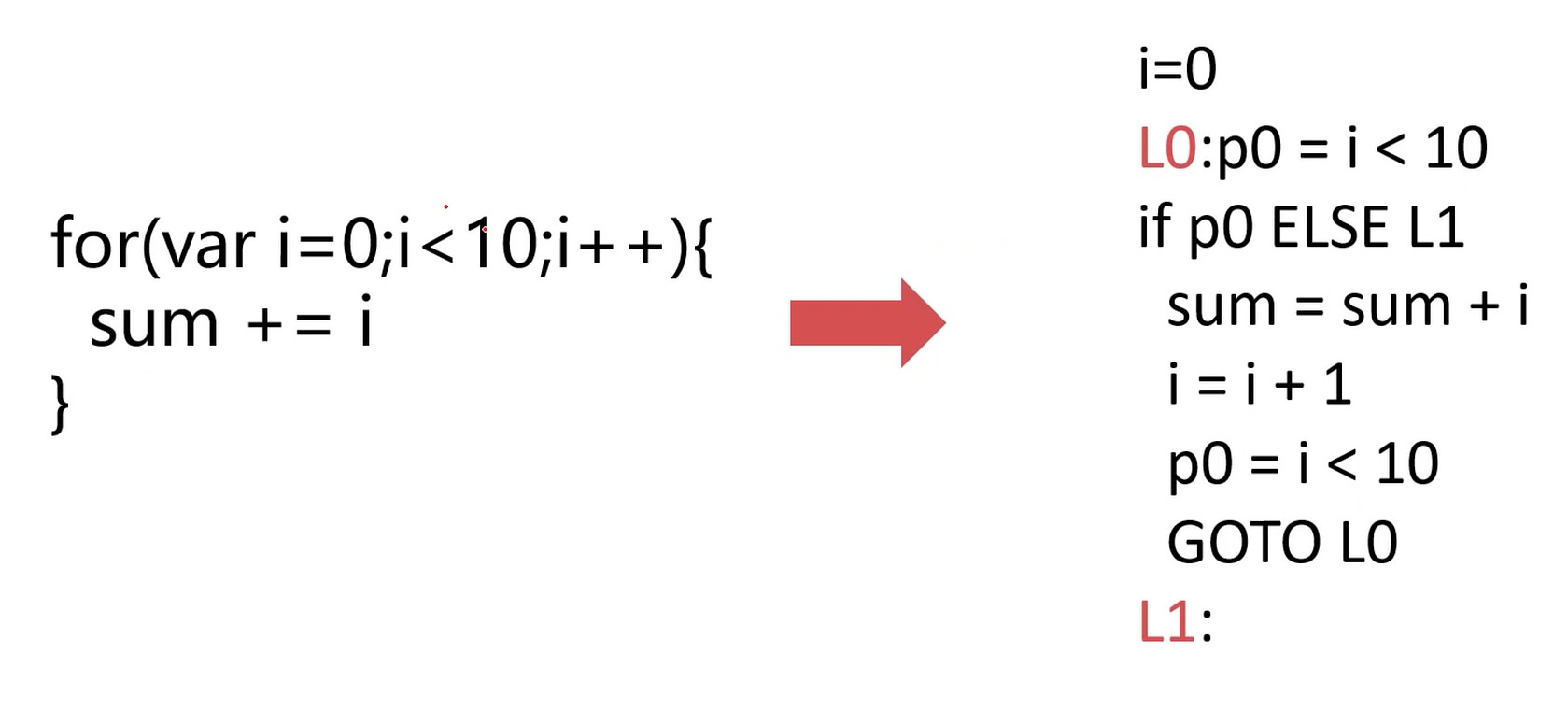
函数, 可以理解为一种标签.
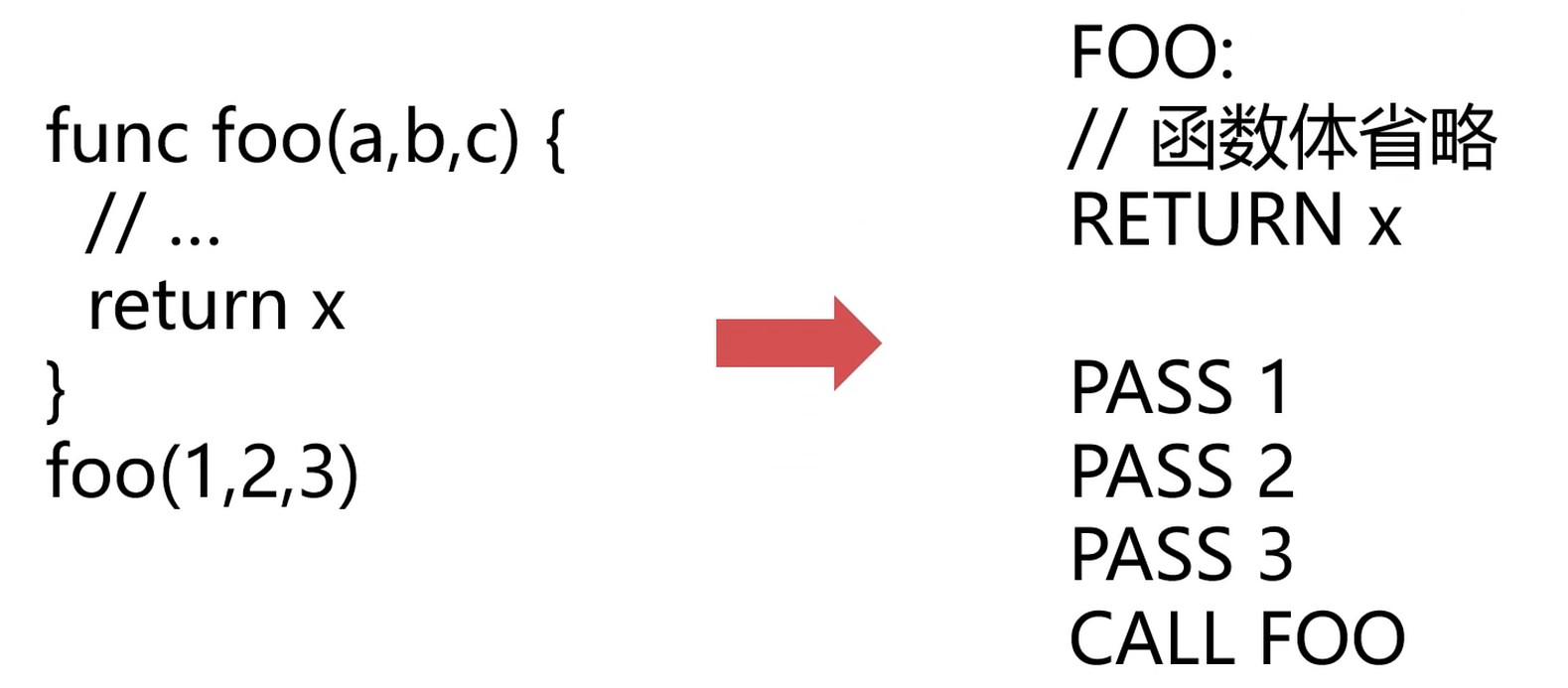
- 结构化思维
- 目标拆解
- 组装复用(积木)
- 流式框架(每一步的结果流向下一步)
构造三地址代码
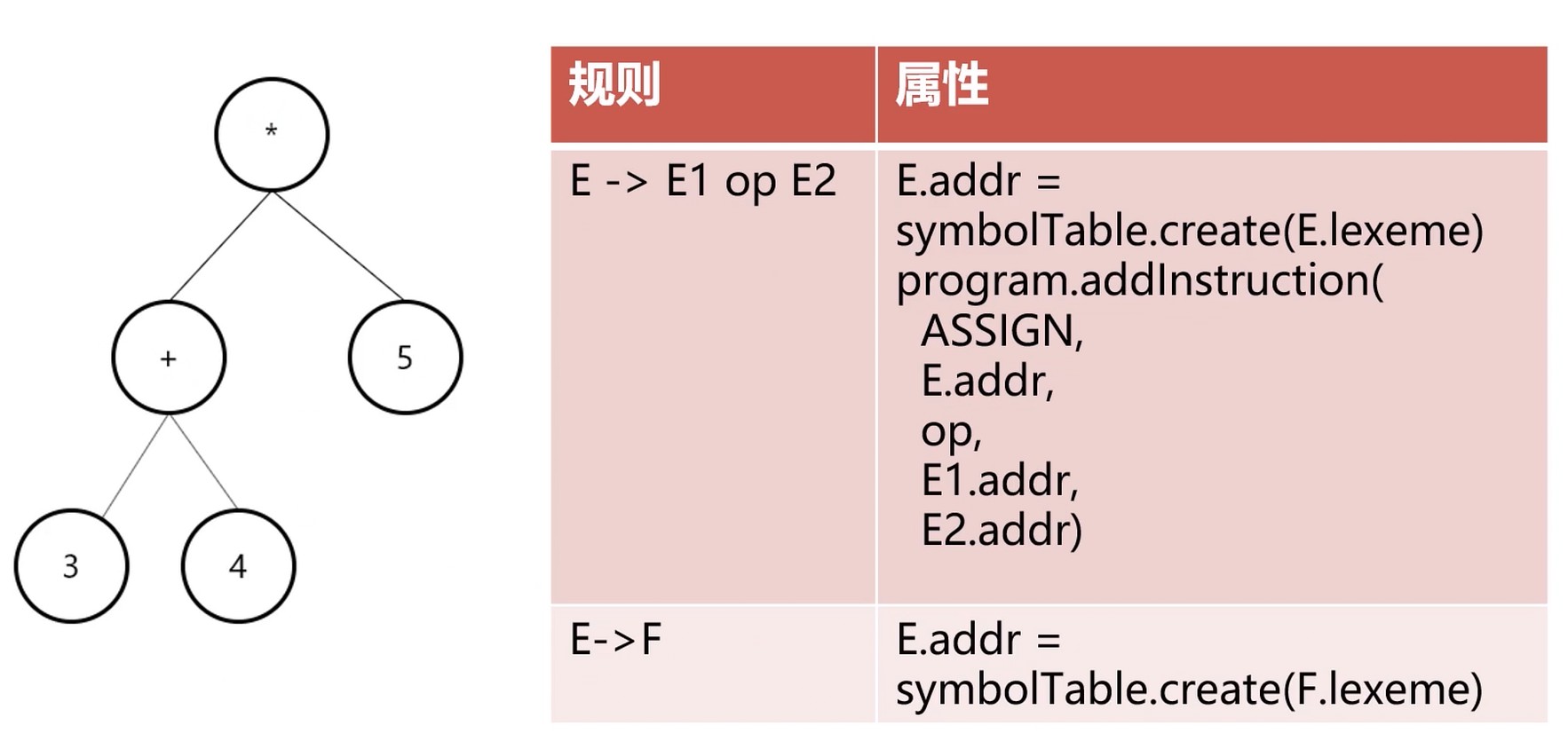
基于 SDD 的翻译.
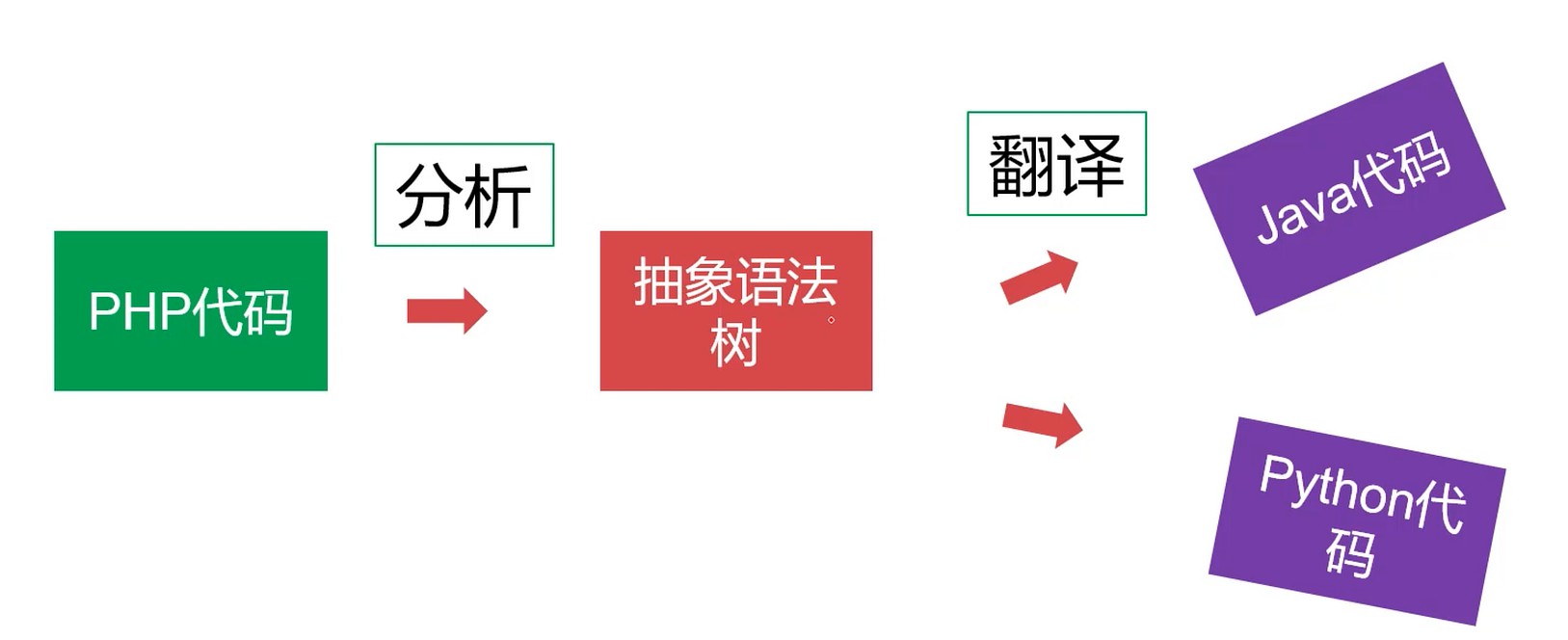
不污染抽象语法树就是最大价值利用.
分析 = 词法分析 + 语法分析
PHP代码 -> 词法分析 -> 符号流 -> 语法分析 -> 抽象语法树

语法制导定义(SDD)
Syntax Directed Definition.
语法是指上下文无关的文法或正则文法, 制导是”按照”,”根据”的意思.
- 定义抽象语法树如何被翻译
- 组成
- 文法(如何组织翻译程序)
- 属性(用于存储结果和中间值)
- 规则(描述属性如何被计算)
- 文法(如何组织翻译程序)

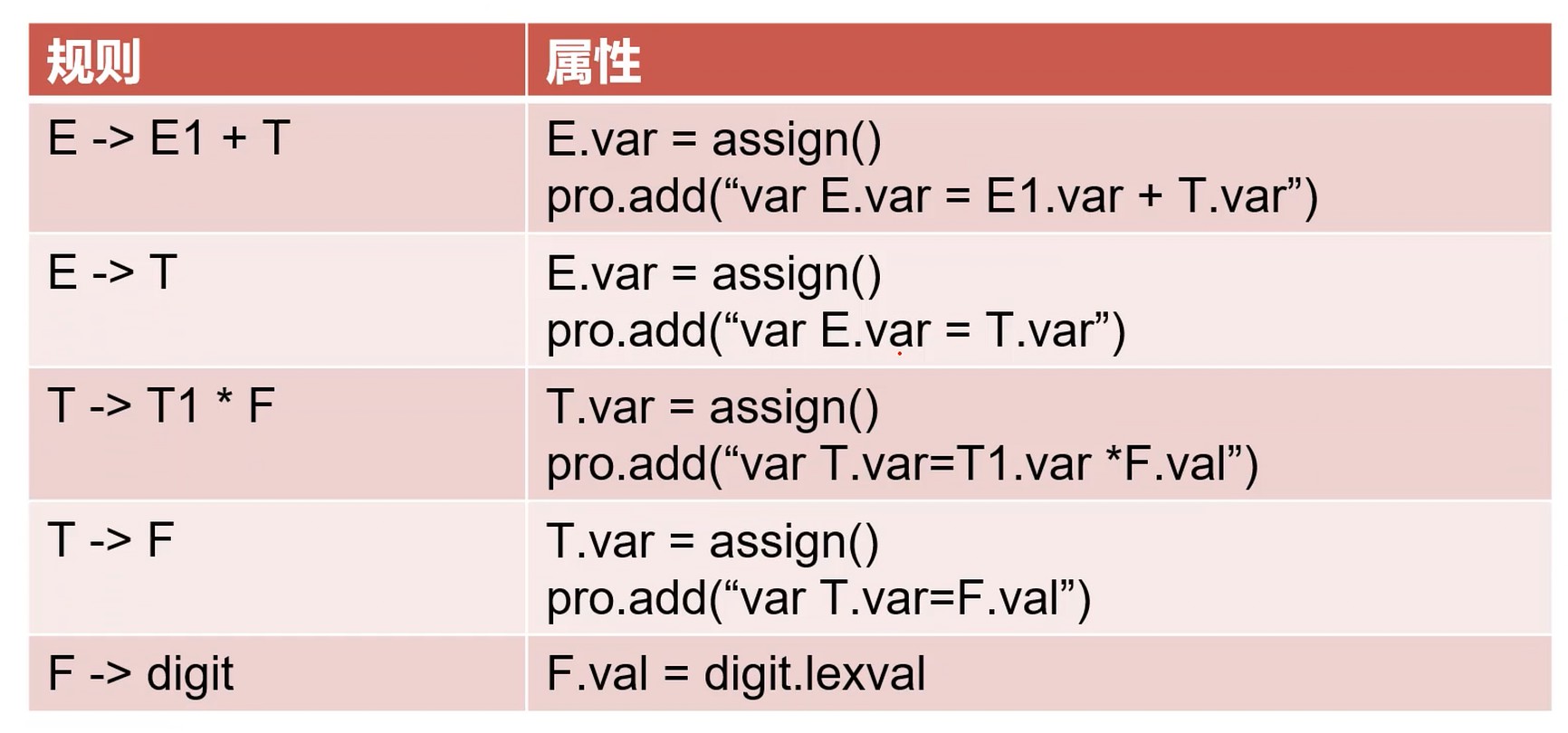
为什么这样设计?
- 解耦: 一套AST可以多套使用
- 规范: 先写出 SDD 再写程序不需要过多思考, 可以类比语法分析部分的产生式到递归的关系.
思考递归怎么写, 就有基条件和递归体.
思考循环怎么写, 就有循环不变式.
思考抽象语法树怎么写, 就有产生式.
词法作用域
词法作用域–Lexical Scope
- 一个符号的可见范围称之为它的作用域.
- 符号作用域与源代码的书写相关(词法), 并在运行时(实例)生效.

这种关系是在词法的时候构造的, 是一种描述关系.
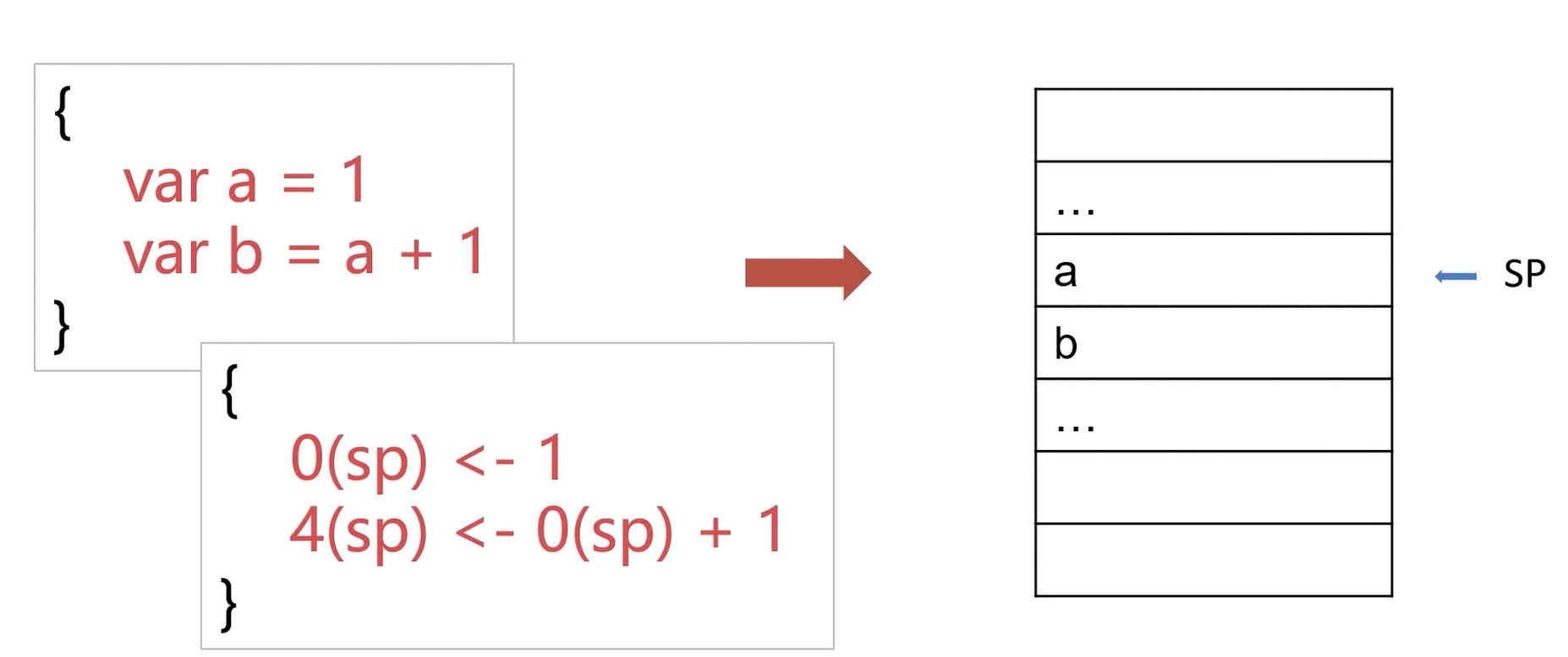
运行时的关系本质上是在内存的引用关系, 偏移量的关系.
一个变量的生命周期
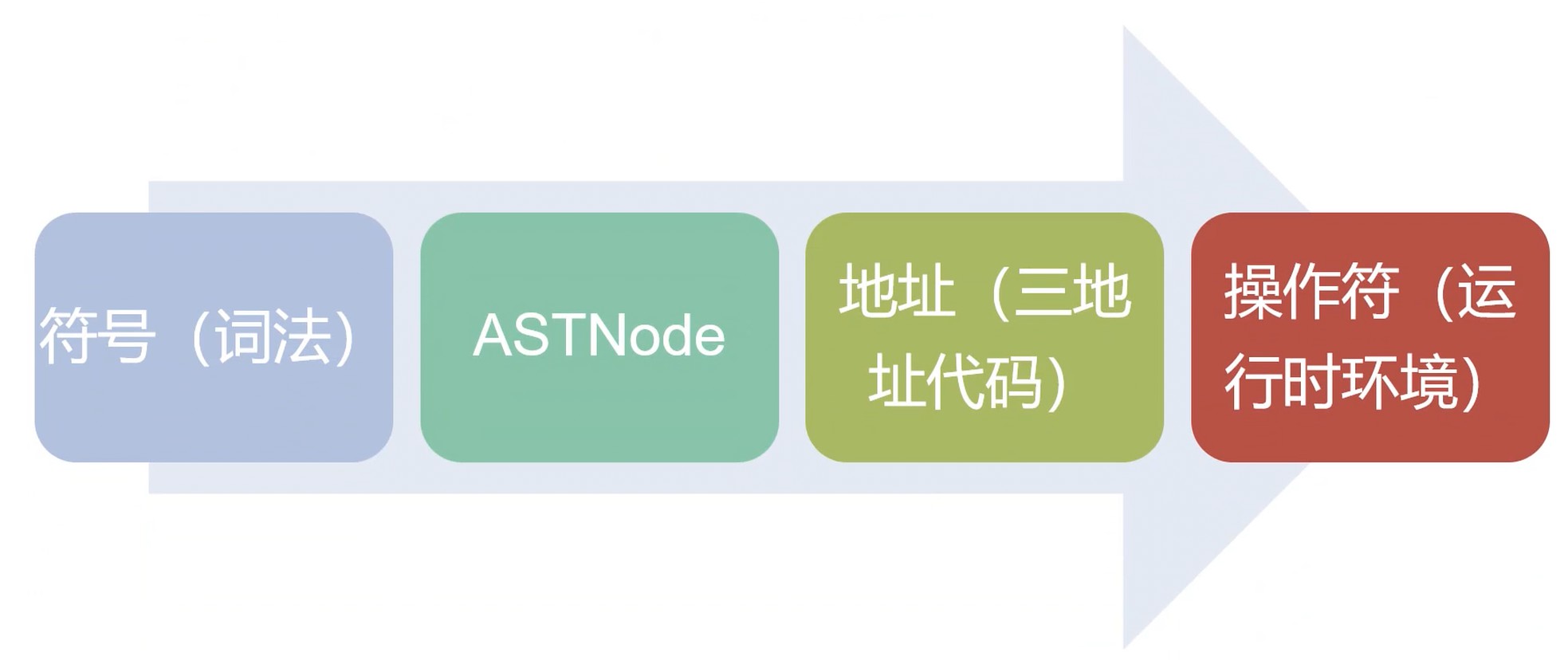
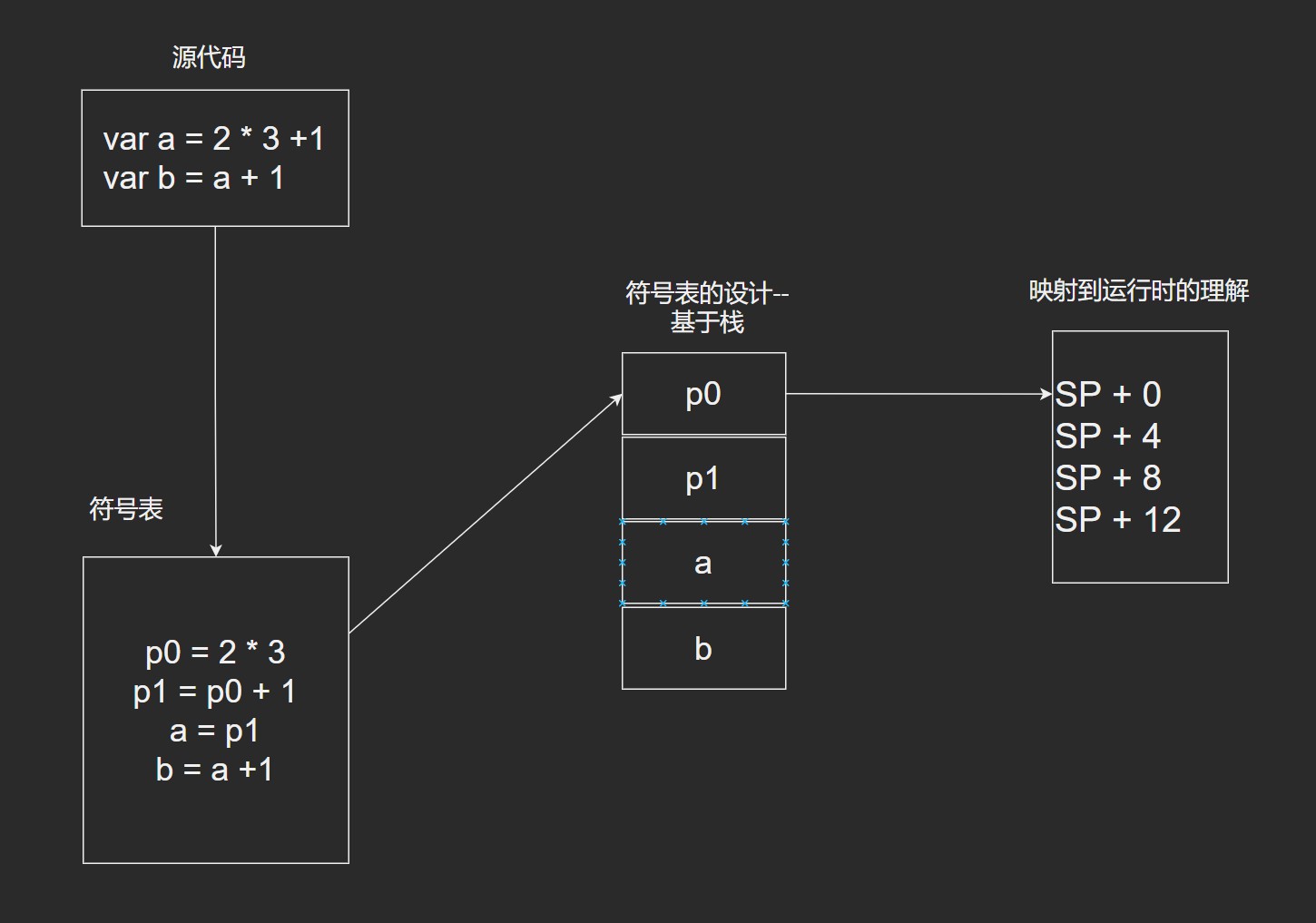
符号表
- 用于存储符号(变量, 常量, 标签)在源代码中的位置, 数据类型, 以及位置信息决定作用域和运行时的相对内存地址.
- 符号(symbols, 与词法的token不一样, 这个符号已经与地址相关了)
- 常量表
- 变量表
TinyScript运行时内存分布

堆: 从上到下增长, 低位->高位
栈: 从下到上增长, 高位->低位
一步一步把未分配区域吃掉.
静态符号表(Static Symbol Table)
- 实现: 哈希表. key是值, value是符号, 可以映射到内存模型上.
- 用途: 用于存储常量在常量区的位置.
符号表(Symbol Table)
- 实现(树+哈希表)
- 用途: 用于存储每个符号所在词法的作用域, 以及它在词法作用域中的相对位置.
TinyScript 符号抽象
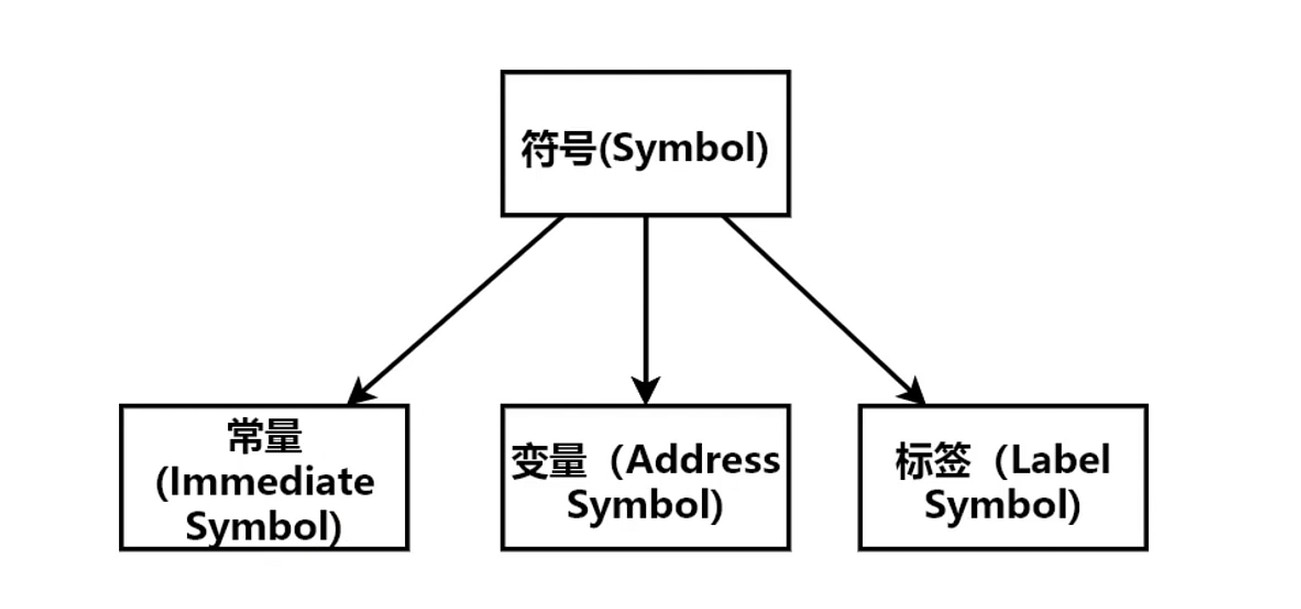
TinyScript 符号表
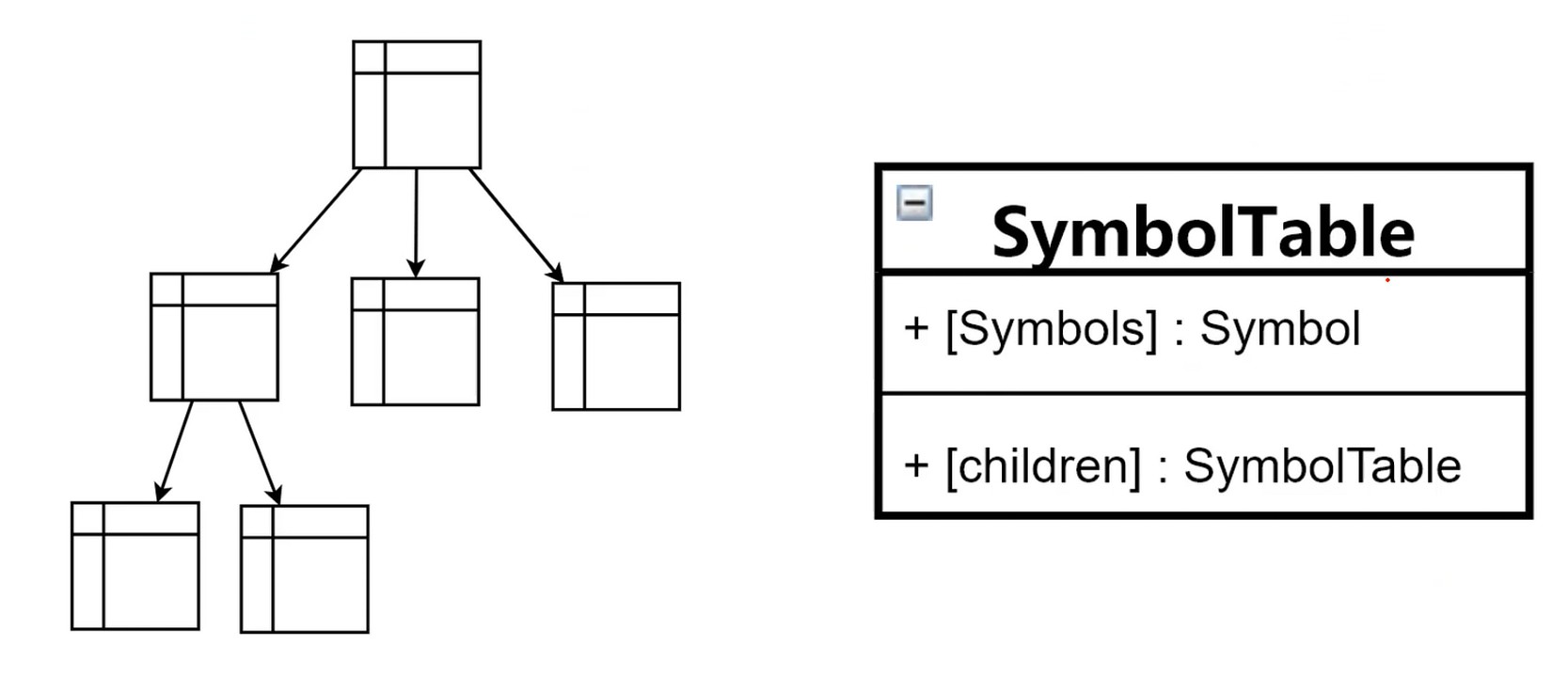
符号表示例
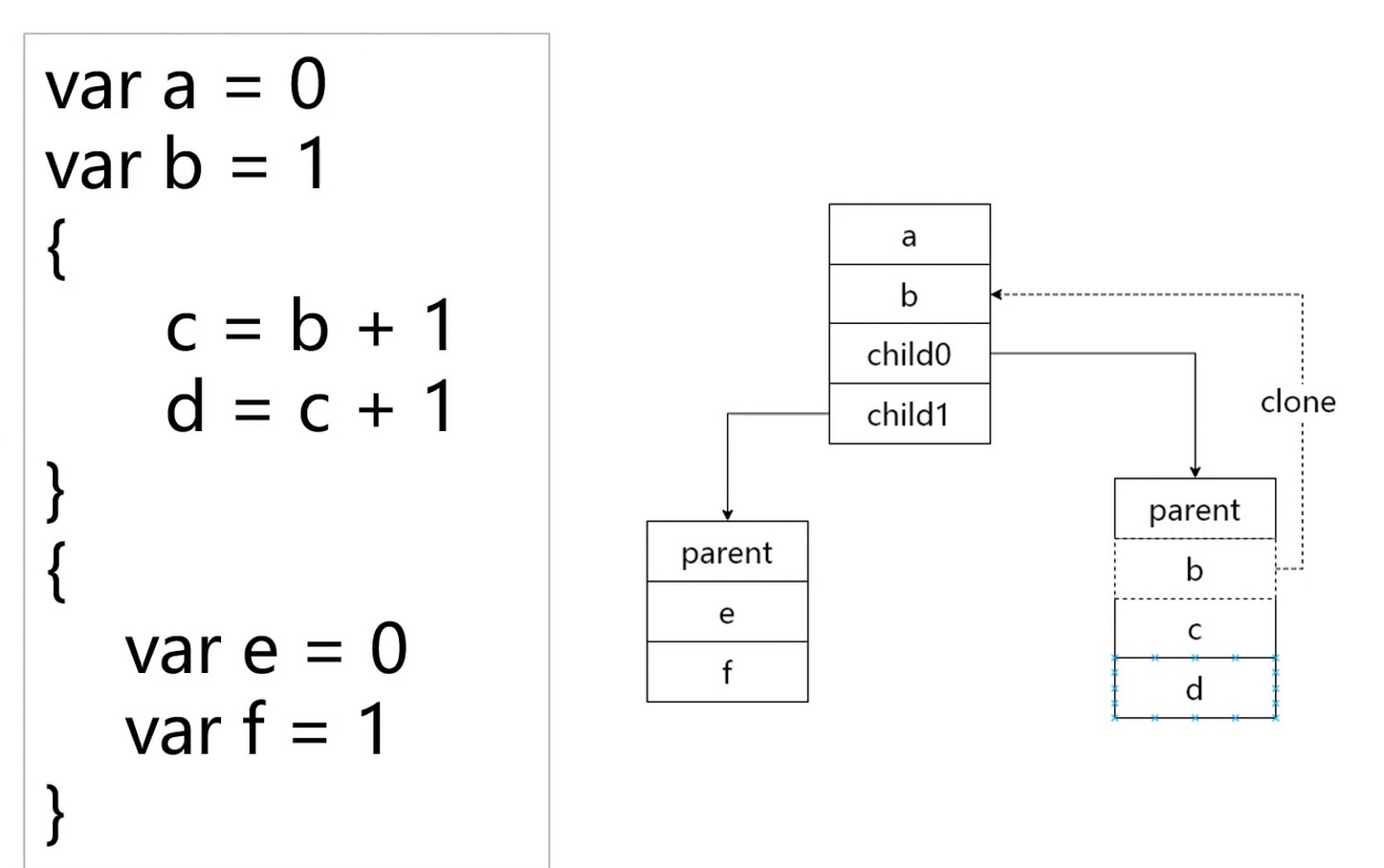
符号运行时的编排–符号的Offset

Block运行时编排–活动记录
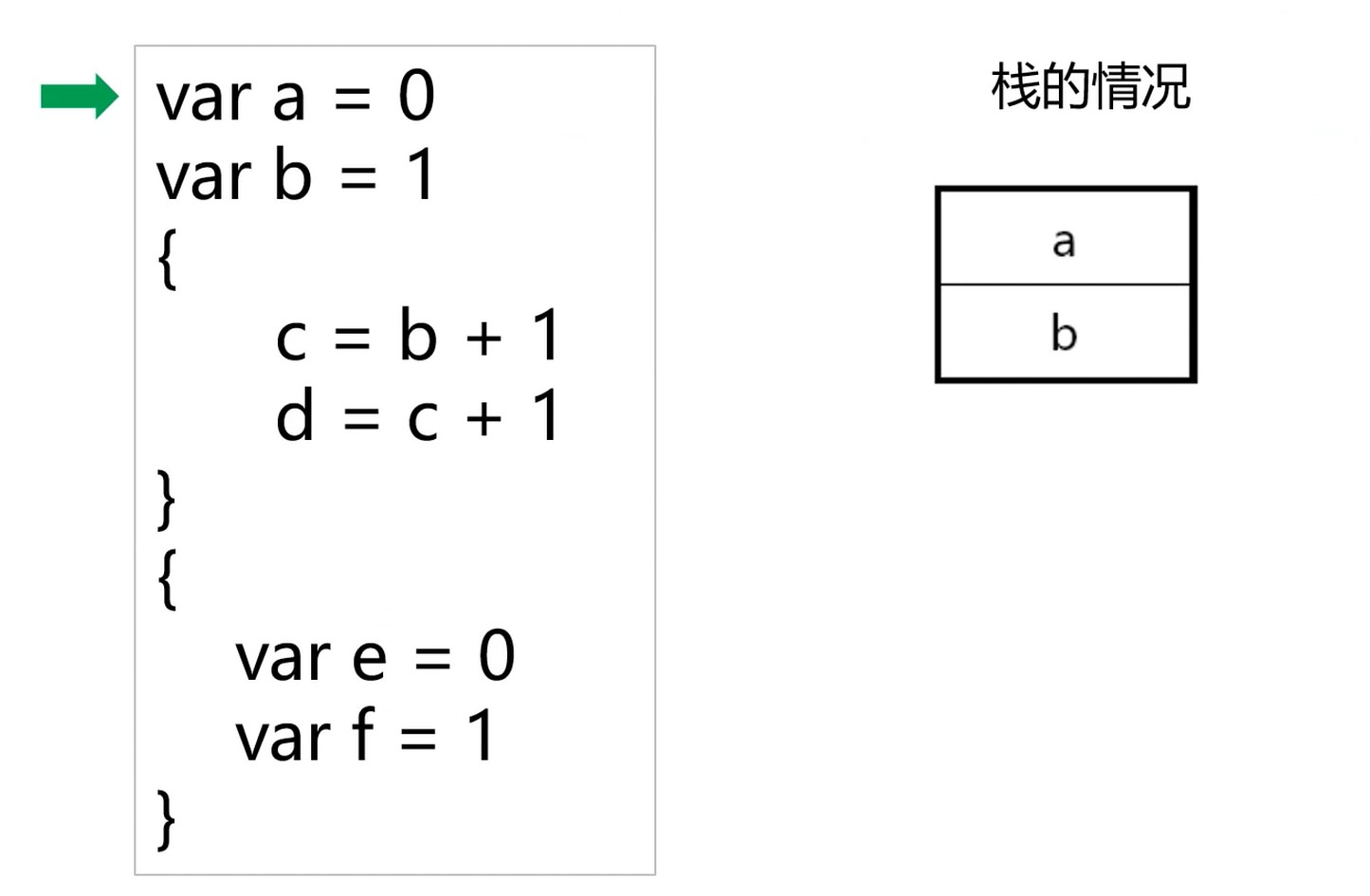
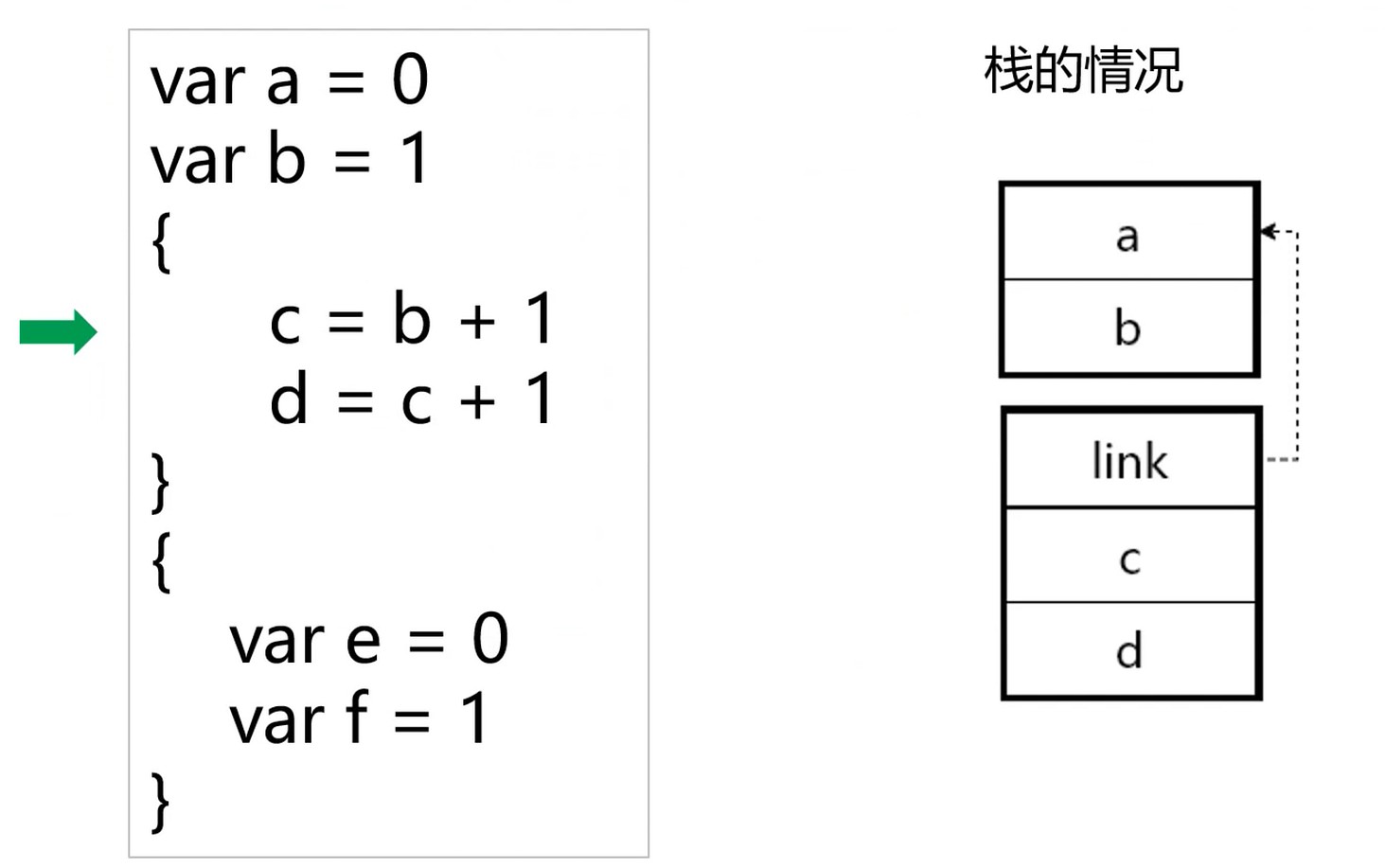
查找符号–递归向上的过程

符号表实现
- 定义 Symbol
- 定义 Symbol Table
- Unit Tests
三地址代码的表示
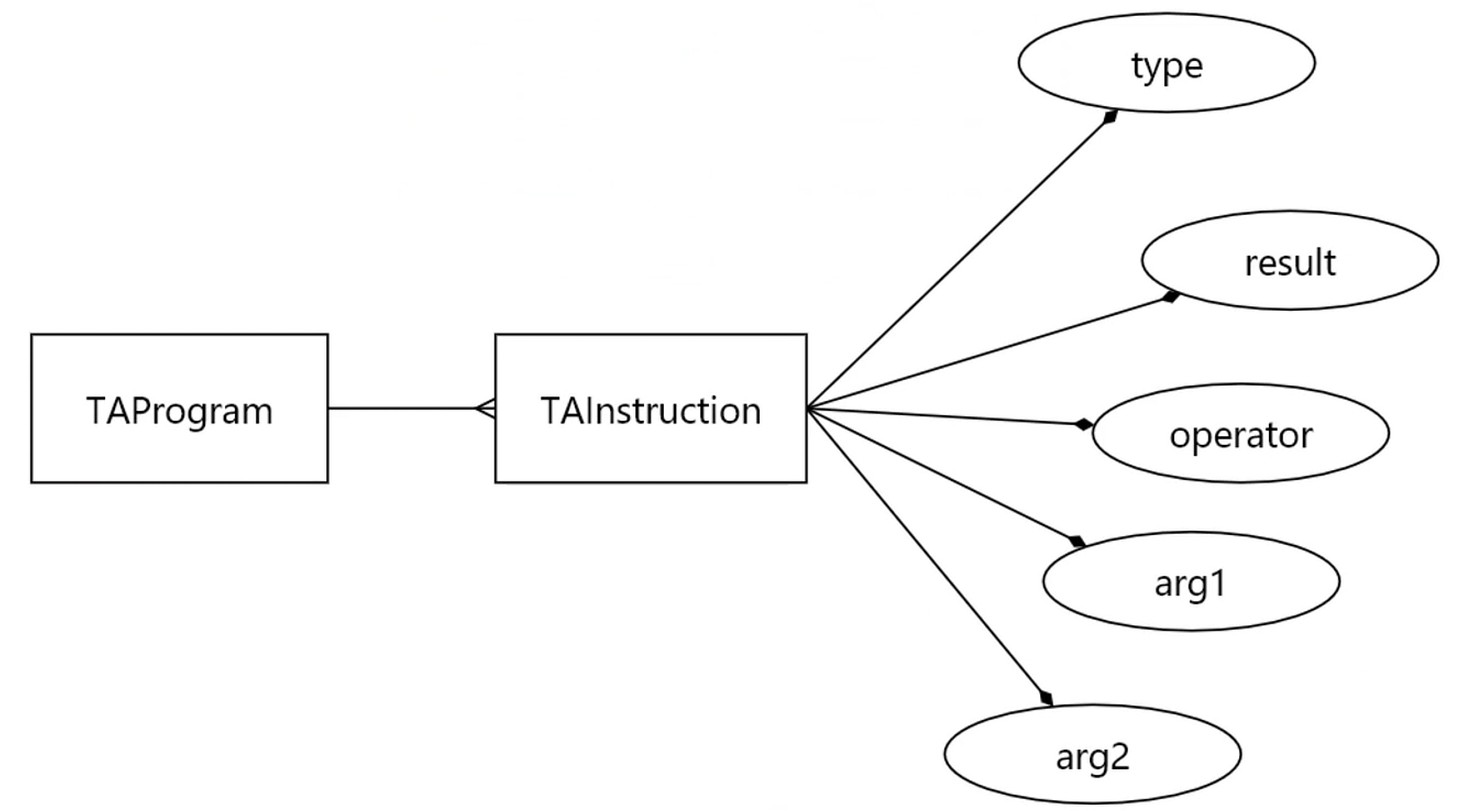
程序 –一对多–> 指令 -> 属性
左边是结果, 右边的操作符和参数.
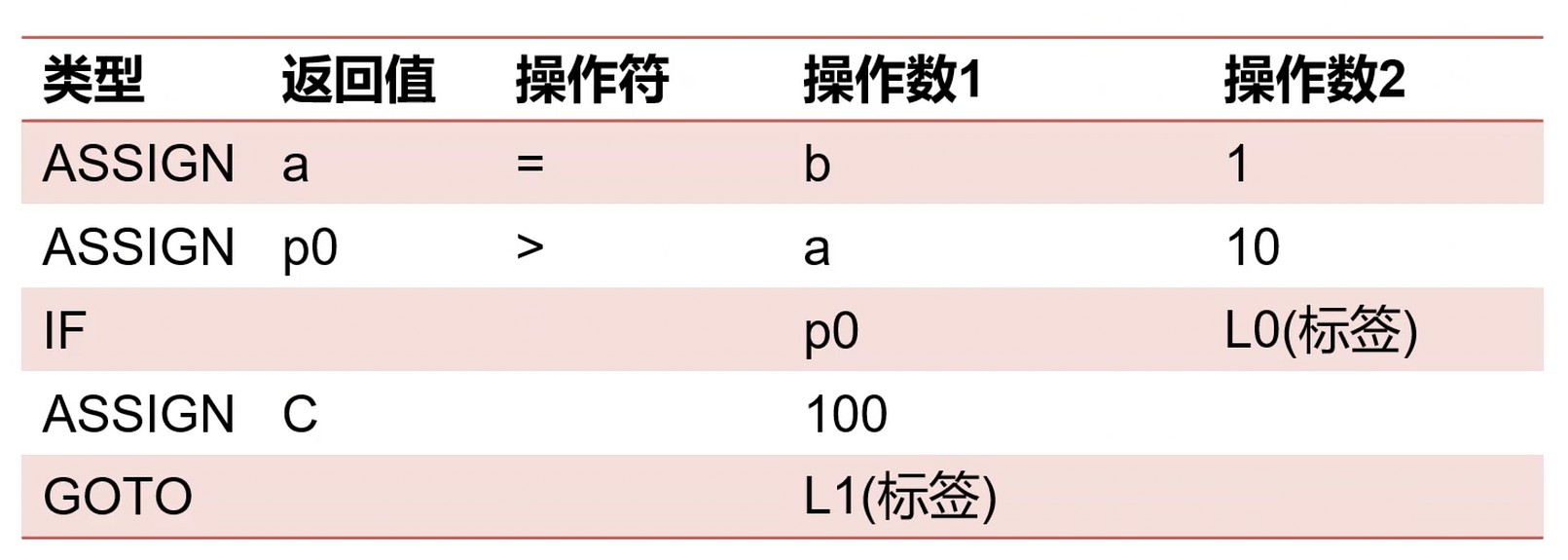
三地址指令–五元组表示
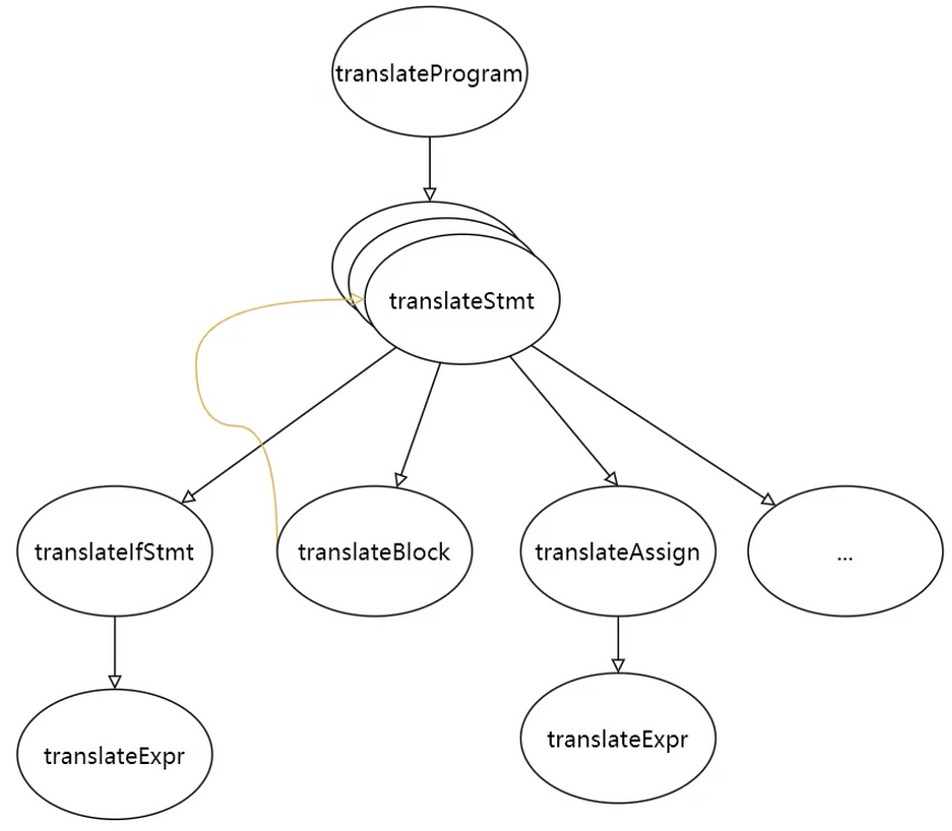
自顶向下设计
数据是死的, 对象是活的.
翻译整体结构和表达式
AST 根据 SDD 进行翻译.
文法体验在规则上.
翻译实现
- 翻译自顶向下的结构
- 语句/赋值语句
- 处理表达式
- Unit Test
翻译作用域处理
未分配 位与 栈 和 堆 之间.
注意: 栈是向上的.
符号表到运行时, 地址是相对的, 变量通过 offset 的方式进行访问.
活动记录
函数调用都会产生
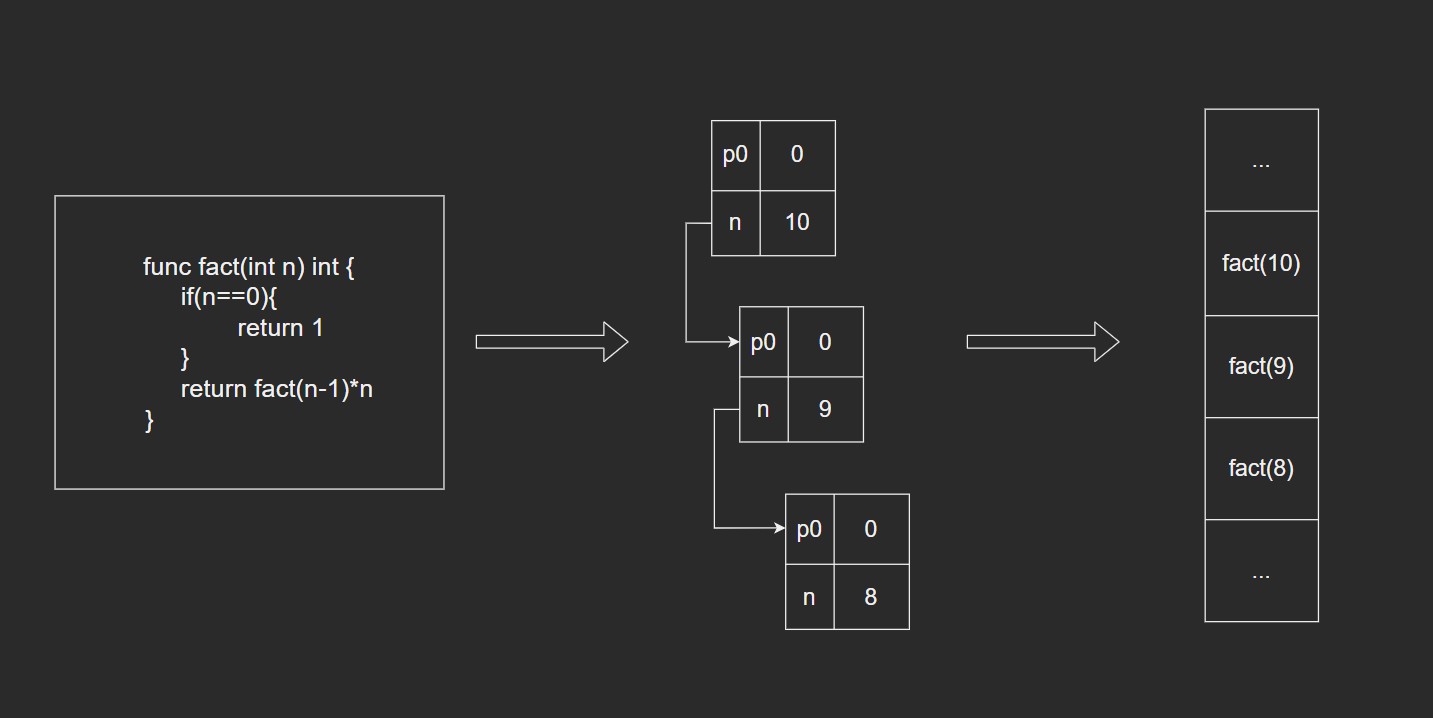
每次调用都会产生一个变量n和p0. 直到结束条件. 之后再往上poll出.
符号表映射到运行时环境就变成活动记录了.
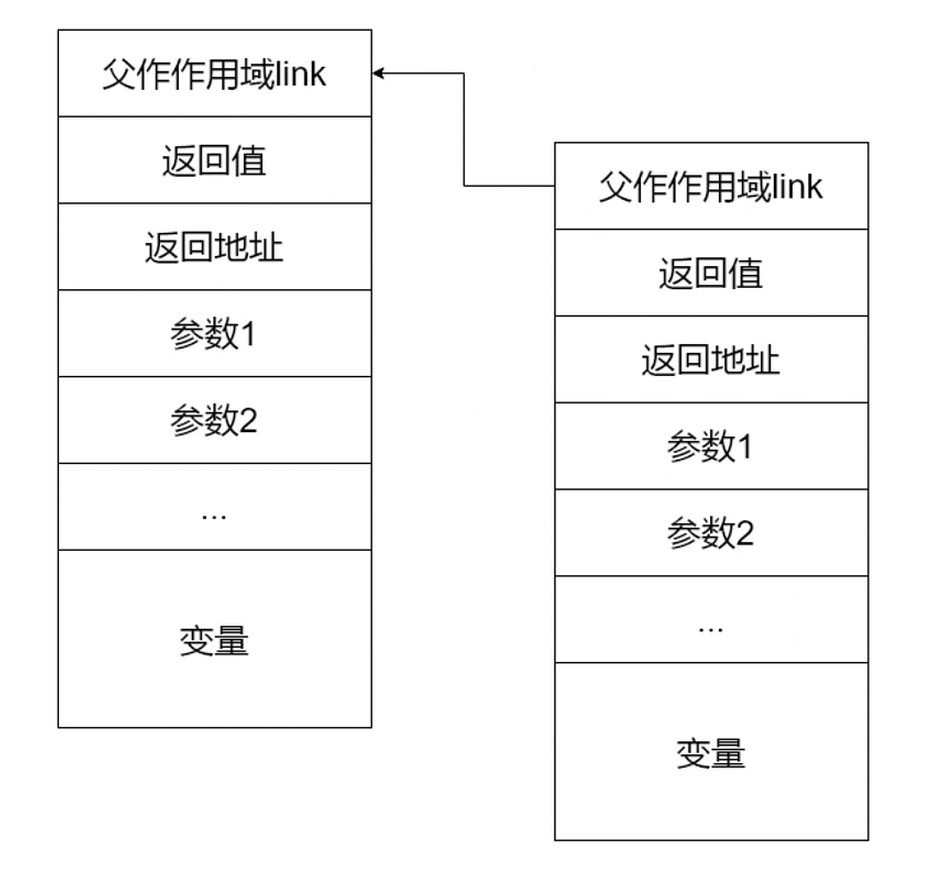
- 翻译Block
- 翻译IfStmt
- 翻译Function
- 测试用例
运行时环境–虚拟机实现
三地址代码(中间语言)之后的用途
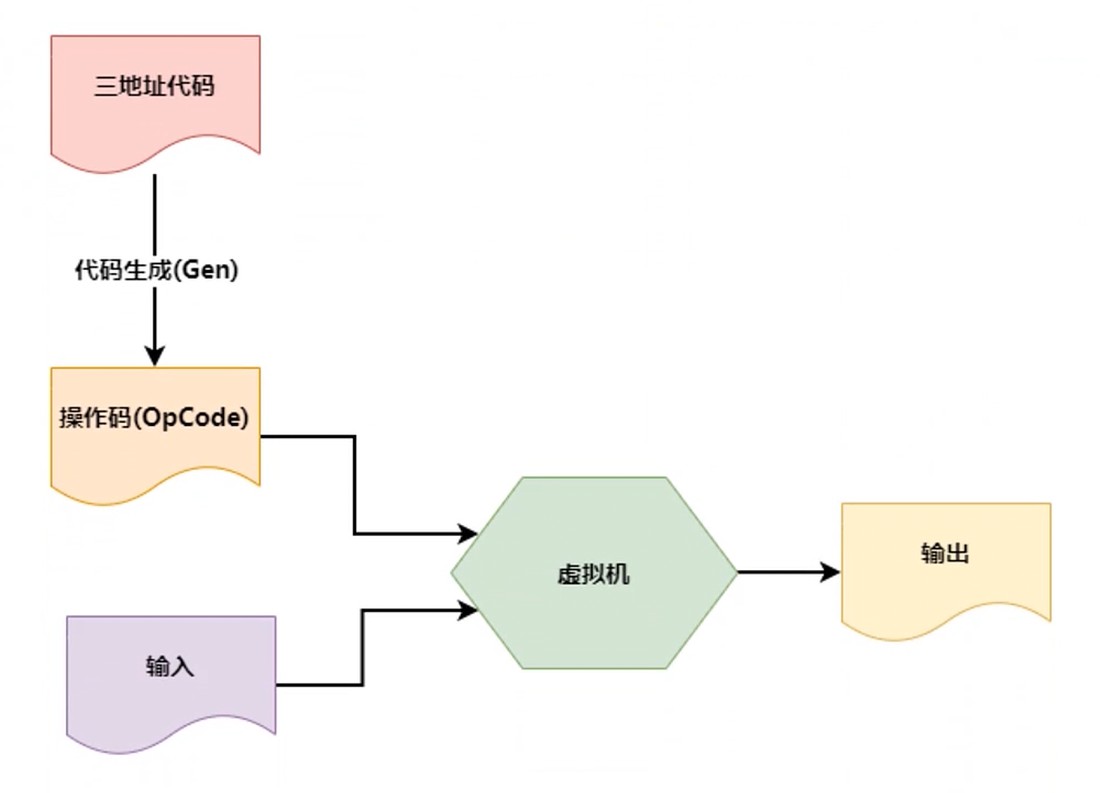
三地址代码 -> OpCode -> VM -> output
代码生成器–Generator
- 是一个转换器, 将三地址代码转化成机器代码
那么为什么不直接使用虚拟机执行三地址代码?
- 性能问题(三地址代码, 如: x=a*b还需要分析)
- 优化问题
- 寄存器的利用(计算最终要在寄存器进行的)
- 机器码选择
- 封装 & 抽象–三地址代码是对机器码的抽象, 对于上一层的对接会更加容易
虚拟机
虚拟机是模拟计算机的软件
作用
- 跨平台
- 资源调度/共享, 多用户
- 隔离(容器, 沙箱)
虚拟机组成
- 内存(32位整数数组)
- 寄存器(32位整数数组)
- PC/SP/RA 等特殊寄存器
- S0/S1/S2 普通寄存器
- CPU循环(fetch/decode/exec)
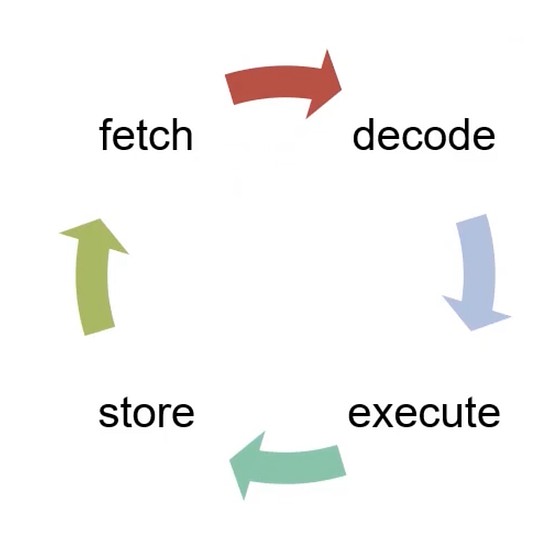
计算机是一个状态机, 寄存器是状态, 指令除非状态的更改
操作码
- 也叫指令码(instruction code), 字节码(byte code), 虚拟机上执行的虚拟机器码(类比计算机上执行的机器代码)
- 为什么要有 Operate Code
- 标准(Standard)优势
- 性能考量
- Opcode 到机器码的开销可以用 JIT 技术优化
举例: 比较寄存器S0和S1的值, 如果不相等就跳转到第100行代码, 如果相等就执行下一行代码
BNE S0, S1, L0

举例: 将S0和S1的值相加, 存入S0
ADD S0, S1, S0

把上面的指令组成一个指令, 规则由自己决定.
准时制技术–Just In Time
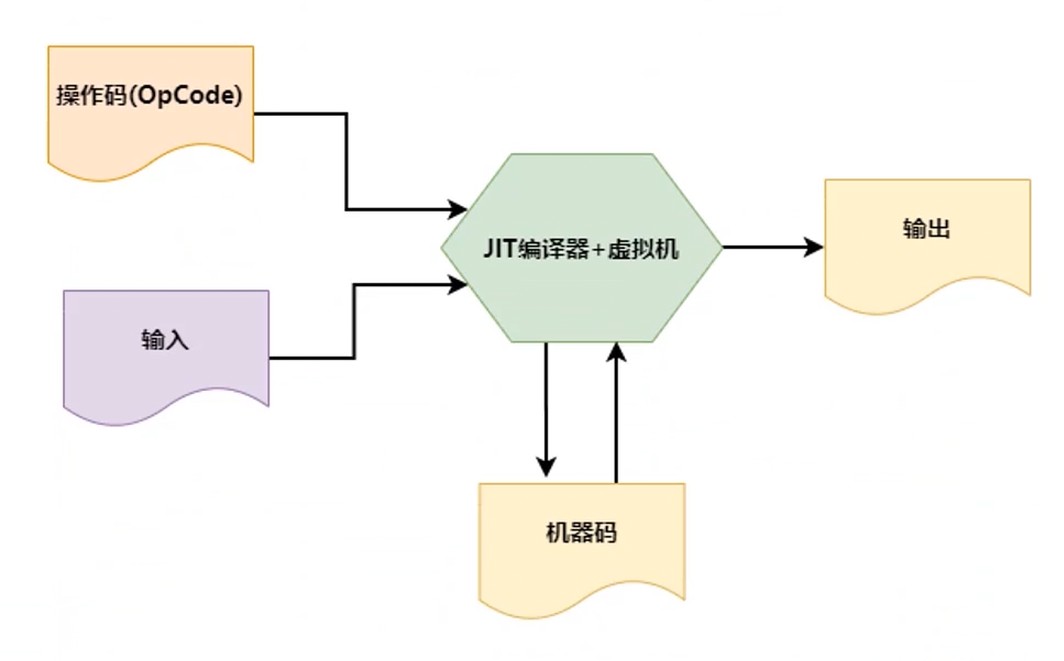
TinyScript 代码生成器类型设计
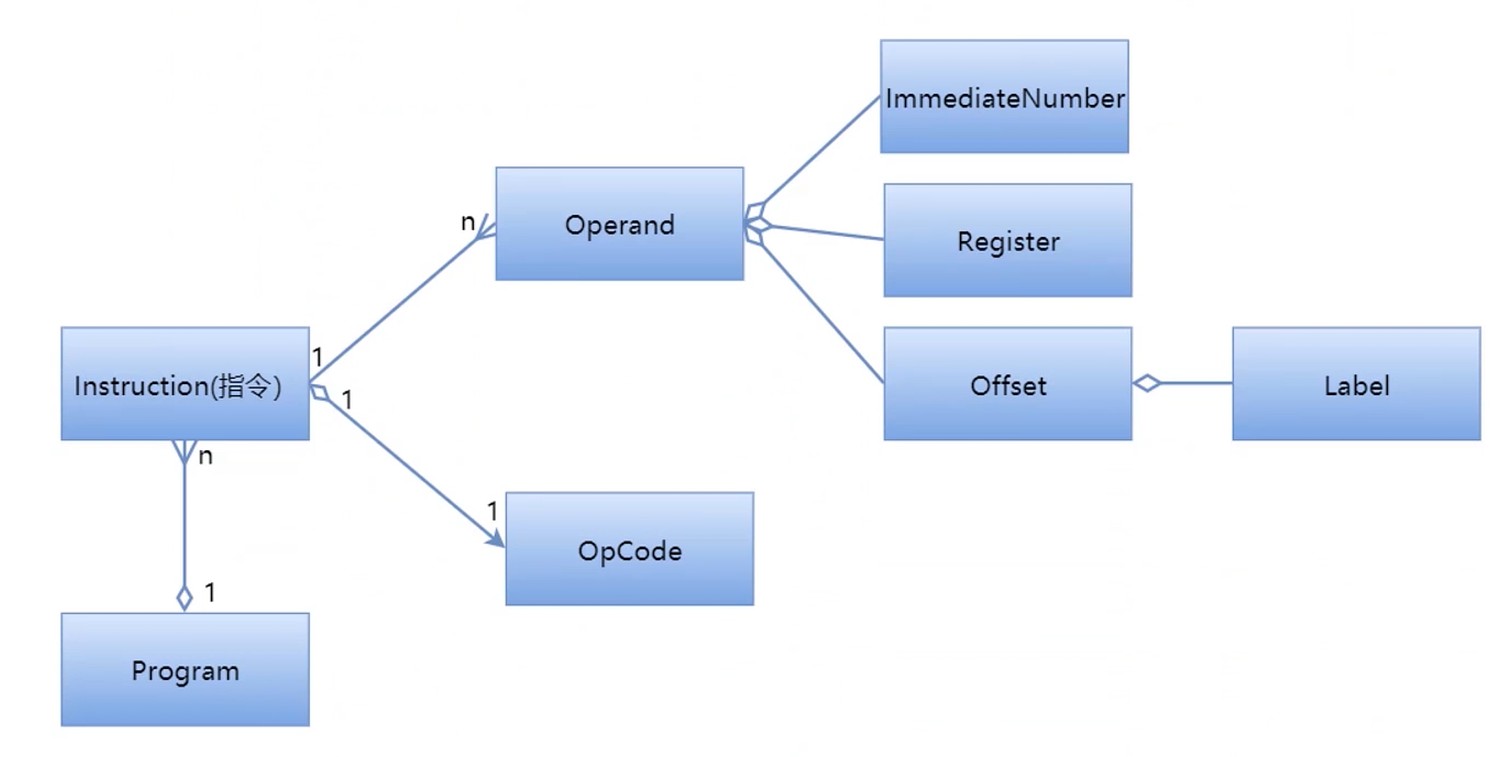
程序由指令组成, 指令两部分组成, 一部分是OpCode, 一部分是 Operand(操作数).
Operand 的类型有四种, ImmediateNumber(直接放字符), Register, Offset, Label
指令和程序表示
- 程序(Program)
- 指令(Instruction)
- 操作符/操作数(OpCode/Operand)
三地址代码转化成指令
assign类型
赋值类型
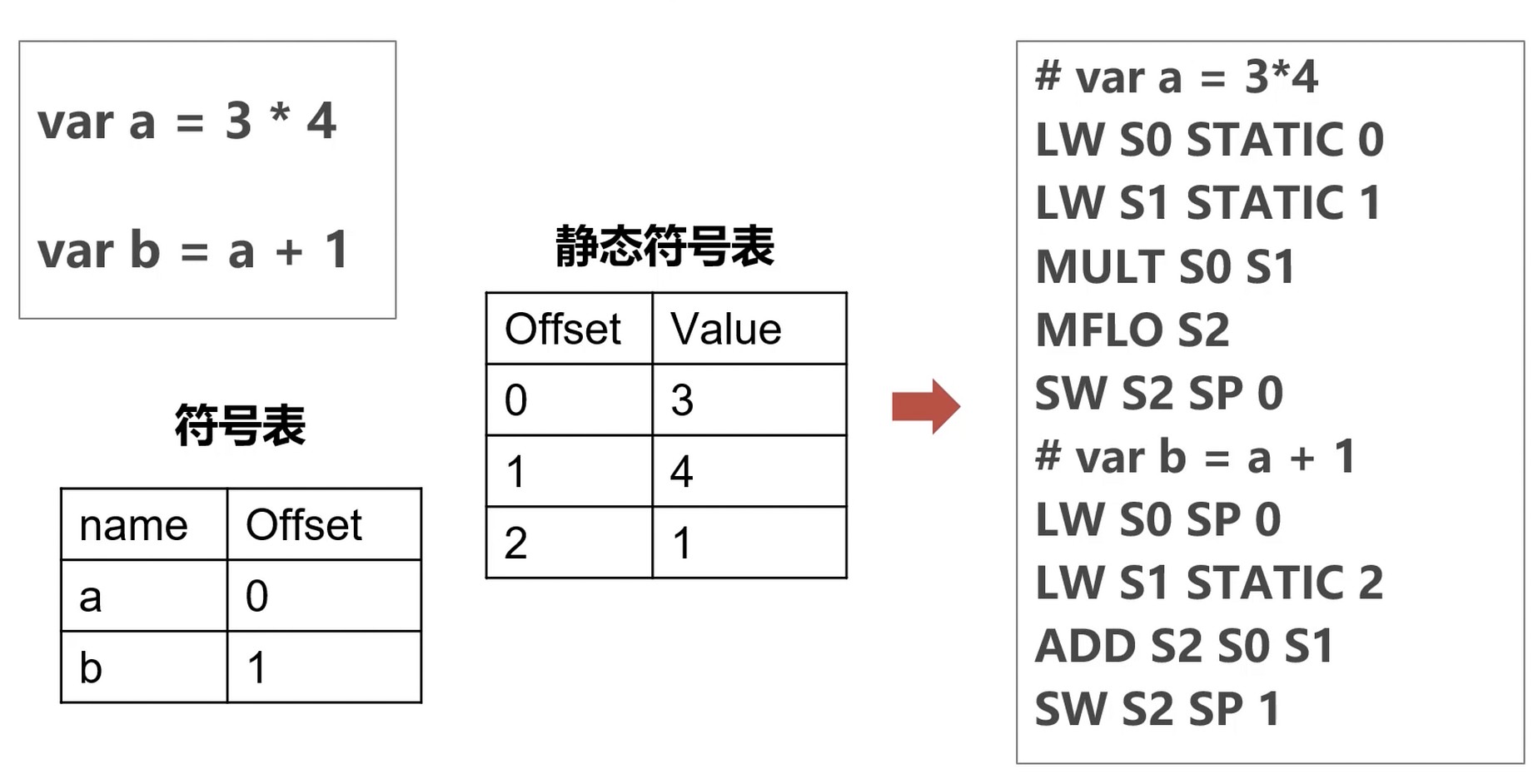
形成两个符号表. a和b之间应该还有个p0和p1.
LW S0 STATIC 0 : 读取静态符号表Offset为0的值并加载到内存中, 也就是从内存中把3存在S0寄存器.
MFLO : mult 的用法有点特殊, 会把计算结果放在 hi 和 lo 寄存器中(h-high, l-low), Move From Low, 把计算结果放在 S2
SW S2 SP 0 : 把结果存回 SP 寄存器(栈指针)
LW S0 SP 0 : 把a的值读到S0
ADD S2 S0 S1 : 把 S0 和 S1 的值相加存在 S2
goto类型
跳转类型
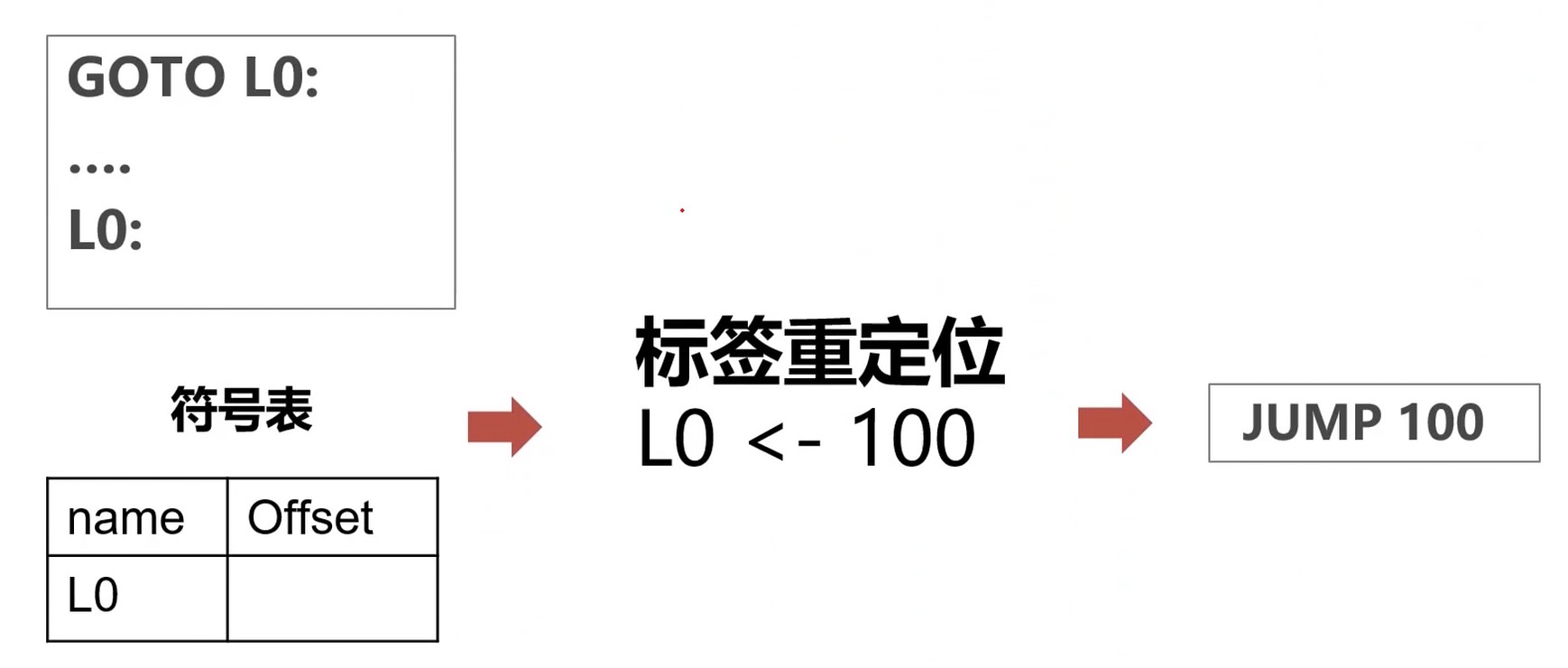
标签重定位过程发生在 generate 过程.
function类型
函数调用
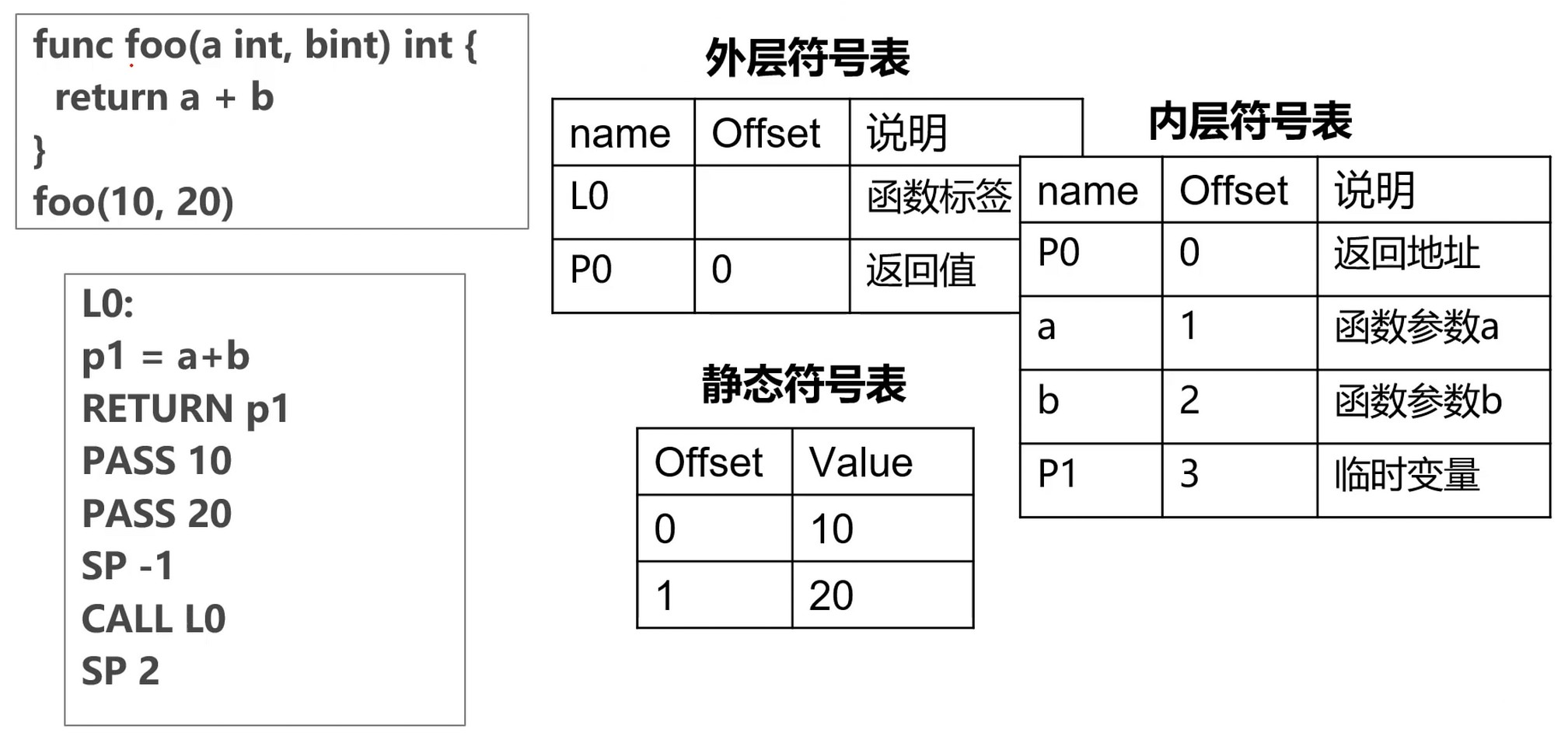
PASS 传参
SP -1 栈指针-1, 原来指的是外层符号表的P0位置, 因为外层和内层都在栈上, 而且是连续的, 而栈是从高位到低位的, 所以向上移动要-1
返回值在外层, 内层的是返回地址. 外层的返回值是内层来设定的.
SP 1 加一, 回到原来位置(上图有误)
传递参数a
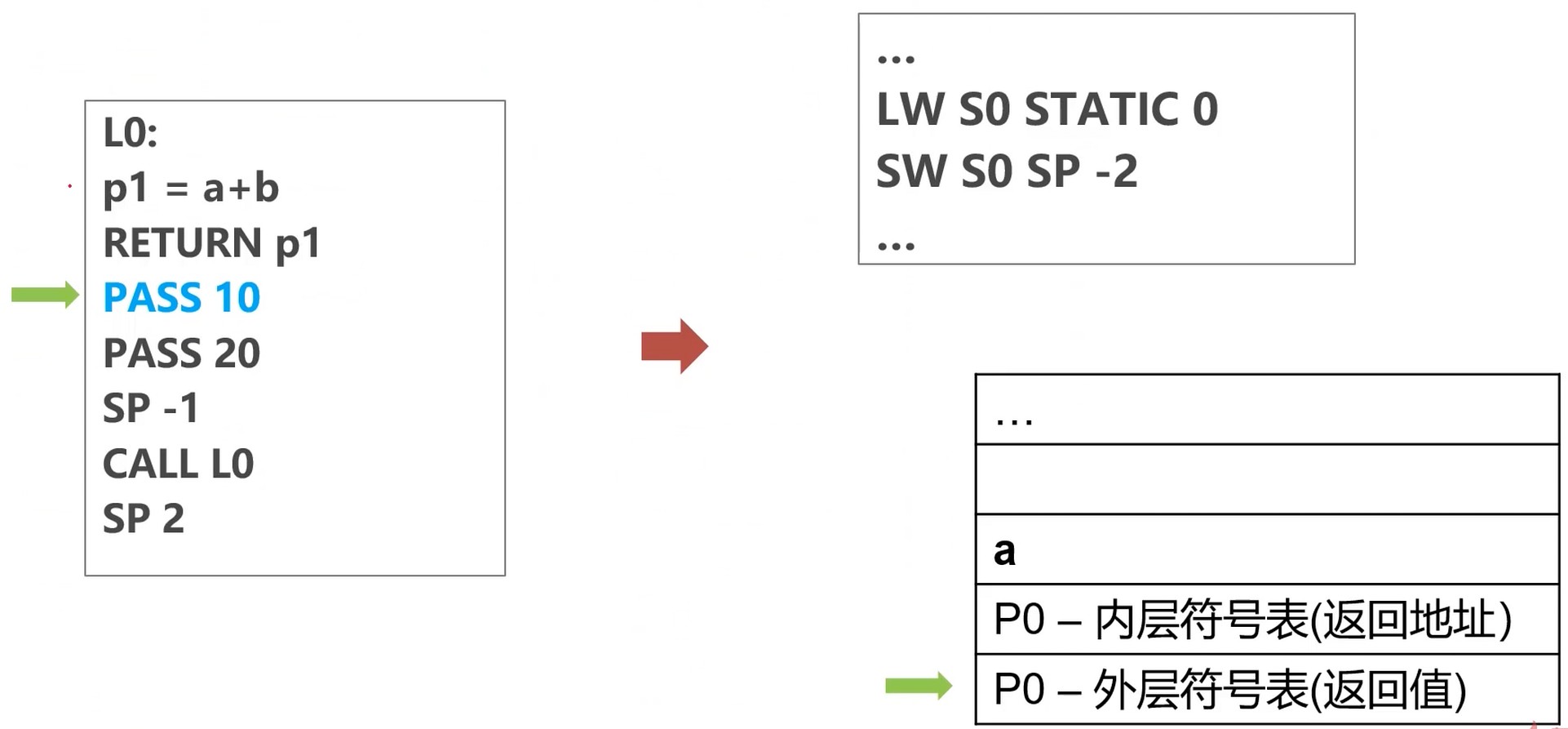
把a值存在 SP -2 的位置
传递参数b
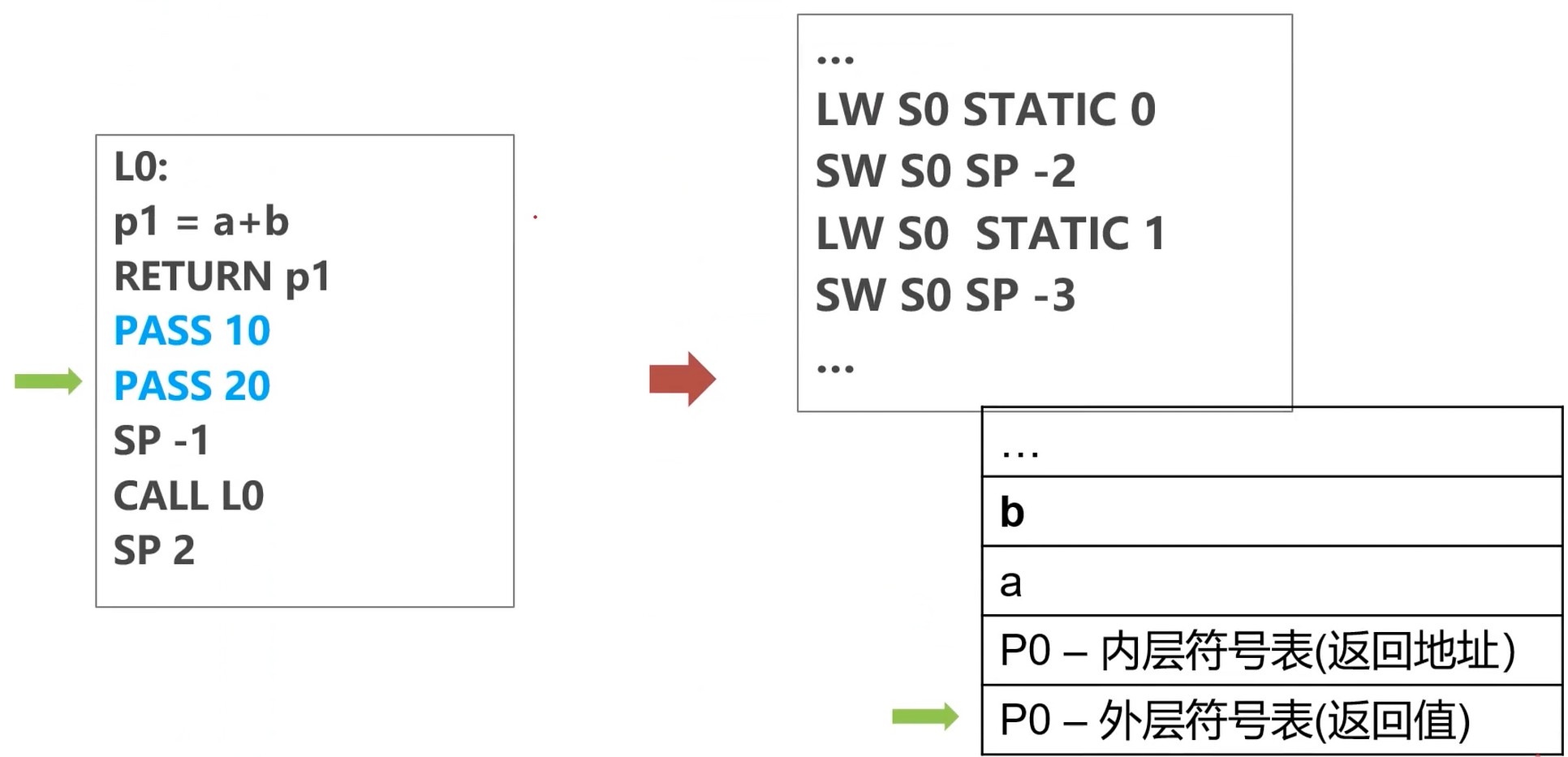
把b值存在 SP -3 的位置
创建活动类型
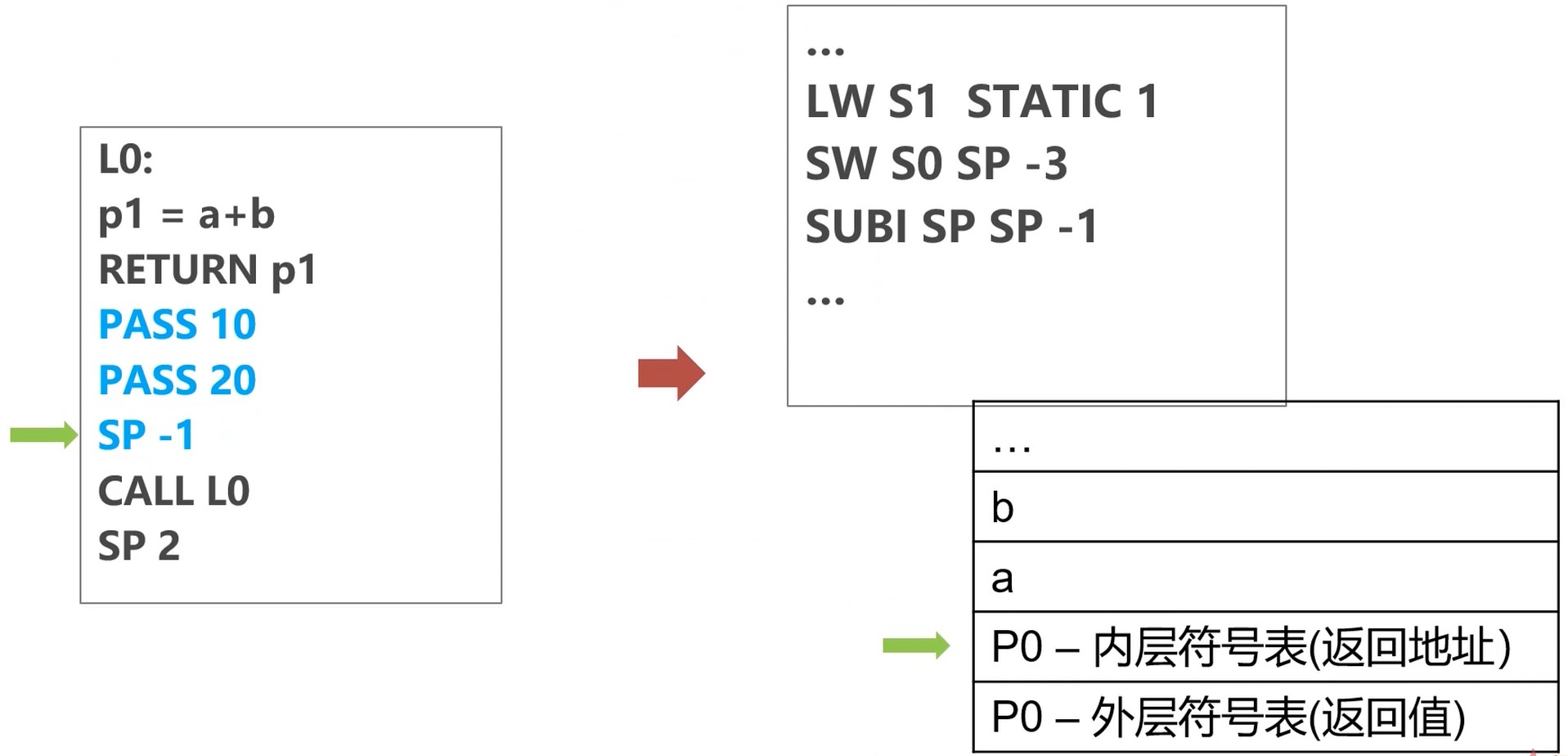
SUBI SP SP -1 : SP - 1
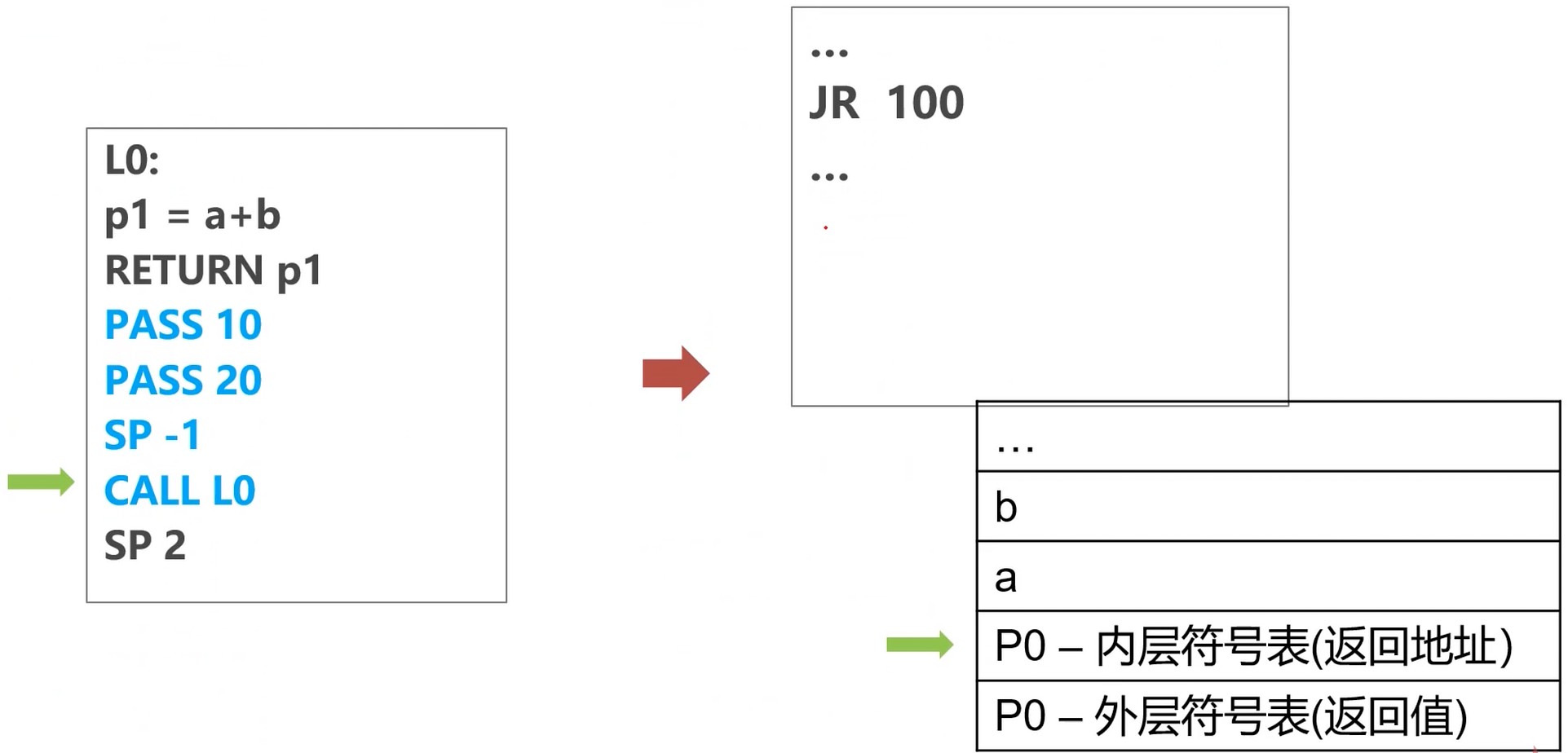
函数调用
计算a+b
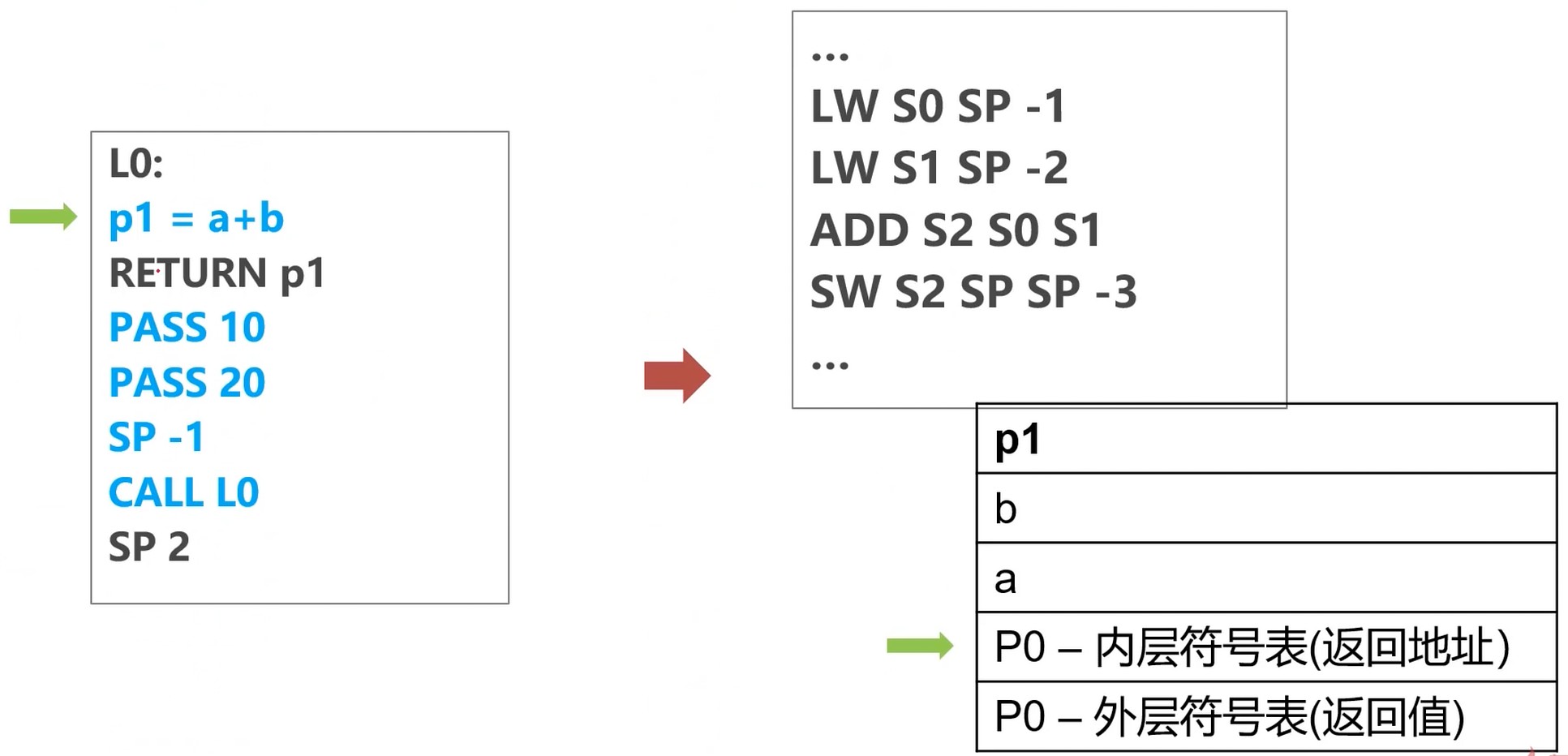
返回结果
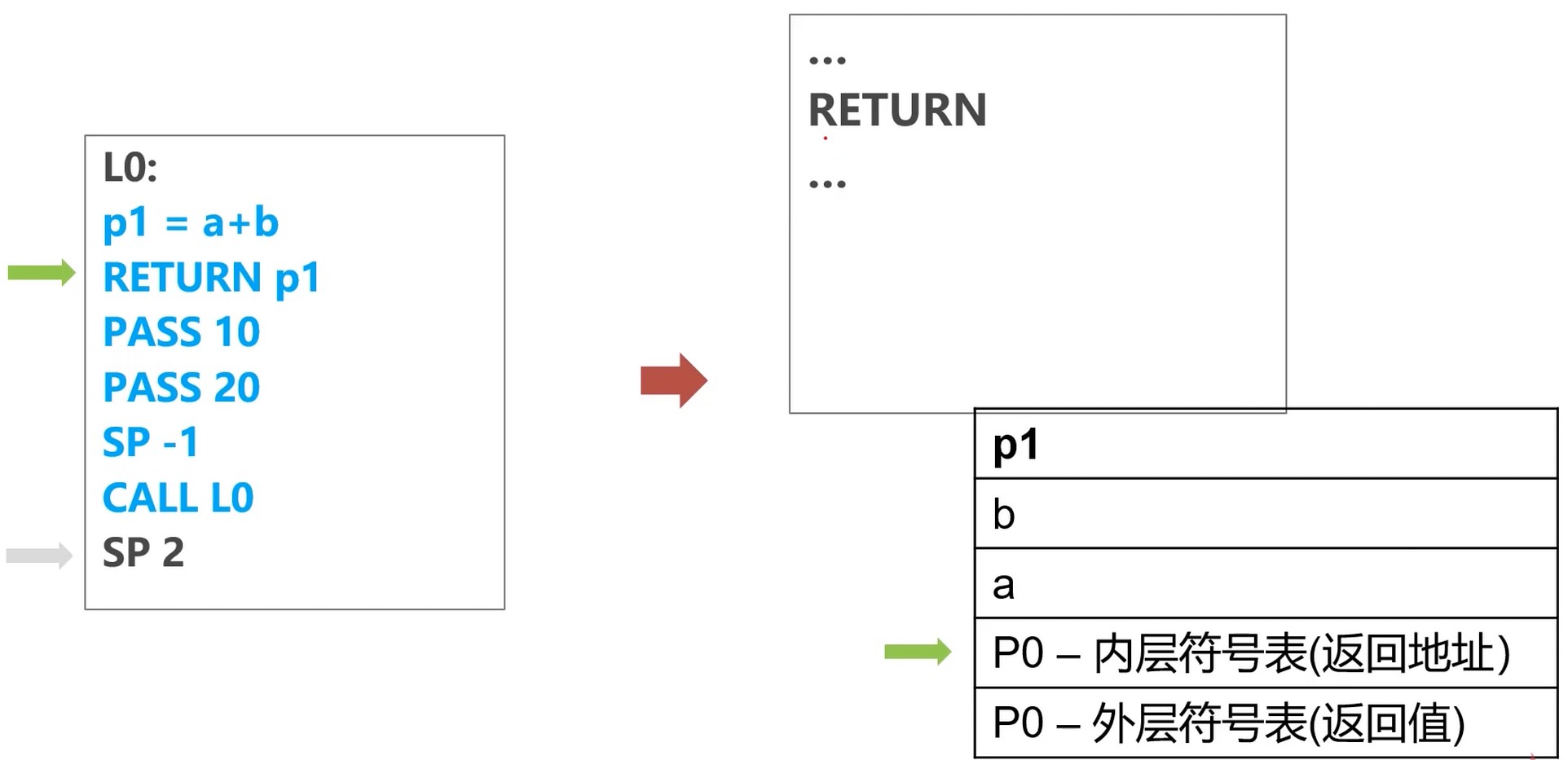
回收活动记录
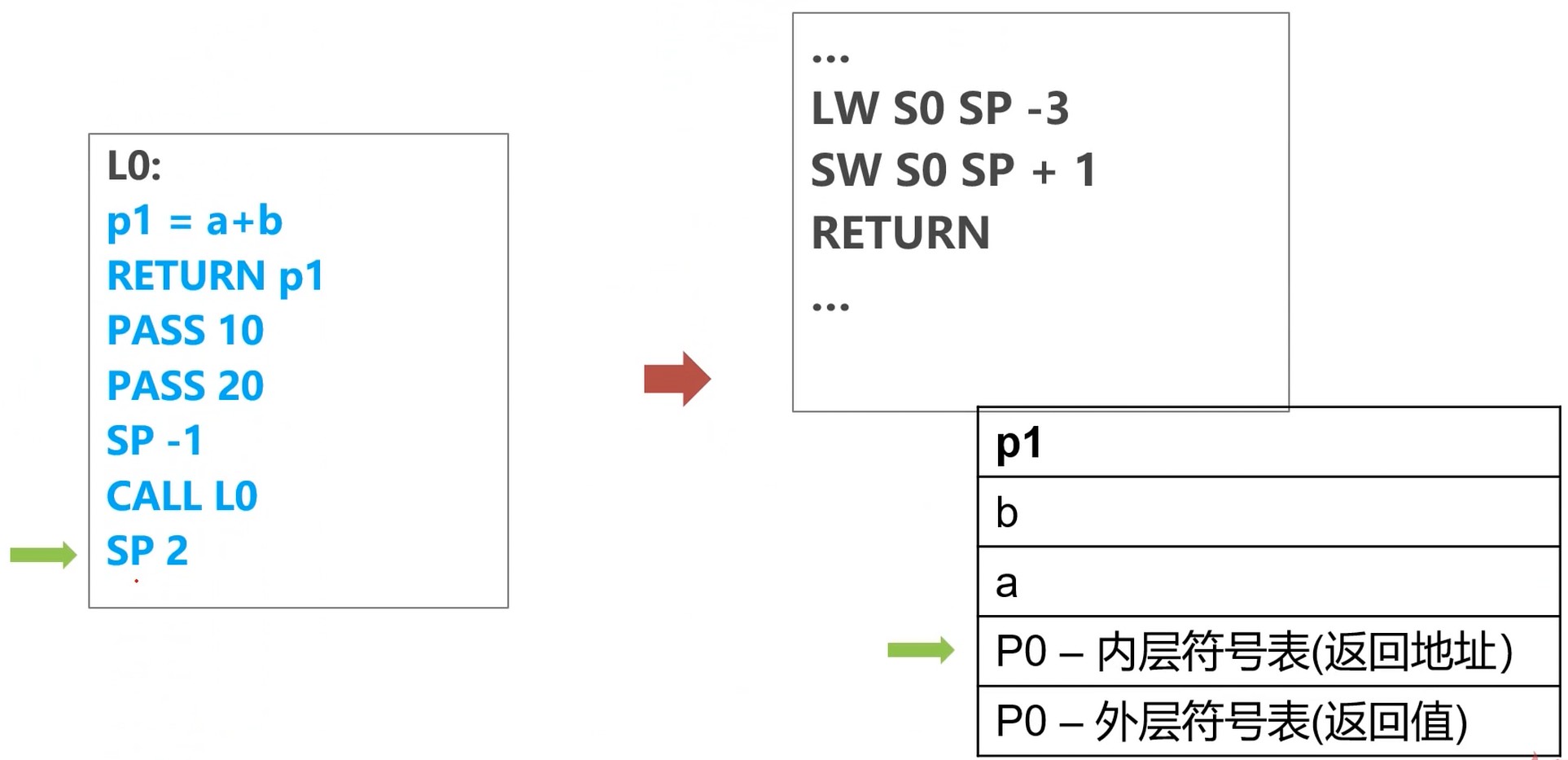
SP 1 加一, 回到原来位置(上图有误)
if语句
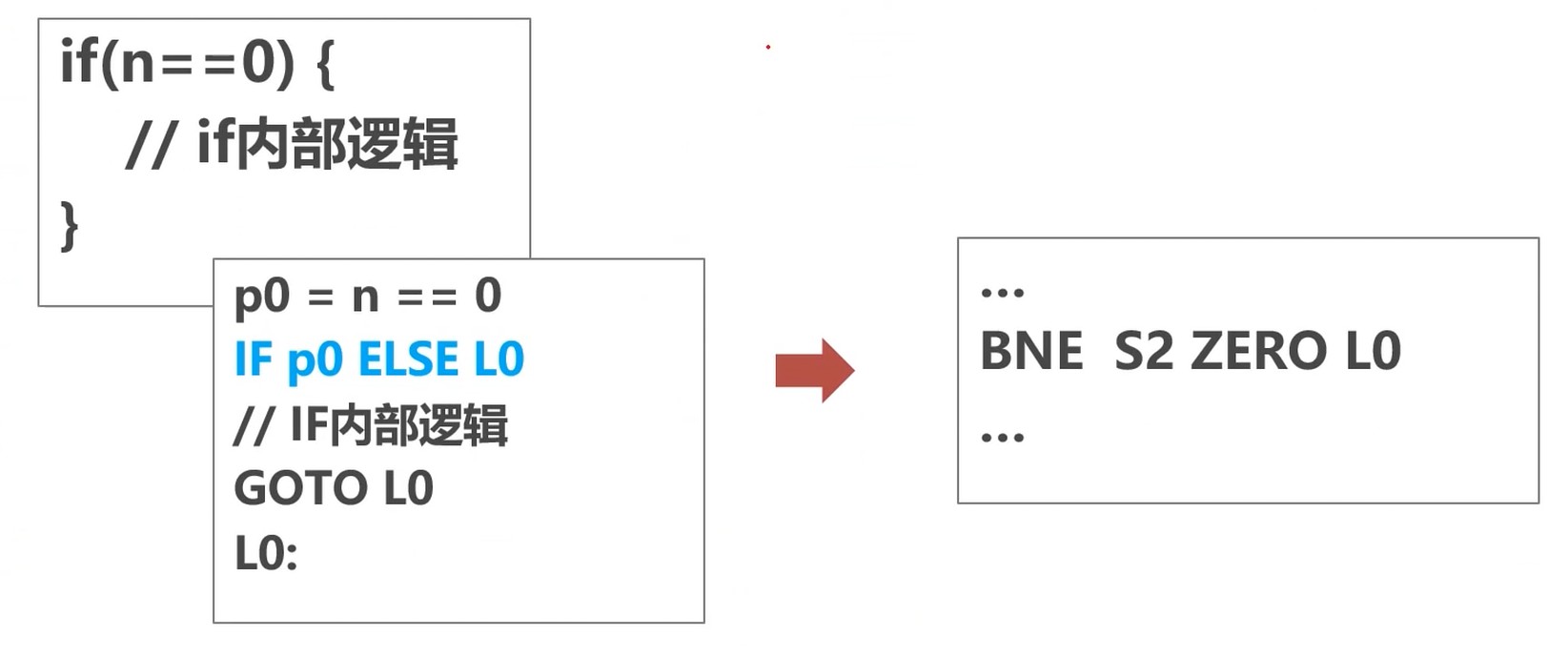
指令翻译过程
- 赋值语句和表达式生成指令
- IF语句生成指令
- 函数生成指令
- Unit Test
虚拟机指令的编码和解码
- 指令编码过程
- 指令解码过程
- UnitTest
虚拟机执行程序
- 虚拟机程序
- 表达式求值
- 函数求值
- Unit Test
位运算
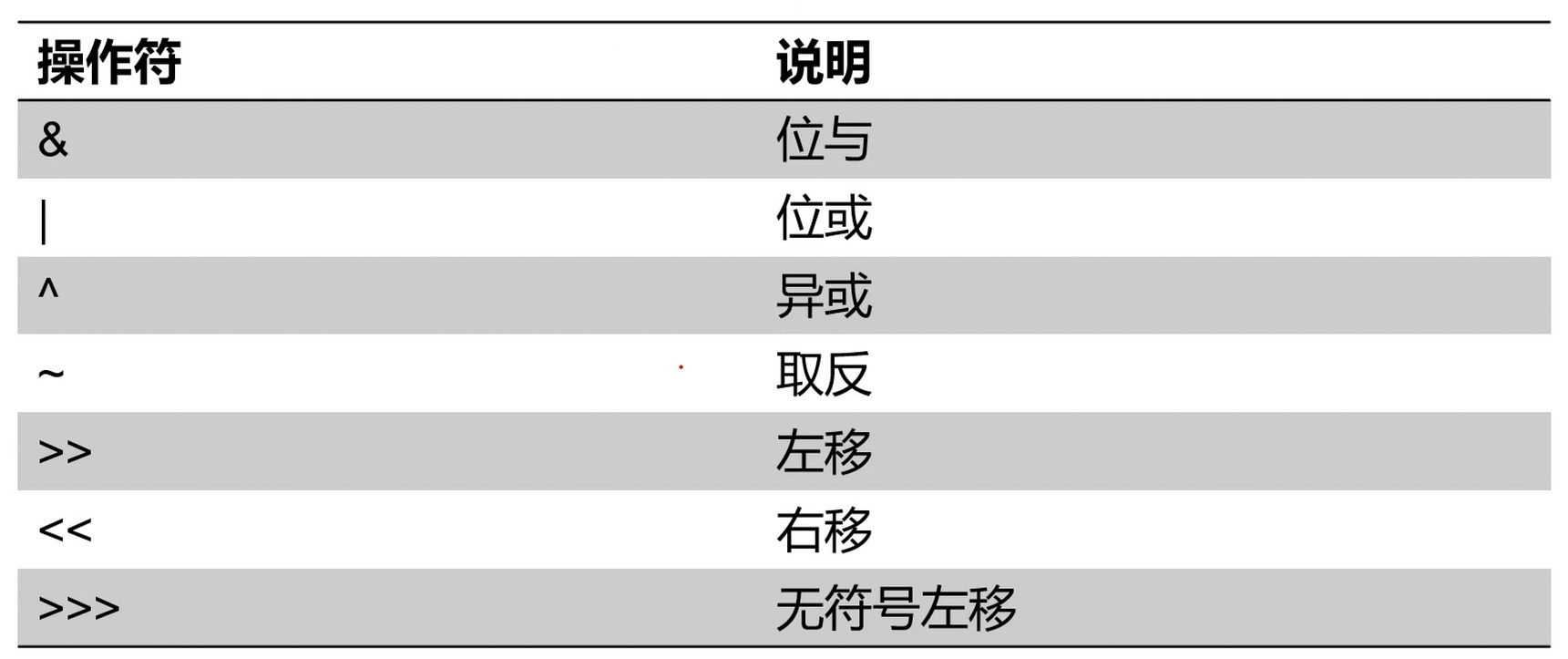
取反(~)

最高位是1就是负数.
负数怎么表示? 把 0xffffffff 看作 -1, 那么 0xfffffffe 就是 -2 了.
正负数互转.
位与(&)
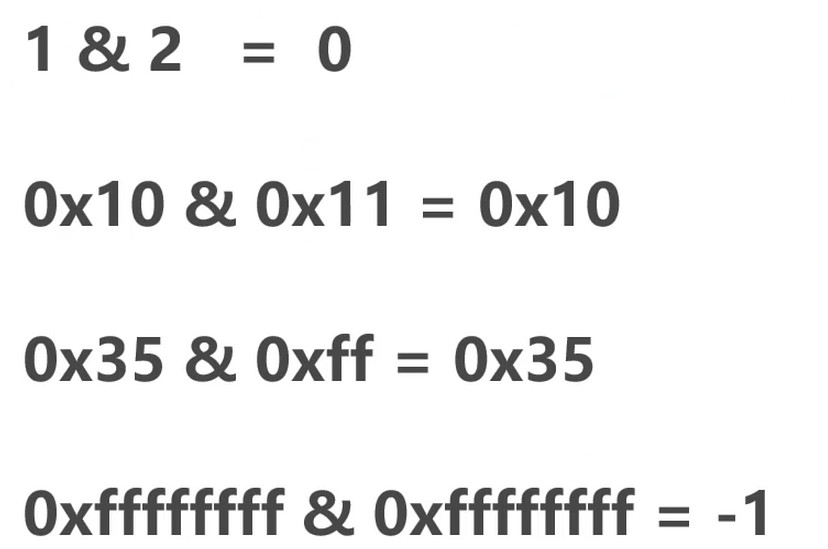
两个都是1才是1, 否则是0.
位或(|)
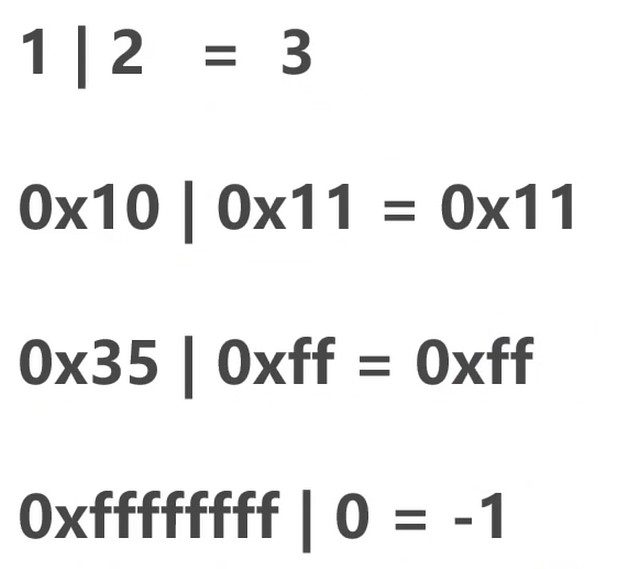
有一个是1就是1.
异或(^)
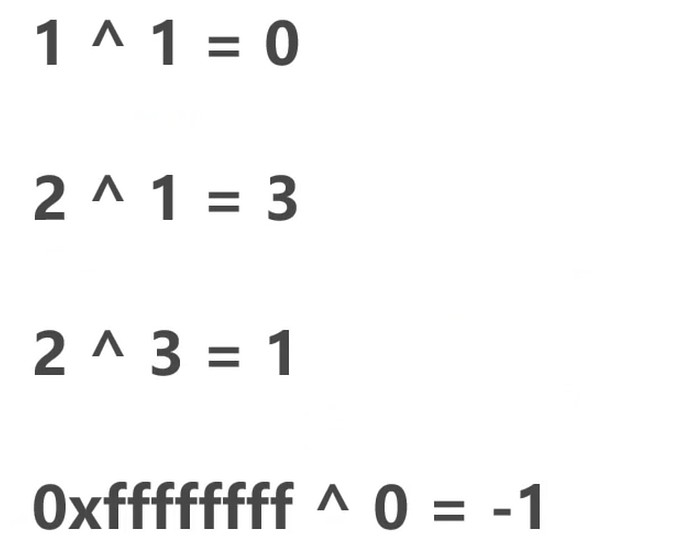
两个不一样才是1, 否则是0.
左移(<<)`

向左补一位0, 左移一位等于乘以2, 左移两位等于乘以2^2, 以此类推
右移(>>)

去掉右边一位. 负数右移最高位补1, 正数右移最高位补0. -1无论右移多少次都是-1
无符号右移(>>>)
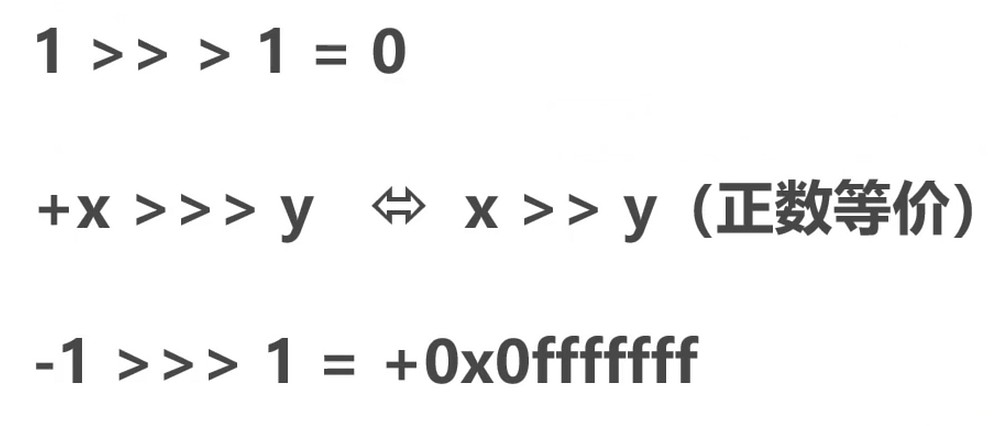
右移是无论正数还是负数都是补0的.
对于正数来说是一样的, 负数倒是不一样.
编译原理总结
知识迁移
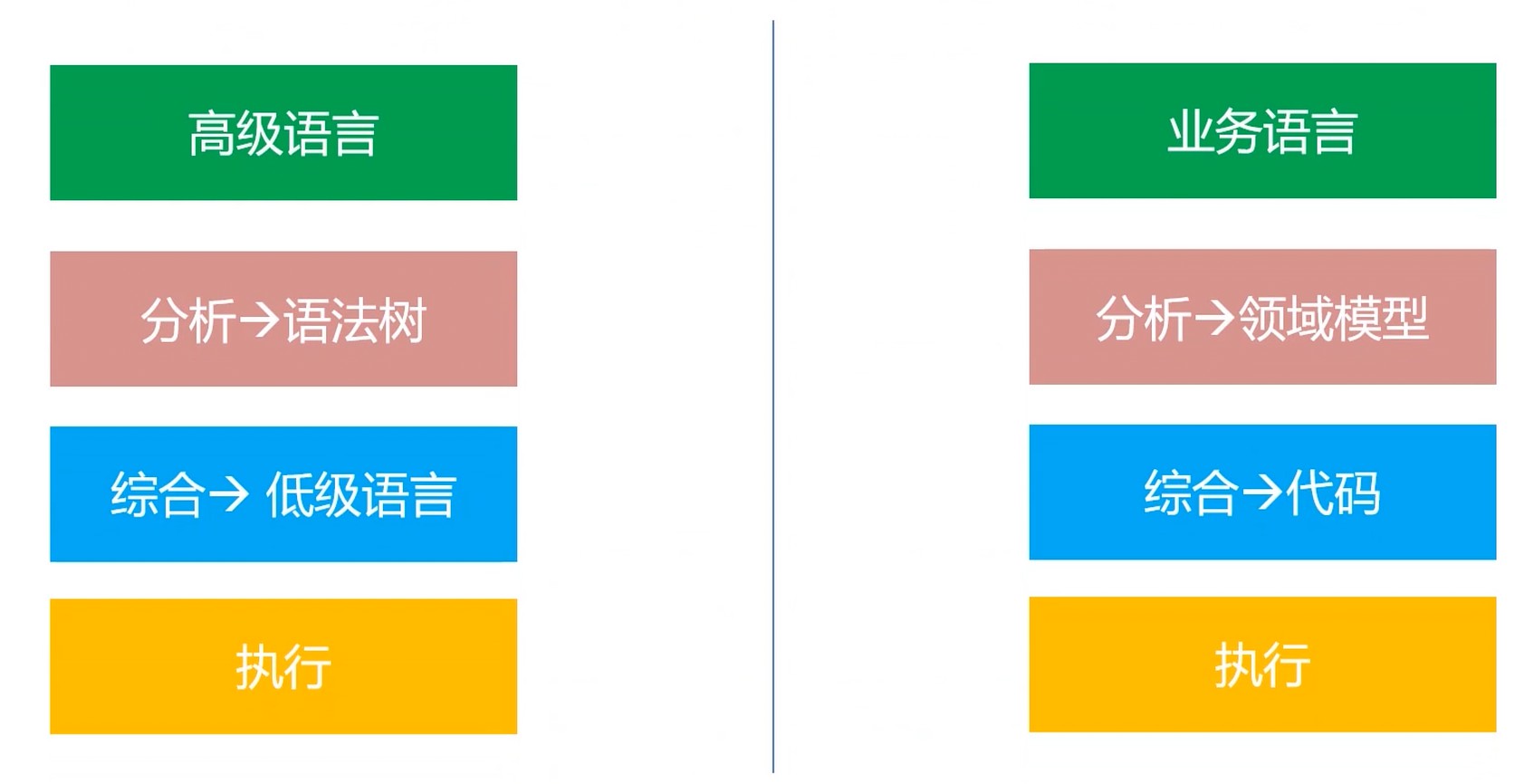
业务语言, 简单来说是需求文档, 但是又不是. 应该是更加标准, 更加领域化.
工程师不是把业务直接翻译成程序, 而是通过领域模型等一系列抽象生成代码.
分层设计(结构化, 分析, 综合)
- 分析
- 词法
- 语法
- 综合
- 翻译
- 代码生成
- 执行
- 分析
类型设计–类型抽象(AST, TA指令, 指令)
- 类
- 成员
- 方法
- 关系(继承, 组合)
算法
- 循环(状态机)
- 递归(产生式)
- 决策(遍历/查找/求值)
数据结构
- 链表
- 树
- 栈, 队列
- 图
底层知识
- CPU
- 指令
- 寻址
- 内存
- 栈
- 堆
- 寄存器
- CPU
一个优秀的架构师
- 领域足够认知
- 怎么分层/怎么设计类型
- 基础足够扎实
- 算法/数据结构
- 底层足够熟悉
- 操作系统/网络/计算机组成等
- 工具足够熟练


博客内容遵循 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 协议
本文永久链接是:https://blog.lgq51233.xyz/2019/09/27/%E7%BC%96%E8%AF%91%E5%8E%9F%E7%90%86/