
操作系统
操作系统
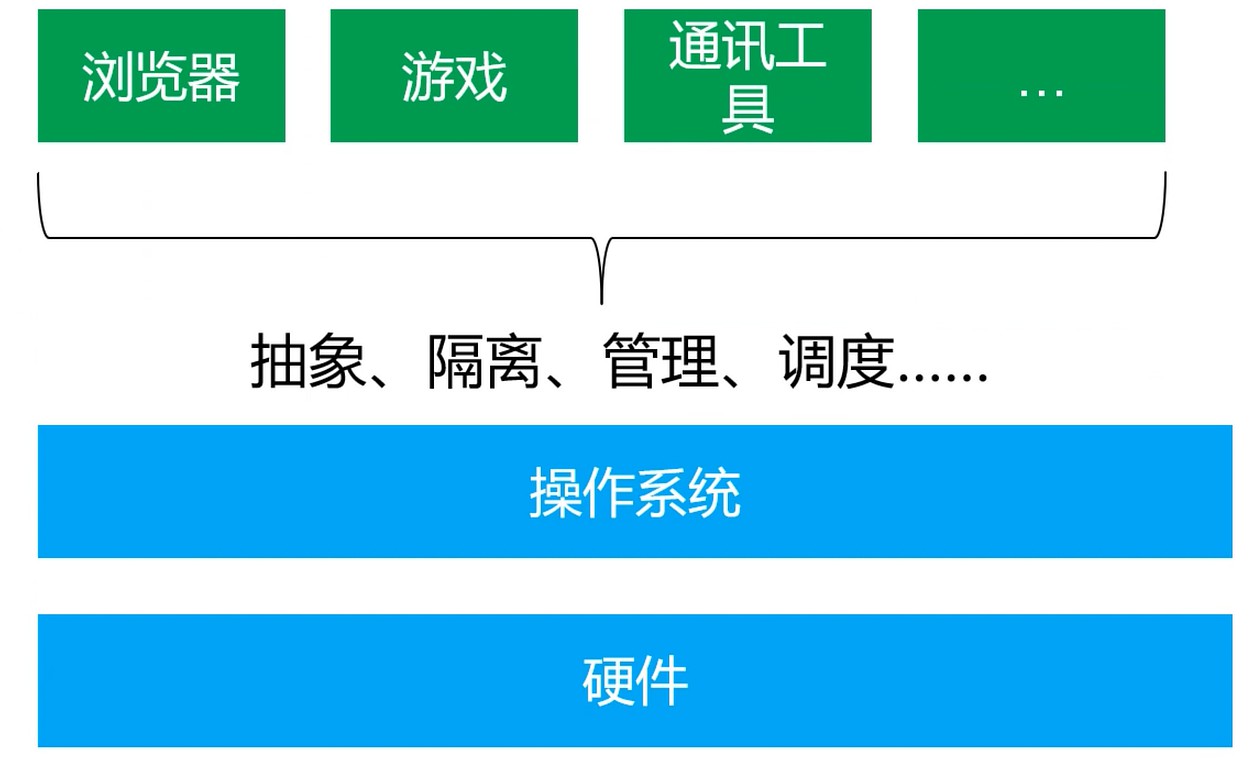
是统一管理计算机硬件和软件资源的计算机程序, 用于管理硬件, 提供用户交互的软件系统.
微内核设计 -> 微服务设计
操作系统历史

一台计算机工作不一定需要操作系统.
单板电脑(Single Board Computer, SBC), 例如: 树莓派(Raspery PI)
- 第一批计算机没有操作系统, 例如: ENIAC
- 大型机操作系统. 和现在的操作系统相比, 当时的更像库和框架
- 1969年 unix, 1990年开始普及
- 2000年MacOS发布第一个版本, 前身 Unix-like 的 Next step 系统
Android 操作系统
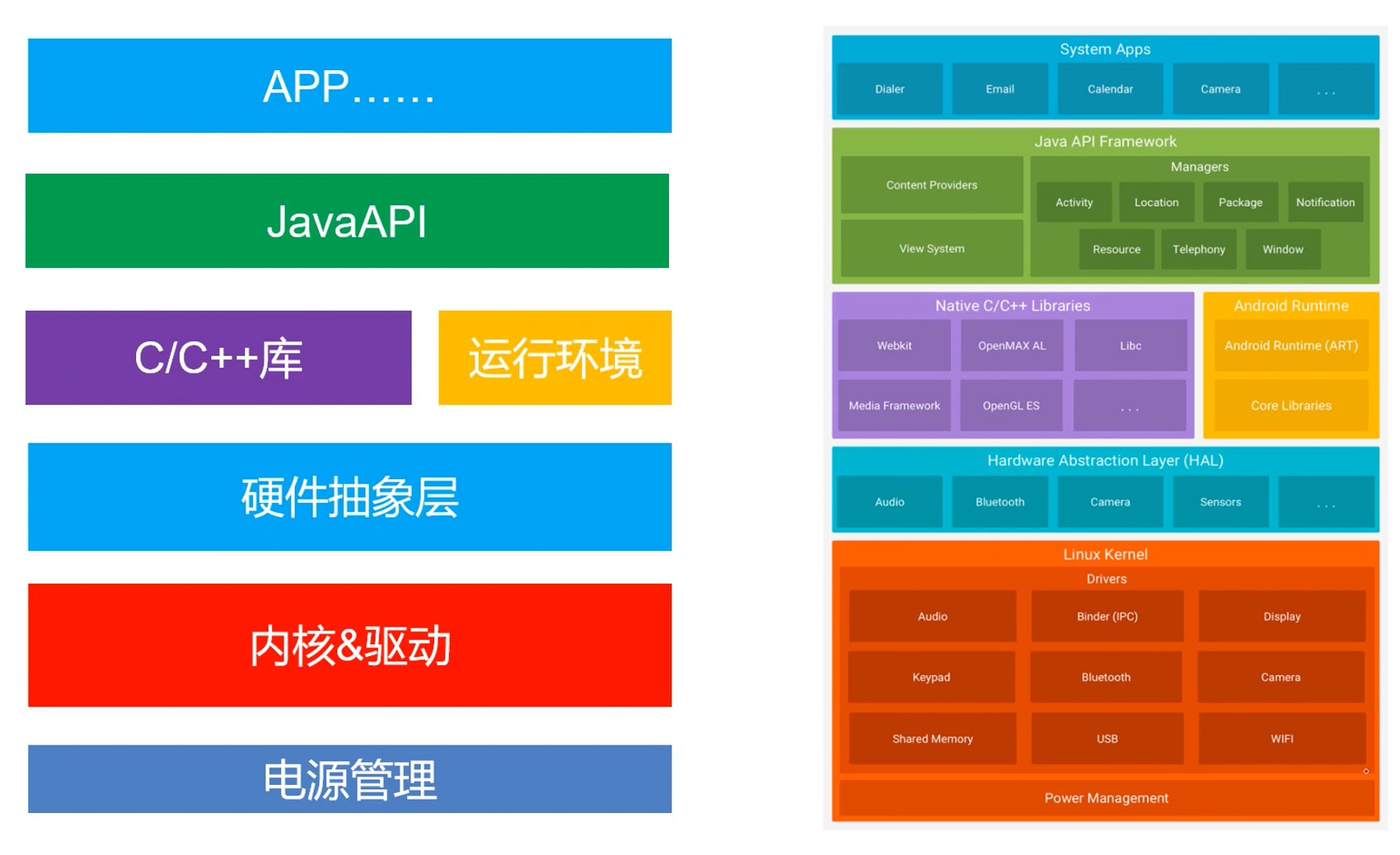
基本功能
处理器资源
存储器资源
IO设备资源
文件资源
一种程序
- 管理 硬件设备, 资源以及应用程序(管理能力)
- 将硬件能力, 资源抽象成服务让应用程序使用(抽象能力)
用户无需面向硬件接口编程
IO设备管理软件, 提供读写接口
文件管理软件, 提供操作文件接口
操作系统实现了对计算资源的抽象.
操作系统提供了用户与计算机之间的接口.
相关概念
- 并发性
- 并行: 指两个或多个事件在 同一时刻 发生
- 并发: 指两个或多个事件在 同一时间间隔 发生
- 通过 多道程序设计 实现
- 共享性
- 例如多个程序共享主存资源
- 资源共享
- 互斥共享
- 虚拟性
- 把物理实体转变为若干格逻辑实体
- 物理实体是真实存在的, 逻辑实体是虚拟的
- 虚拟计数主要有 时分复用技术 和 空分复用技术
- 异步性
- 在多道程序环境下, 允许多个进程并发执行
- 进程在使用资源时可能需要等待或放弃
- 进程的执行并不是一气呵成的, 而是以走走停停的形式推进
时间复用技术
- 资源在时间上进行复用, 不同程序并发使用
- 多道程序分时使用计算机的硬件资源
- 提供资源利用率
虚拟处理器技术
- 借助多道程序设计技术
- 为每个程序建立进程
- 多个程序分时复用处理器
虚拟设备技术
- 物理设备虚拟为多个逻辑设备
- 每个程序占用一个逻辑设备
- 多个程序可以通过逻辑设备并发访问
空分复用技术
- 实现虚拟磁盘, 虚拟内存等
- 提高资源利用率, 提升编程效率
虚拟磁盘技术
- 物理磁盘虚拟成逻辑磁盘
- 使用更加安全, 方便
虚拟内存技术
- 在逻辑上扩大程序的存储容量
- 使用比实际内存更大容量
- 大大提升编程效率
开机后需要接管CPU的控制权

MBR – 位于硬盘初始位置的一段记录, 也是一个程序.
DDR – Double Data Rate, 双倍速率.
需要接收和发送消息给硬件
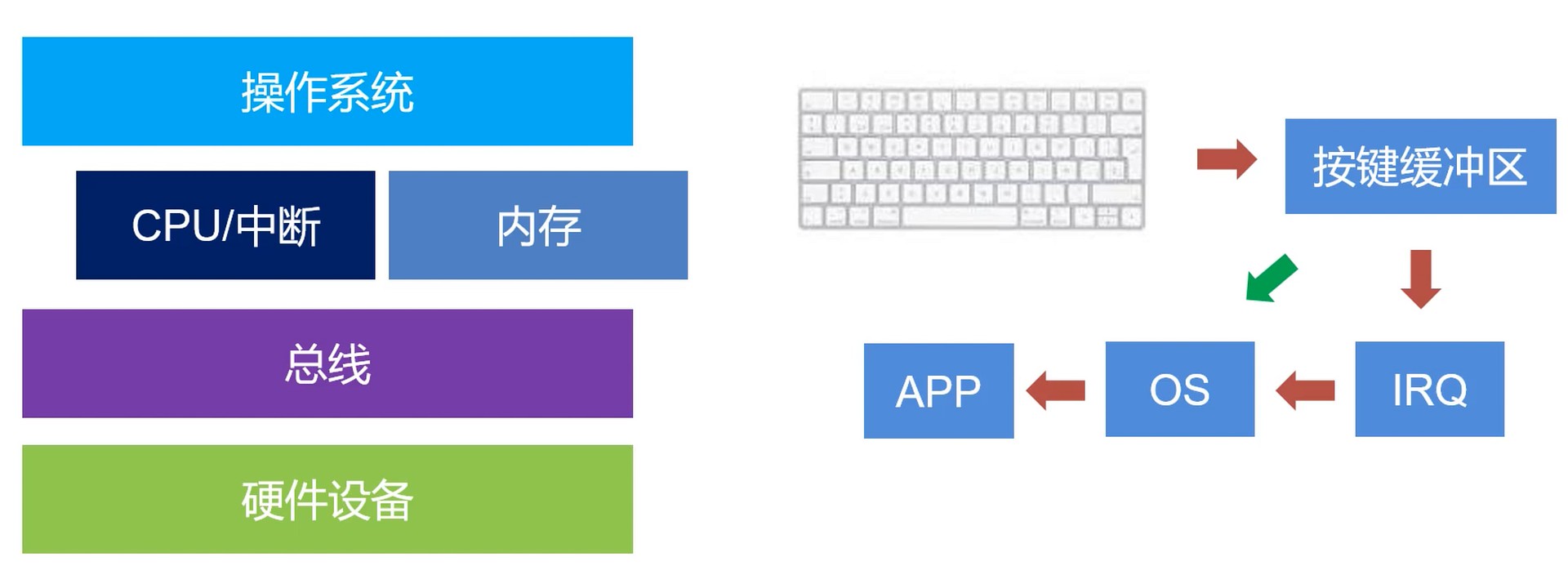
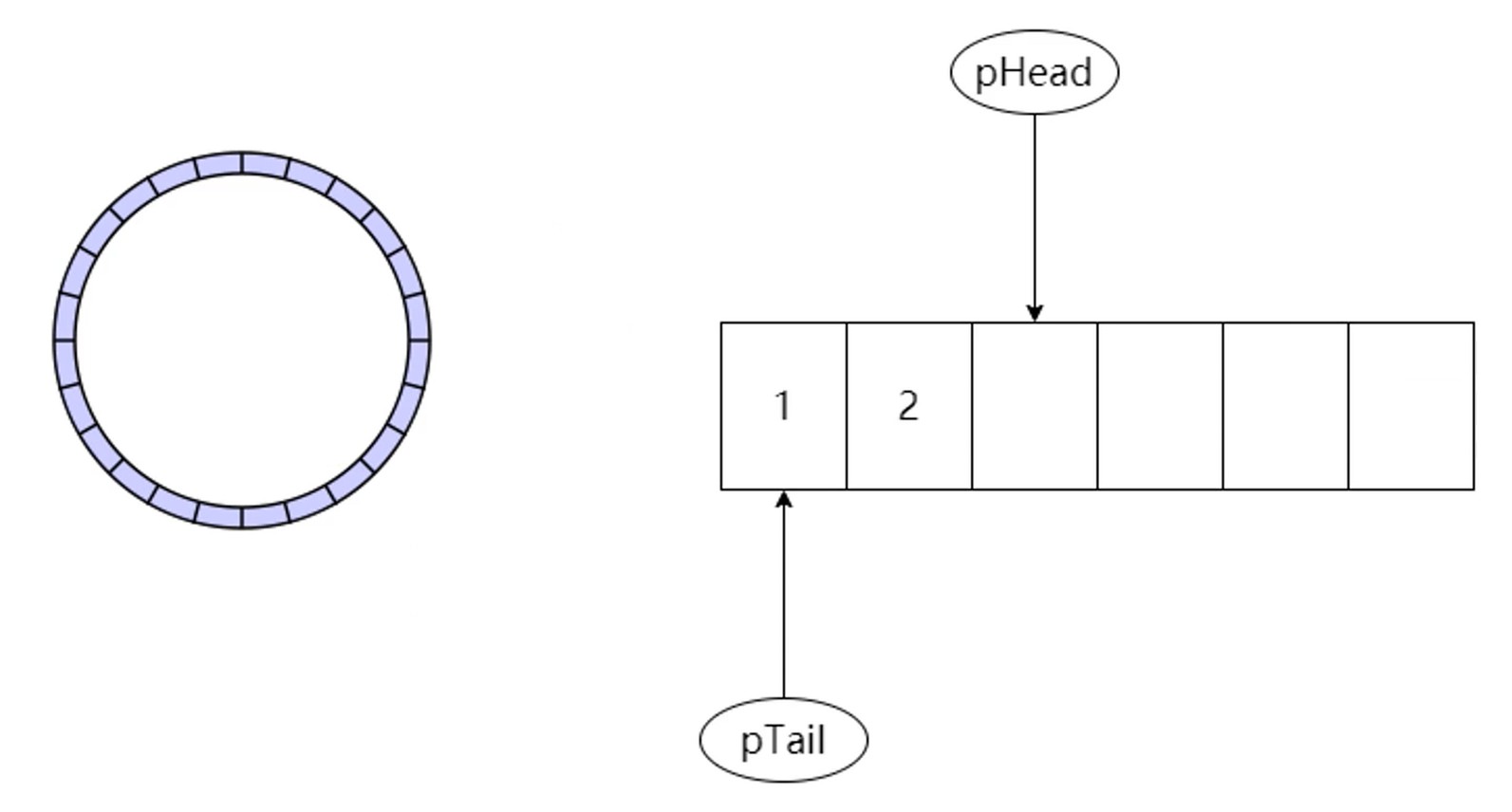
缓冲区. pHead 和 pTail 重叠就会发出鸣声. 通过 pTail 进行消费.
需要管理和调度应用
抽象是多方面的, 比如应用, 文件, 资源等…
需要让用户可以参与管理
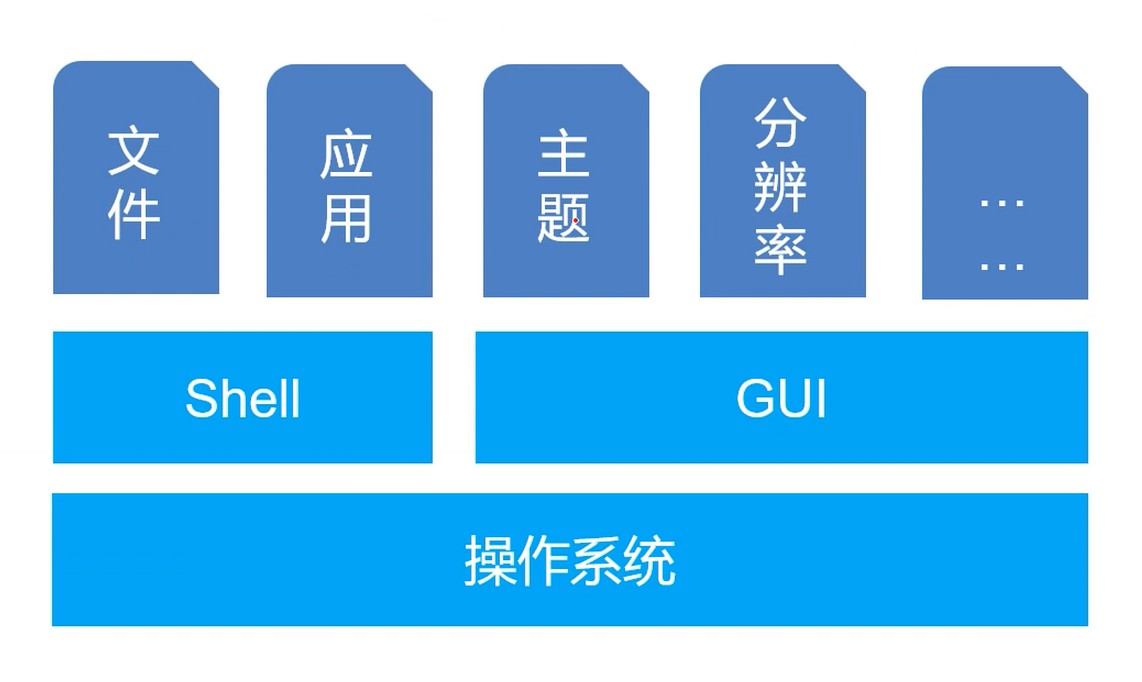
内核
- 内核是连接操作系统和硬件和软件的桥梁, 它掌控着计算机的一切资源.
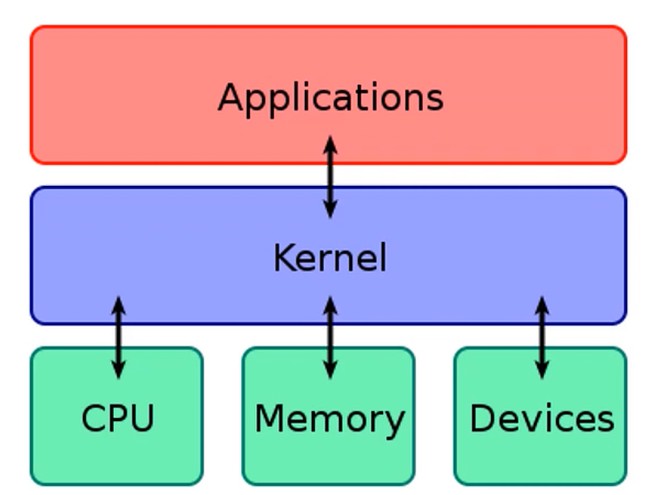
主流操作系统的设计

权限问题
- 没有权限控制
- 解决方案
- 拆分权限(端口权限, 文件权限, 操作权限等)
- 一个过程多态–区分[内核态][用户态]
用户态: 模拟用户在操作系统, 权限会较低.
切换到内核态时, 会做权限的检查.

Console/Terminal/TTY

内核设计: B/S结构设计
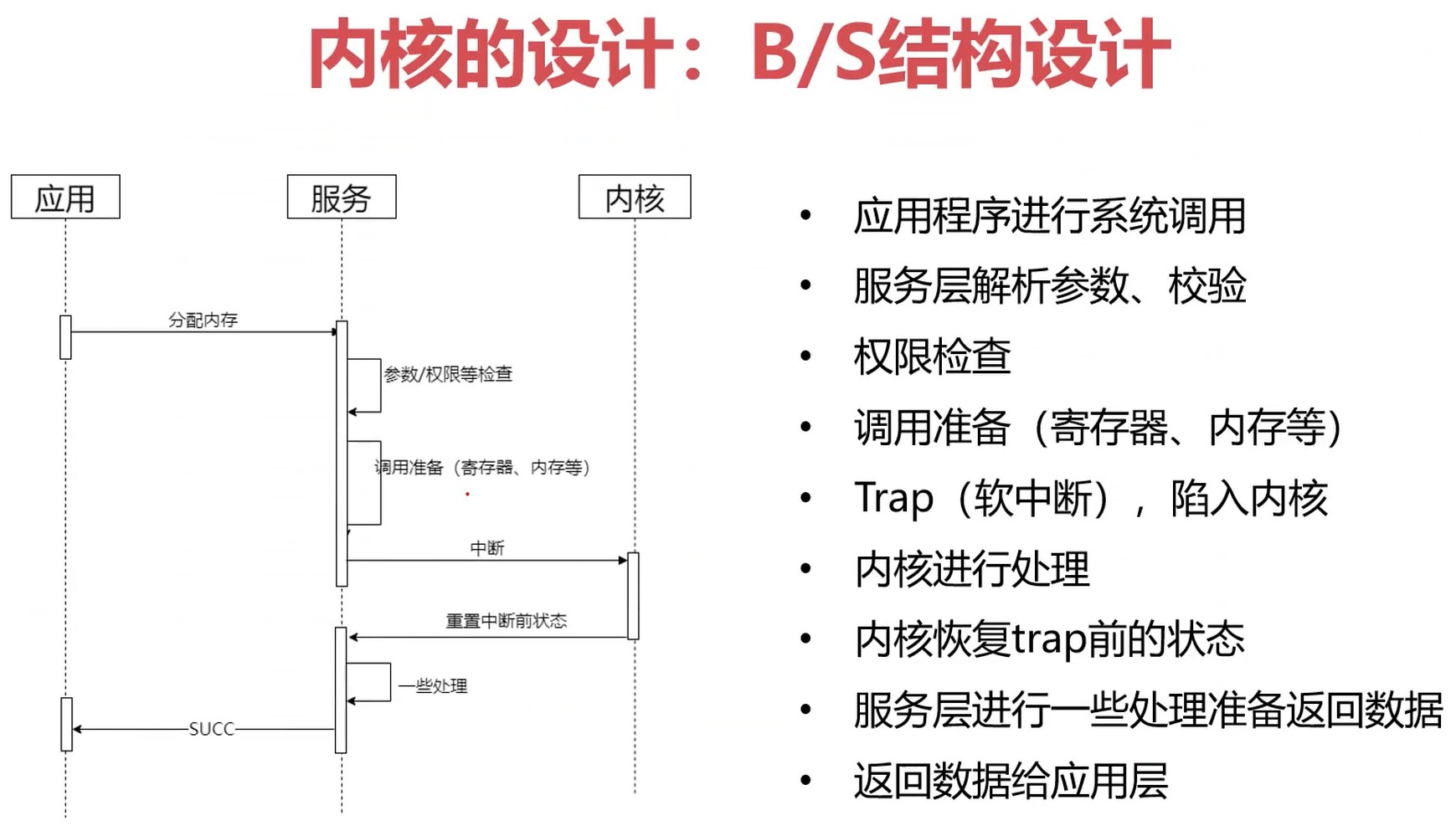
分配内存是一个有中断参加的过程.
- 内核管得越少, 扩展性就越强. 比如说调度算法, 文件系统得扩展性.
- 类比现实系统的设计也是如此, 分布式系统最底层是在做日志的记录(账簿系统), 游戏引擎的最底层是在做渲染 – 底层做的事情要少而精.
- OSI有7层模型.
- 程序语言的最底层是机器指令, 最上面是高级语言.
进程管理
- 进程是系统进行资源分配和调度的基本单位.
- 系统系统对一个正在运行程序的抽象, 是操作系统调度的最小单位. 一个应用可以有多个进程.
- 早期计算机CPU核心只有一个, 程序在共享时间片段, 操作系统需要提供一个模型去管理所有程序, 所以就诞生了最核心的概念.
- 进程作为程序独立运行的载体, 保障程序的正常执行.
- 进程的存在使得操作系统资源利用率大幅度提升.
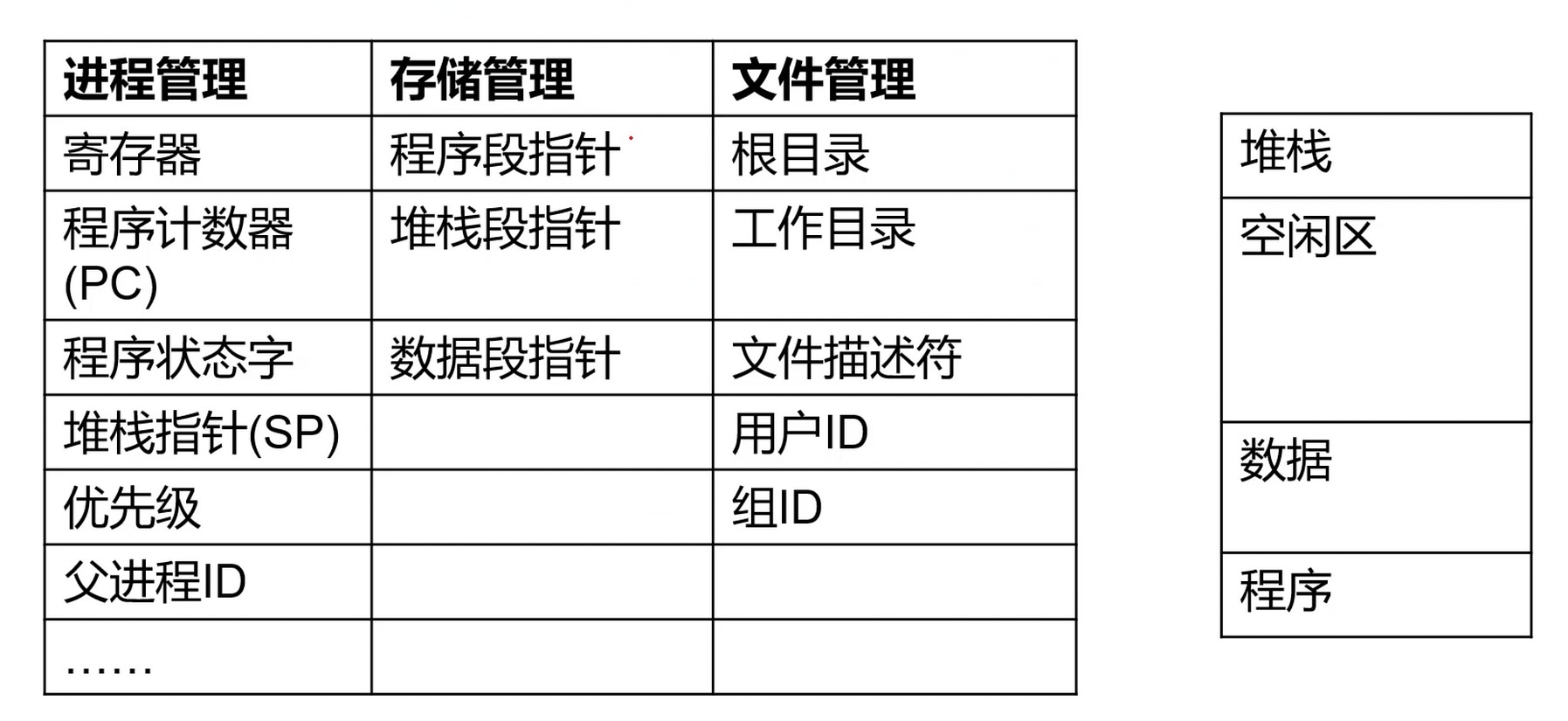
进程管理的 寄存器, 是用来维护当被暂停时, 存储当前的程序指针.
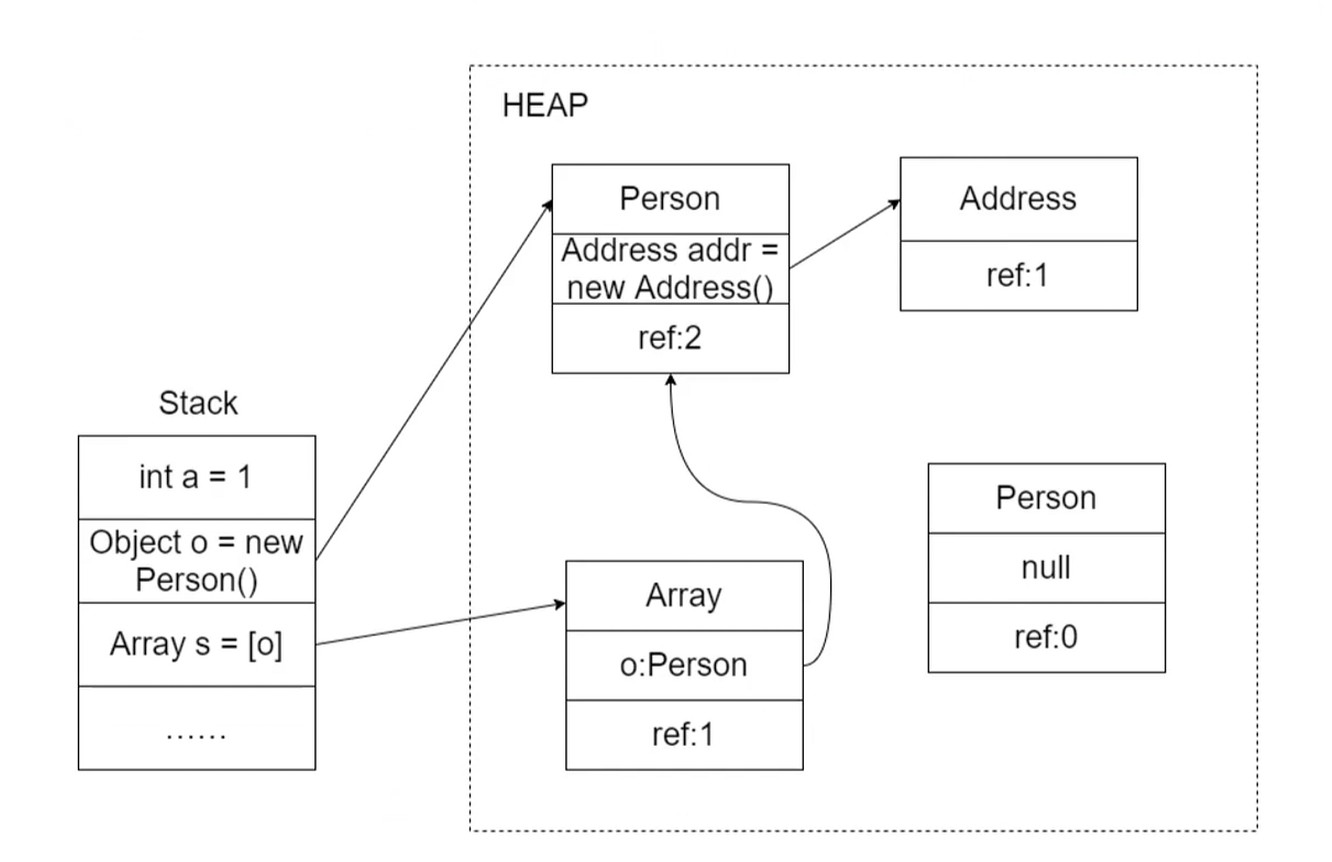
这样看来, 其实进程是一个数据结构.
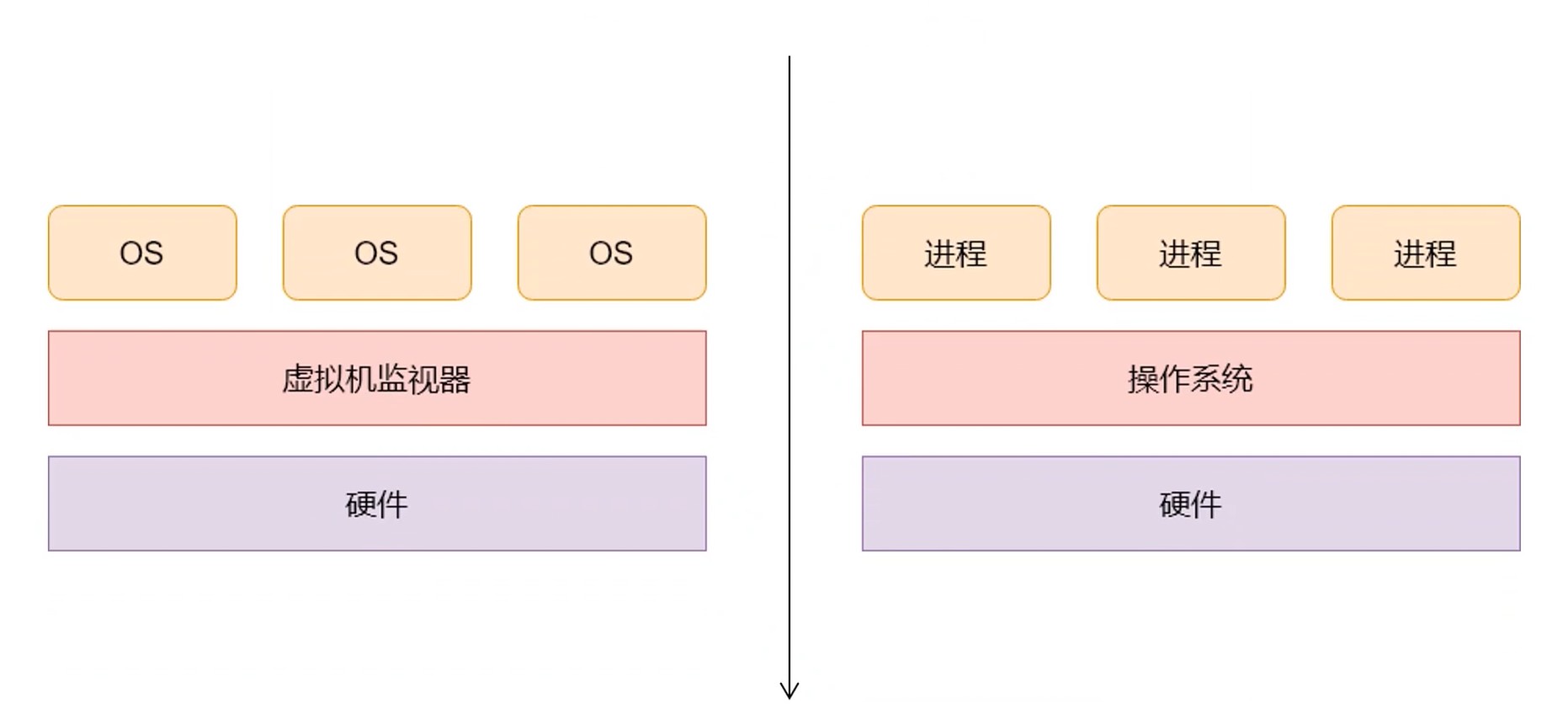
进程是对计算机的一种抽象, 是在软件上搭建的系统. 模拟, 映射着计算机相关资源.
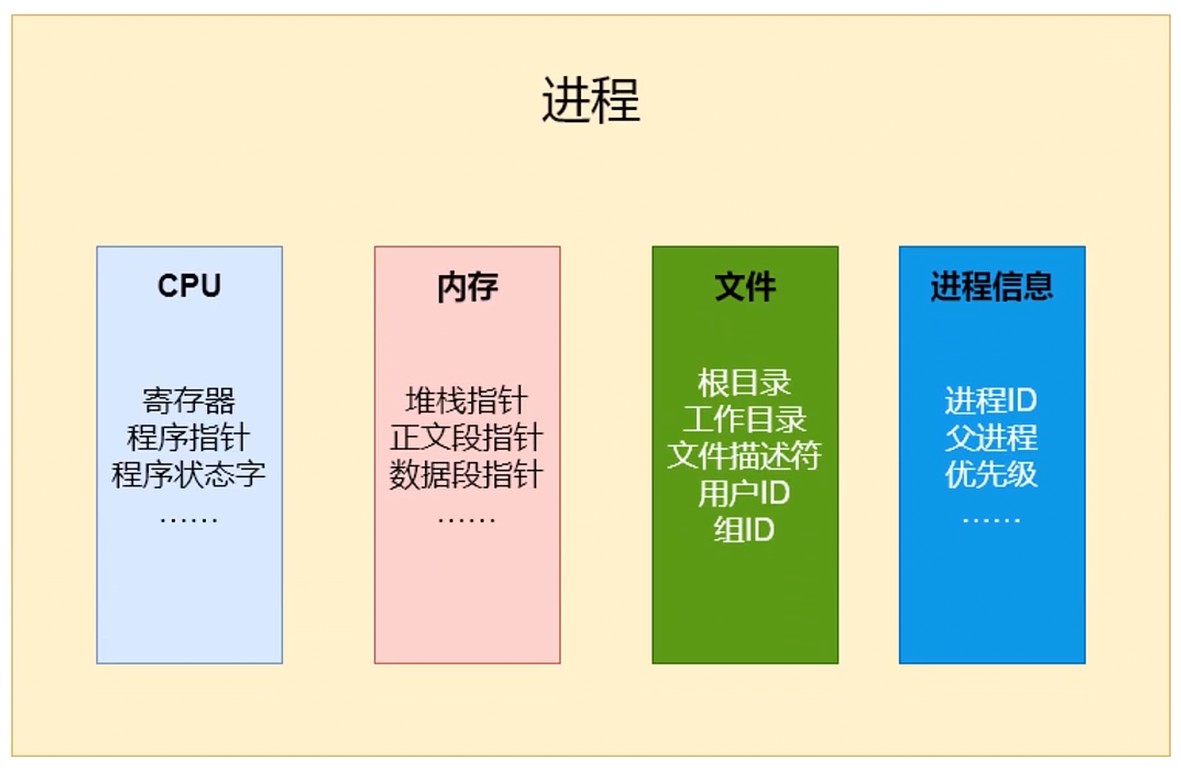
与虚拟机对比
进程的实体
进程控制块(PCB): 描述和控制进程运行的通用数据结构. 记录当前状态和控制进程运行的全部信息.
PCB是进程能够独立运行的基本单位.
PCB是操作系统进行调度经常被读取到的信息.
PCB是常驻内存, 存放在系统专门开辟的PCB区域内.
- 标识符, 唯一标记一个进程, 用于区别其它进程.
- 状态, 如运行态.
- 程序计数器, 指向进程即将被执行的下一条指令的地址.
- 内存指针, 程序代码, 进程数据相关指针.
- 上下文数据, 进程执行时处理器存储的数据.
- IO状态信息, 被进程IO操作所占用的文件列表.
- 记账信息, 使用处理器时间, 时钟总和等.
总结上面一共四类
- 进程标识符
- 处理机状态
- 进程调度信息
- 进程控制信息
进程之间通信–IPC
线程
进程–Process, 线程–Thread
轻量级的进程, 是抽象计算的, 是分配计算资源的最小单位. 进程是分配资源的最小单位.
一个经常有多个线程.
- 线程是操作系统进行运行调度的最小单位.
- 包含在进程之中, 是进程实际运行的工作单位.
- 一个进程可以并发多个进程, 每个线程执行不同的任务.
进程的线程共享进程的资源.
思考: 多进程分时共享
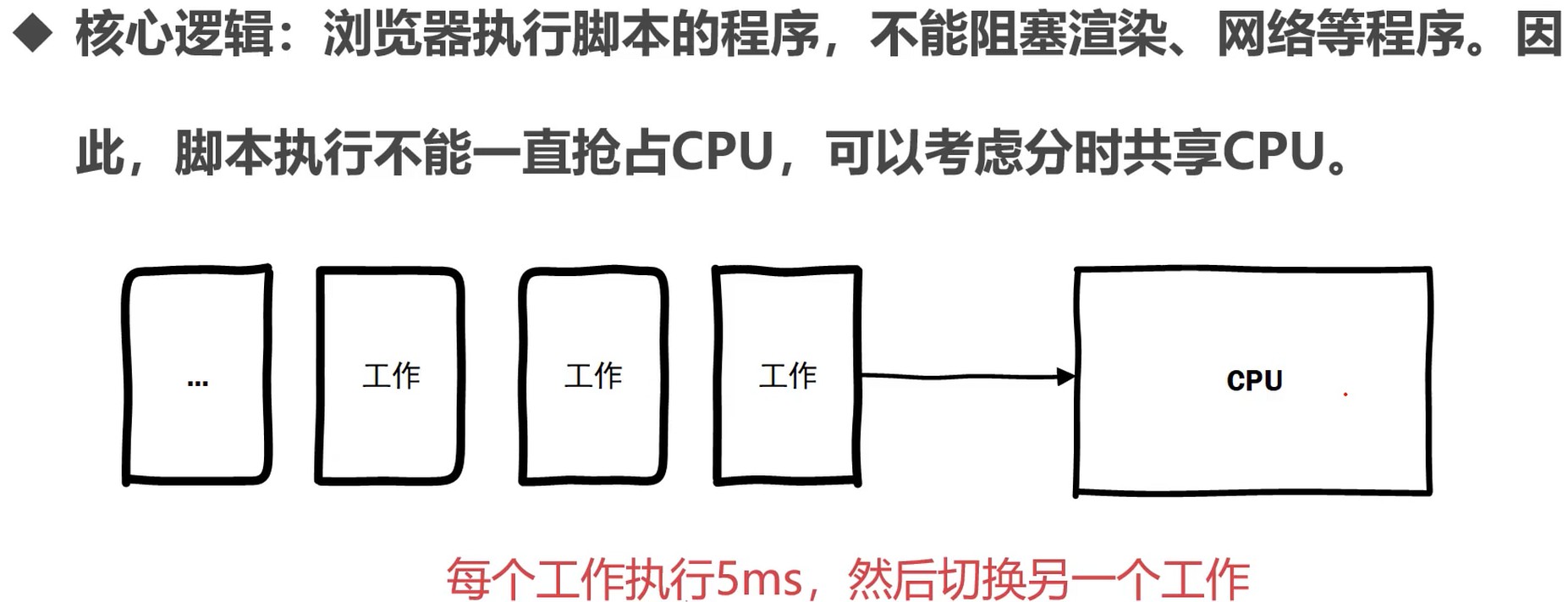
上面方案产生的问题:
- 多个进程如何共享文件和内存
- 多个进程间的切换成本
所以, 在进程中创造一种更加轻量的执行单位, 它们共享进程绝大部分信息, 拥有独立的程序指针, 堆栈, 寄存器, 状态字等.
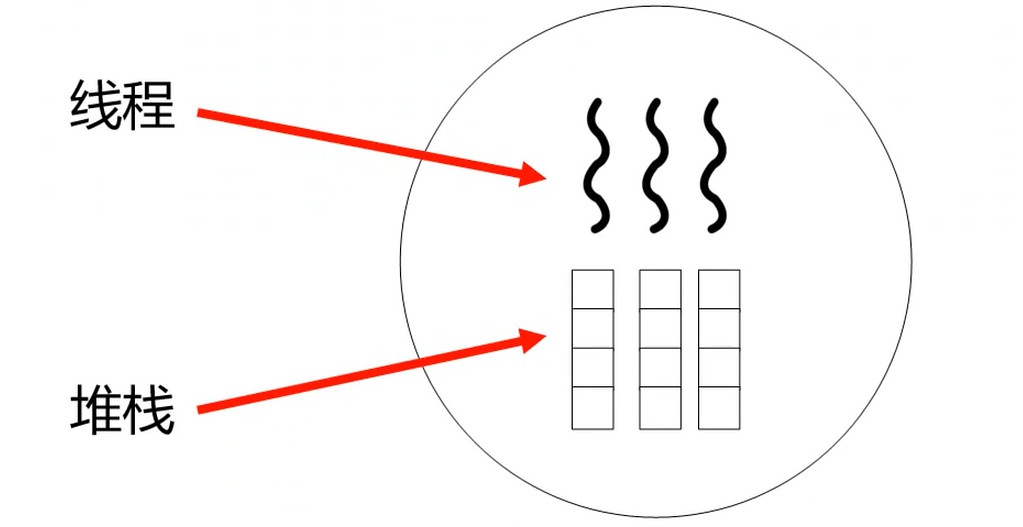
执行单元, 可以理解为抽象出一块CPU. 线程更加轻量, 所以切换成本更低.
POSIX = Portable OS Interface, 接口就是相同事物的行为.
报错 /mnt/e/WorkSpace/my-code-base/Computer/os/thread/main.c:21: undefined reference to 'pthread_create', 如果使用 gcc 编译时添加-lpthread参数, 如果是使用 cmake 的话, 在 CMakeLists.txt 文件中添加set(CMAKE_C_FLAGS -pthread).
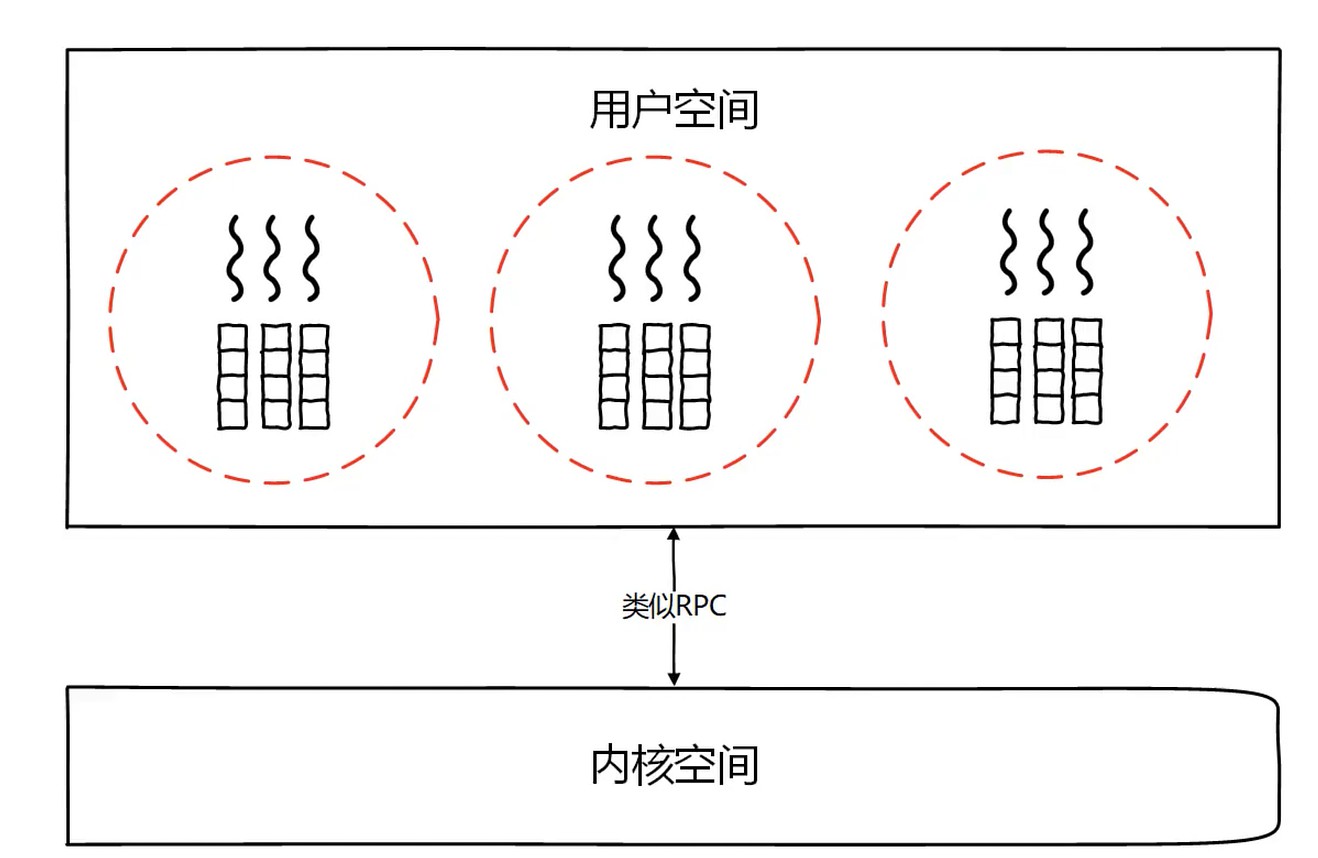
通过OS创建. 像一些语言, Java就会自己创建线程.
线程切换
- 线程主动交出控制权(yield), 或终止
- 保存信息(线程表)
- 本地选择另一个线程执行(由调度器决定)
五状态模型
- 创建
- 分配PCB
- 插入就绪队列
- 当进程拥有PCB, 但是资源还没准备好的时候就是创建状态
- fork函数可以创建进程
- 就绪
- 当进程被分配除了CPU以外的所有必要资源之后
- 只要获得CPU的使用权就可以立即运行
- 系统中多个处于就绪状态的进程通常排成一个队列–就绪队列
- 执行
- 进程获得CPU, 其程序正在执行
- 在单处理机, 在某个时刻只能有一个进程是处于执行状态
- 阻塞
- 其它设备未就绪(某些资源无法获得, 比如打印完成, 读取磁盘)而无法继续执行
- 从而放弃CPU的状态
- 多个处于阻塞状态的进程–阻塞队列
- 终止
- 系统清理
- PCB归还
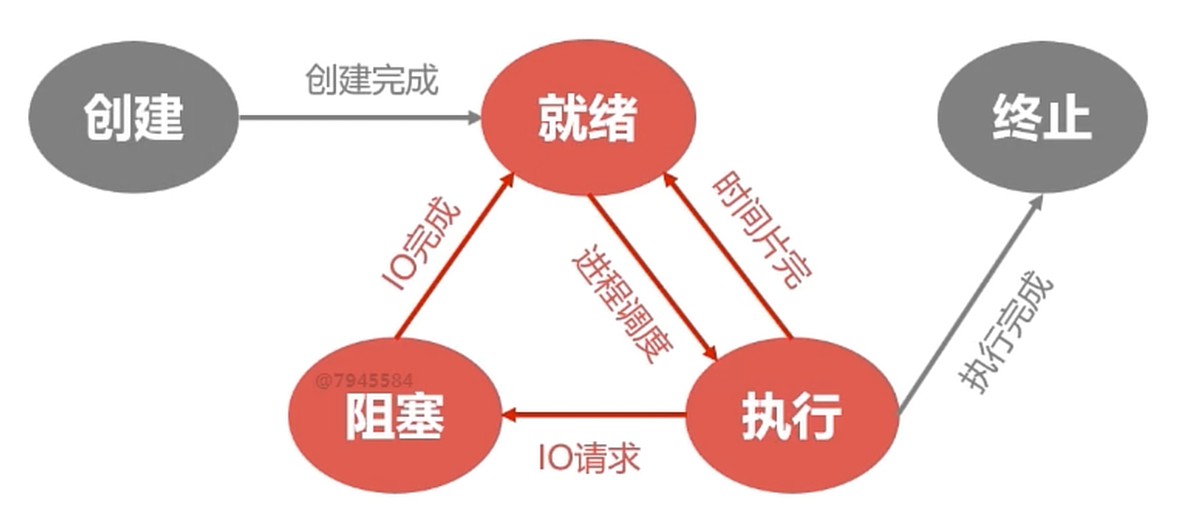
举例子: 读取硬盘的数据, 需要等硬盘的数据读取到缓冲区, 这时候就会产生硬件中断, 进程处于阻塞状态, 当资源到了, 进程会先回到就绪状态, 先排队, 等到了才进入运行状态.
阻塞态不能到运行态, 要先进入就绪态.
就绪态也不能进入阻塞态. 因为处于排队状态.
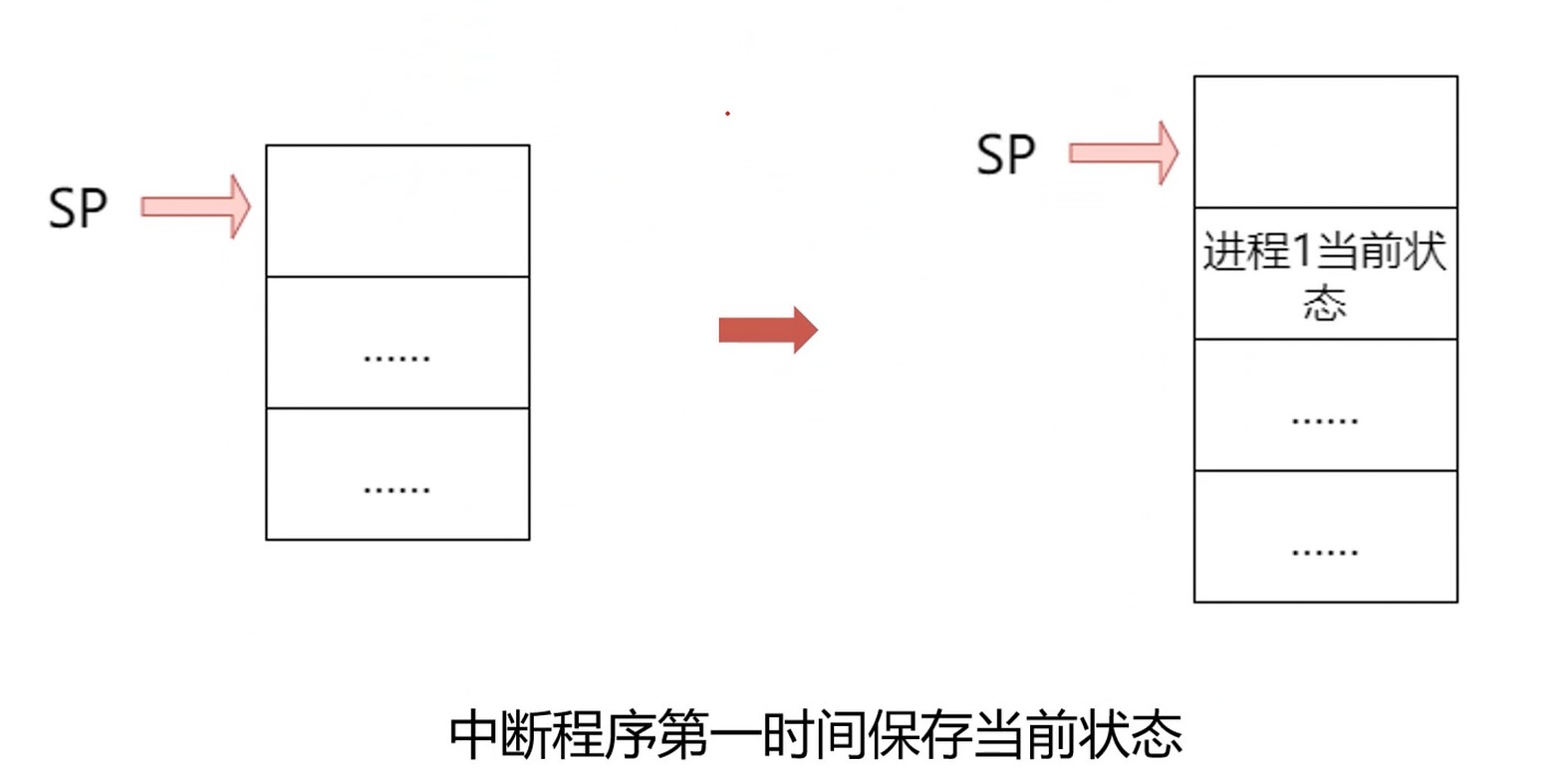
进程响应中断
Step1 保存当前状态
Step2 跳转OS中断响应程序
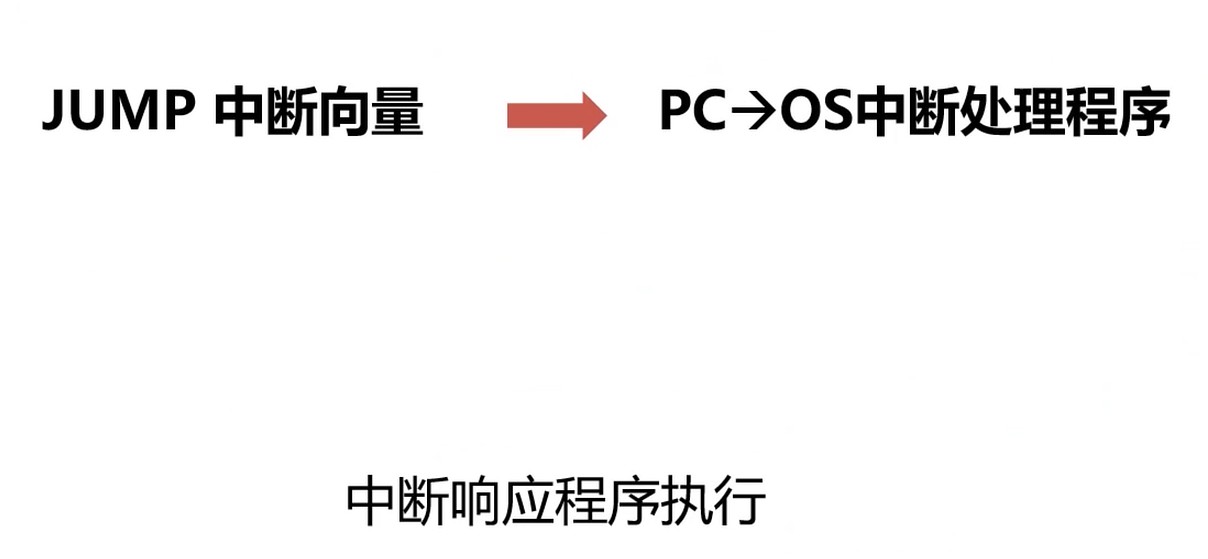
Step3 保存当前寄存器
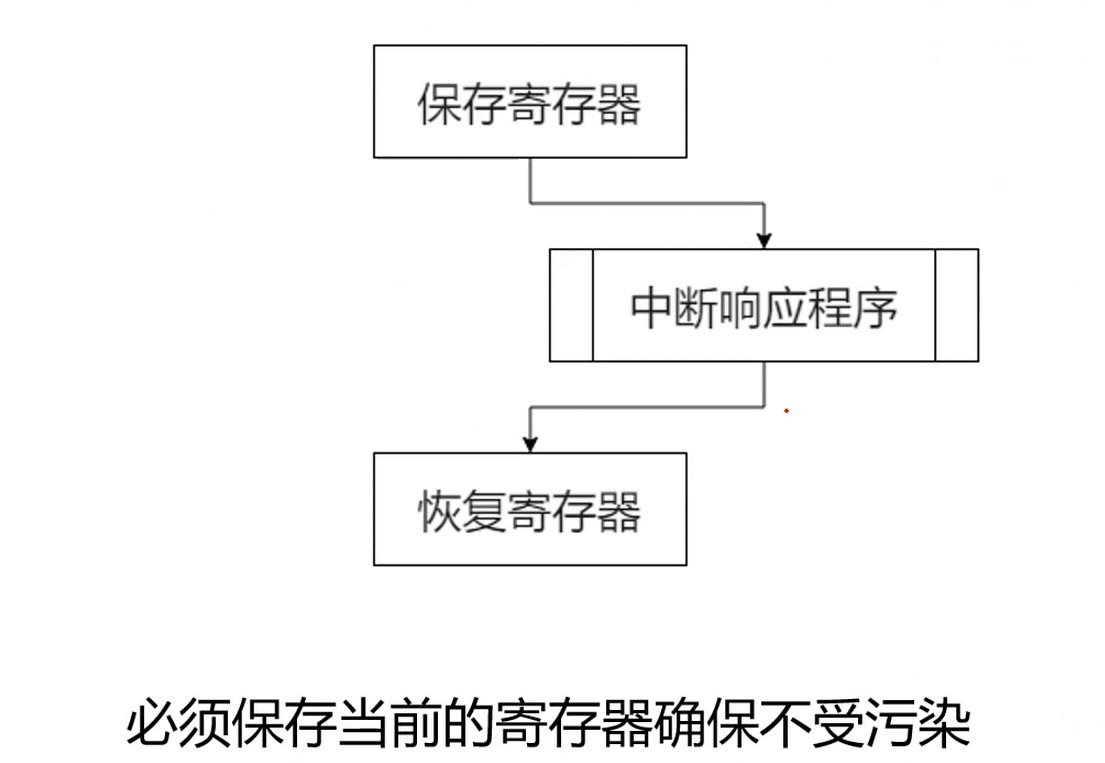
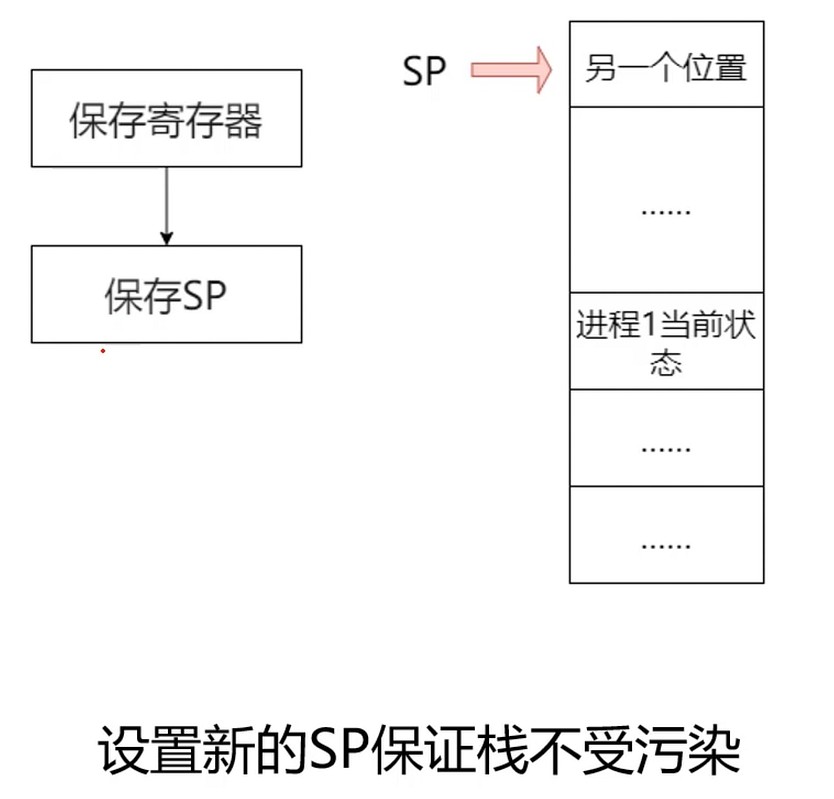
Step4 设置新的栈指针
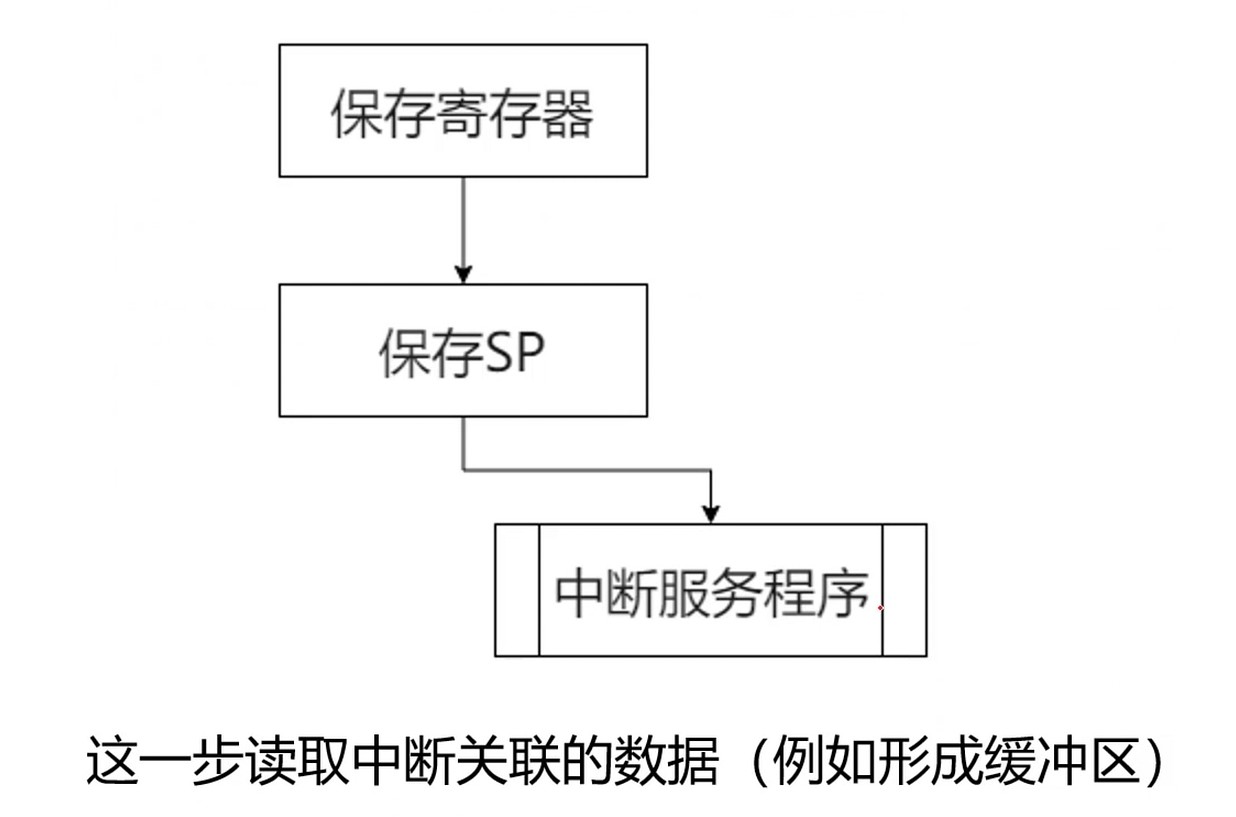
Step5 执行中断服务程序
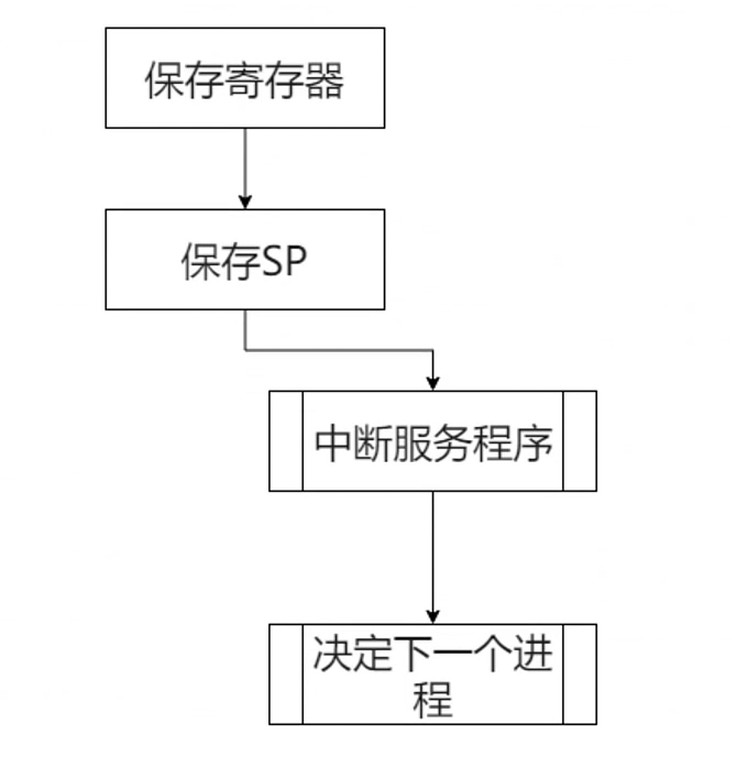
Step6 决定下一个程序
这个步骤由OS的调度决定
Step7 恢复SP和寄存器
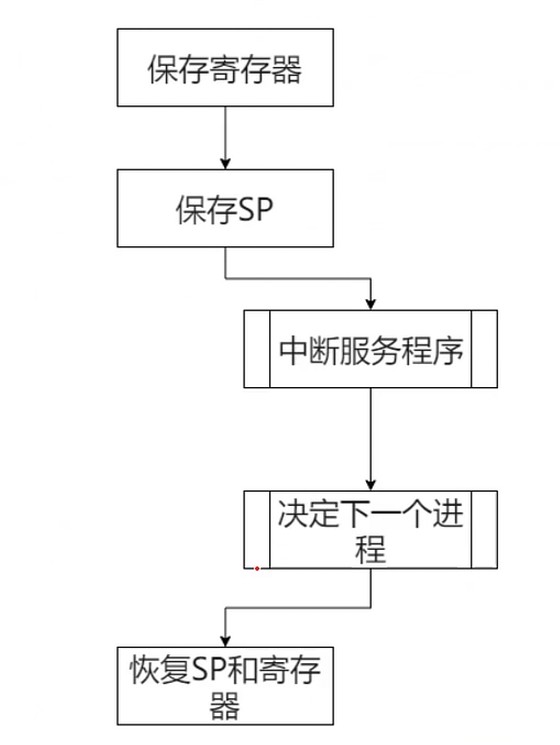
Step8 执行下一个进程
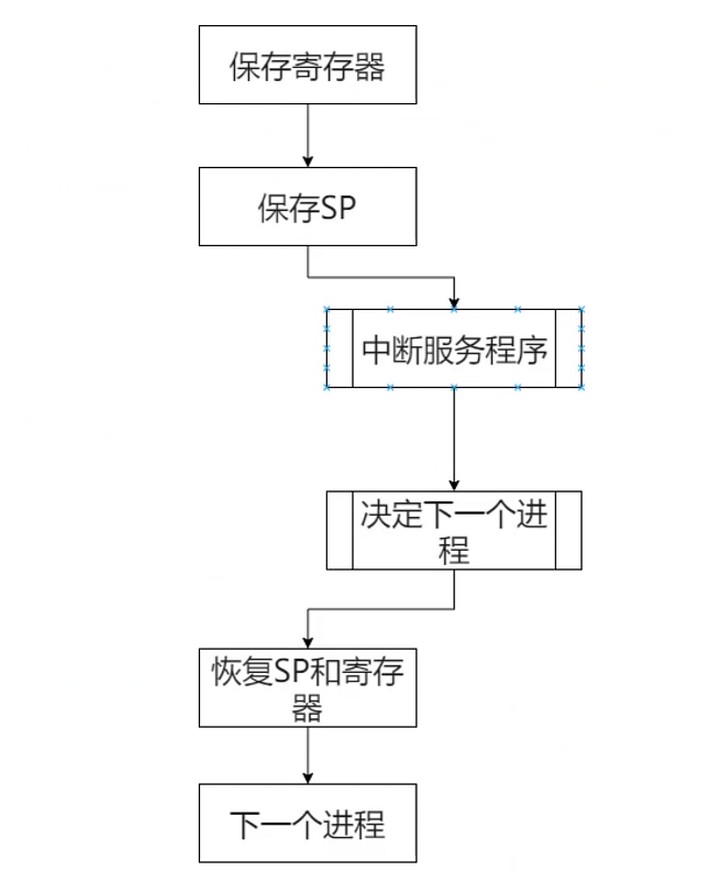
- 进程随时都可以准备保存自己的状态(SP/PC/寄存器)
- 进程随时都可以被切换
- 无法指定马上执行哪个进程, 都需要排队
多核和多道程序
为了提高CPU利用率
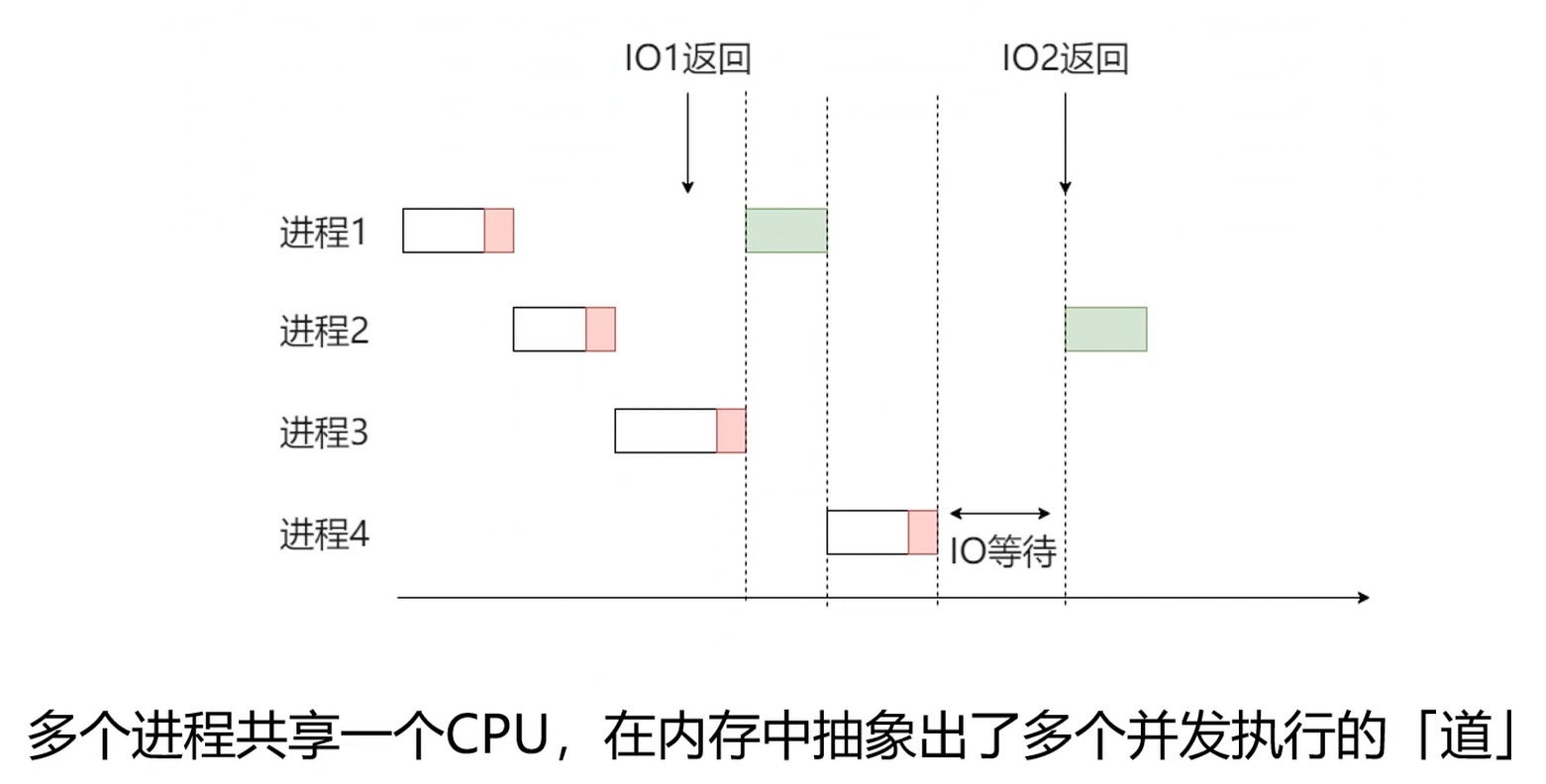
多个进程共享一个CPU, 在内存中抽象出多个并发执行的[道]. 上图红色部分表示进行了IO请求.
CPU 利用率
- 大体有两类工作, 处理I/O(输入输出)和进行计算
- I/O举例: 读写磁盘, 读写内存, 等待打印机Ready
- 计算: 加法运算, 逻辑运算, 浮点运算
多道程序的意义

由此可见, 多道程序设计可以提升CPU利用率.
进程的同步
生产者-消费者问题, 并发执行就可能出现问题, 临界区资源.
根源问题: 彼此之间没有通信.
进程同步: 对竞争资源在多个进程间进行使用次序的协调.
临界区资源: 是共享资源, 但是无法被多个线程共同访问的共享资源.
- 空闲让进: 资源没有占用, 允许使用
- 忙则等待: 资源有占用, 请求进程等待
- 有限等待: 保证有限时间能够使用资源
- 让权等待: 等待时, 进程需要让出CPU
同步的方法
- 消息队列
- 共享存储
- 信号量
线程的同步
进程内多线程也需要同步.
- 互斥量
- 读写锁
- 自旋锁
- 条件变量
Linux的进程管理
- 前台进程
- 具有终端, 可以和用户进行交互的进程
- 后台进程
- 没有占用终端的, 基本不喝用户交互, 优先级比前台进程低
- 在指令后面添加 & 启动后台进程
- kill -9 %1 干掉进程
- 2>&1 > /dev/null/ & 重定向输出
- 守护进程
- daemon进程是特殊的后台进程
- 很多守护进程在系统引导的时候启动, 一直运行知道系统关闭
- 例如: crond(定时任务), httpd, sshd, mysqld. 一般以d结尾的都是守护进程
进程ID是一个非负整数, 最大值由操作系统决定.
父子进程关系. 可以使用 pstree 指令查看.
ID 为0的idle进程, 是系统创建的第一个进程.
ID 为1的init进程, 是0号进程的子进程, 完成系统初始化.
init进程是所有用户进程的祖先进程
进程的标记

# 查看进程的所有父子关系
ps -ef --forest
# 按照使用 cpu 的频率来排序
ps -aux --sort=-pcpu
# 按照使用 内存 的频率来排序
ps -aux --sort=-pmem
# top指令
top
# top - 09:44:19 up 13 min, 0 users, load average: 0.00, 0.00, 0.00
# Tasks: 5 total, 1 running, 4 sleeping, 0 stopped, 0 zombie
# %Cpu(s): 0.0 us, 0.0 sy, 0.0 ni, 99.9 id, 0.1 wa, 0.0 hi, 0.0 si, 0.0 st
# MiB Mem : 7959.7 total, 7559.0 free, 73.4 used, 327.3 buff/cache
# MiB Swap: 8192.0 total, 8192.0 free, 0.0 used. 7662.6 avail Mem
# PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
# 1 root 20 0 1744 1084 1012 S 0.0 0.0 0:00.00 init
# 7 root 20 0 1756 76 0 S 0.0 0.0 0:00.00 init
# 8 root 20 0 1756 88 0 S 0.0 0.0 0:00.03 init
# 9 devlgq 20 0 9988 5032 3316 S 0.0 0.1 0:00.08 bash
# 875 devlgq 20 0 10876 3744 3224 R 0.0 0.0 0:00.00 top
# PR 进程优先级
# VIRT 进程的虚拟内存
# TIME+ 进程运行的时间
# total 所有的内存
# free 空闲的内存
# used 已经使用的内存
# buff/cache 已经缓存的内存
进程的调度
指计算机通过决策决定哪个就绪进程可以获得CPU的使用权.
调度是对资源管理和利用, 应用方面不仅仅是操作系统领域.
- Yarn调度Hadoop集群
- Quartz调度任务
- Spring调度请求响应
- React Fiber调度绘制任务
- Apache Flink调度作业
本质
- 资源的稀缺
- 根据不同的场景找到最优解(类型Programing-规划问题)
并发调度问题
多个进程和线程竞争CPU, 2个或以上处于就绪状态.
多道程序设计
- 保留旧的进行运行信息
- 选择新进程. 准备运行环境并分配CPU
关注点
- 被调度任务的特性(计算密集型 VS IO密集型)
- 执行时机
- 新任务何时执行
- 任务临时终止如何选择下一个任务
- 任务阻塞如何选择下一个任务
- 发生中断时(外部环境变化时)如何响应
- 调度算法
- 抢占式算法
- 非抢占式算法
目标
通用目标
- 公平, 每个进程公平地分享CPU份额(相对)
- 策略强制执行, 保证规定的策略被执行
- 平衡, 保持系统尽可能忙碌
不同系统的不同目标
- 批处理系统(吞吐量, 周转时间, CPU利用率)
- 不可抢占
- 交互式系统(响应性, 体验)
- 分时, 抢占
- Windows, Android
- 实时系统(精准, 稳定)
- 完成时间确定
- 车床控制
进程调度机制
- 就绪队列的排队机制
- 按一定方式排成队列, 以便调度程序可以最快找到就绪进程
- 选择运行进程的委派机制
- 调度程序以一定的调度策略选择就绪程序, 将CPU资源分配给它
- 新老进程的上下文切换机制
- 保存当前进程的上下文信息, 装入被委派执行进程的运行上下文就
进程调度分类
- 非抢占式调度
- 处理器一旦分配给某个进程, 就让该进程一直使用下去, 任务不分时
- 调度程序不以任何原因抢占正在被使用的处理器
- 相对公平
- 专用系统
- 频繁切换, 开销大
- 抢占式调度
- 允许调度程序以一定的策略暂停当前运行的经常(时间片用完)
- 保存好旧进程的上下文信息, 分配处理器给新进程
- 不公平
- 通用系统
- 切换少, 开销小
调度算法
- 先来先服务算法
- 队列, 按顺序
- 短进程有限调度算法
- 优先选择就绪队列估计运行时间最短的进程
- 相同优先级可以考虑此算法. 通过执行的历史记录来进行评估.
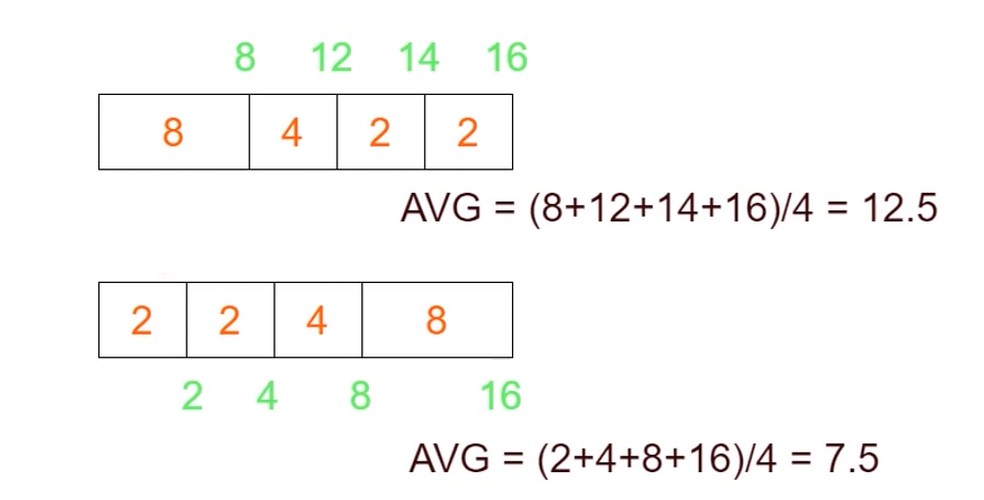
- 高优先权调度算法
- 进程附带优先权, 优先选择权重高的进程
- 使得紧迫的任务可以优先处理
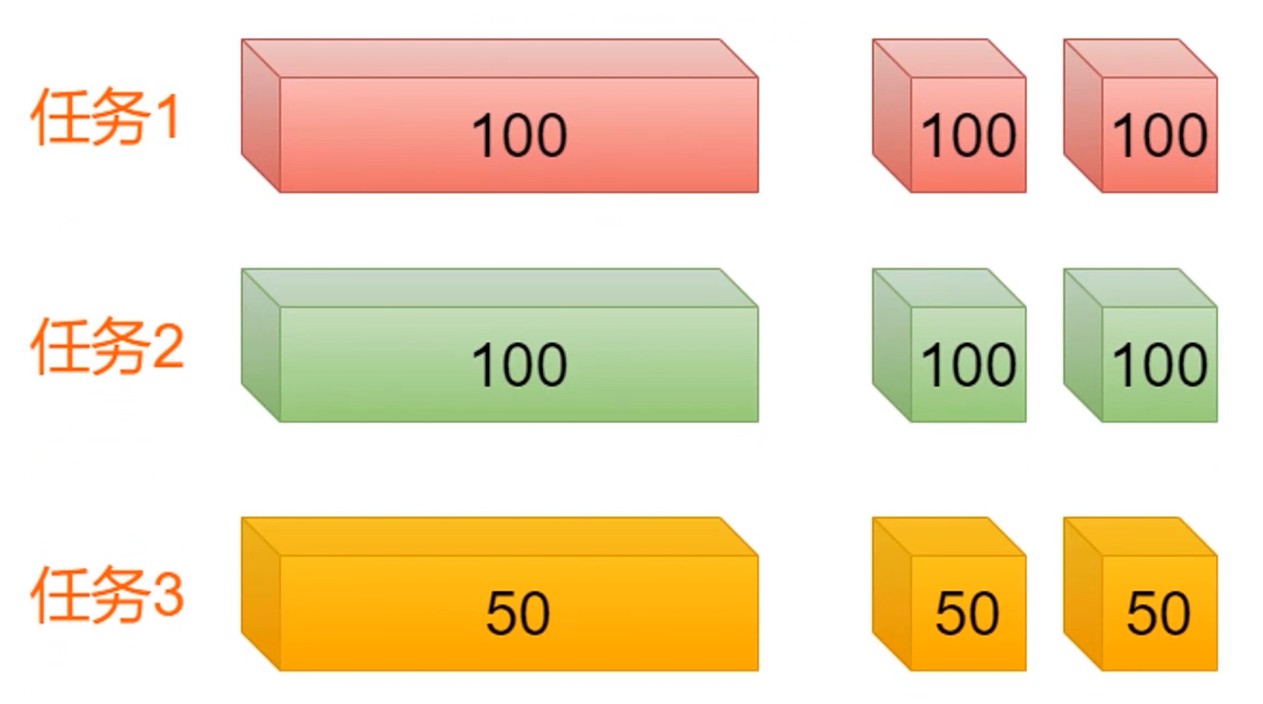
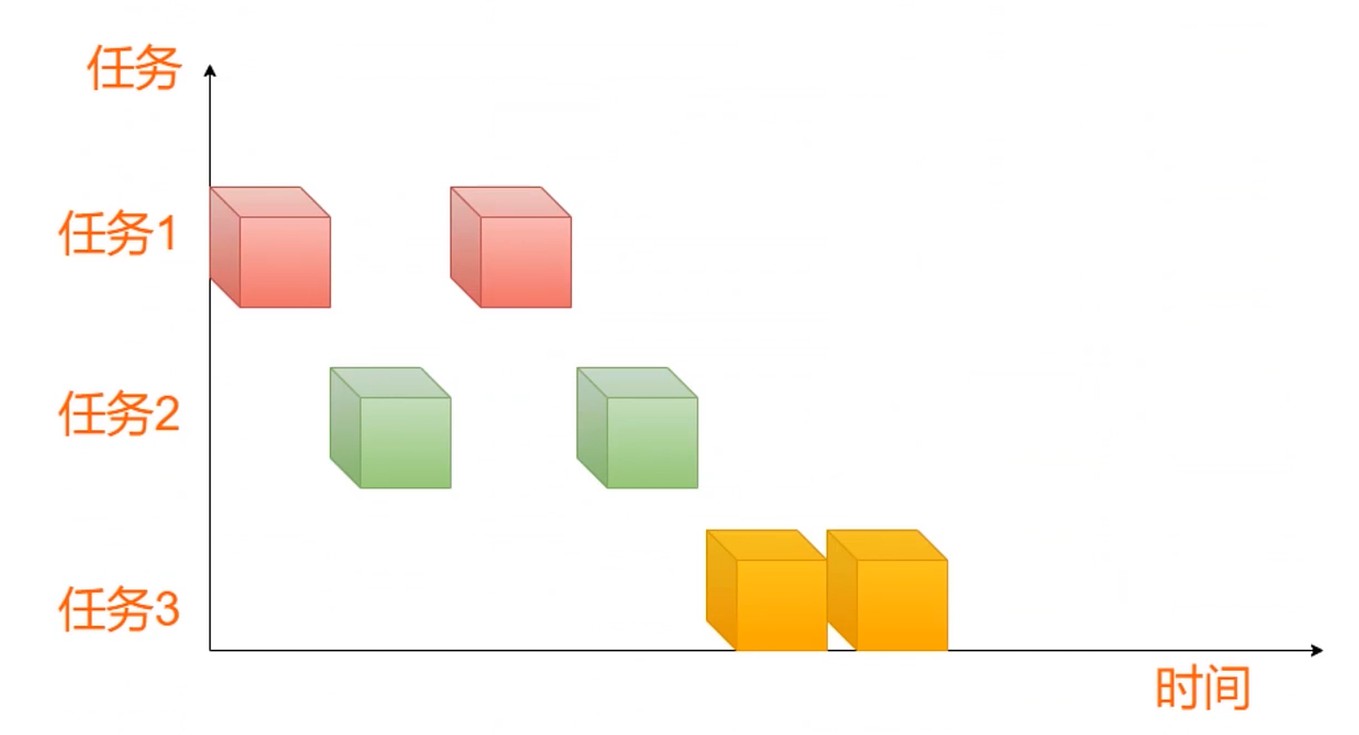
- 时间片轮转调度算法
- 按先来先服务的原则排列就绪进程
- 每次从队列取出待执行进程, 分配一个时间片执行
- 相对公平的调度算法, 但不能保证及时响应用户

优先级队列
实现结构: 最大堆(Max Heap)

树也可以使用数组来表示, 但是树必须是饱和的.

堆插入一个新值的步骤.
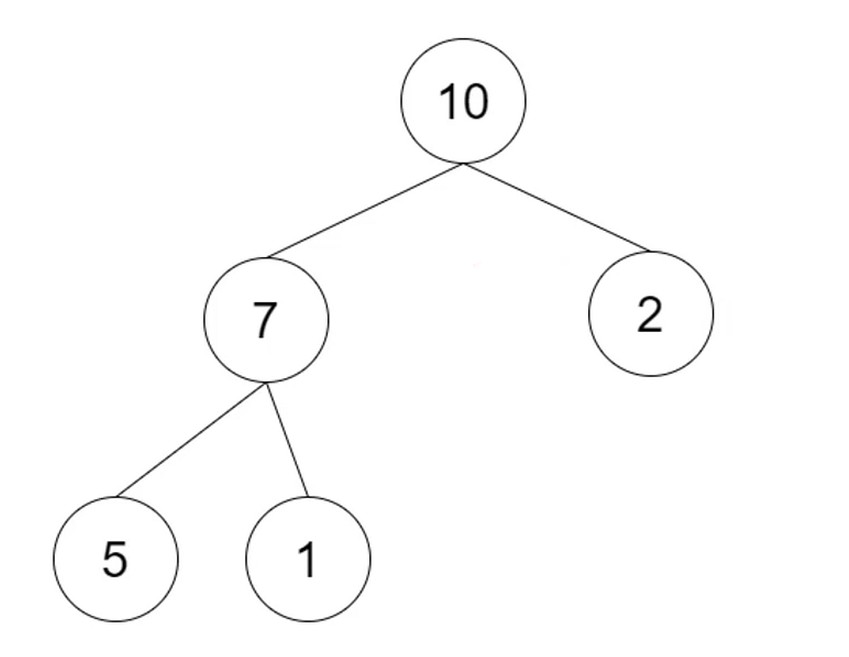
先插入堆最后的位置(数组). 而堆的父节点要比子节点的大.
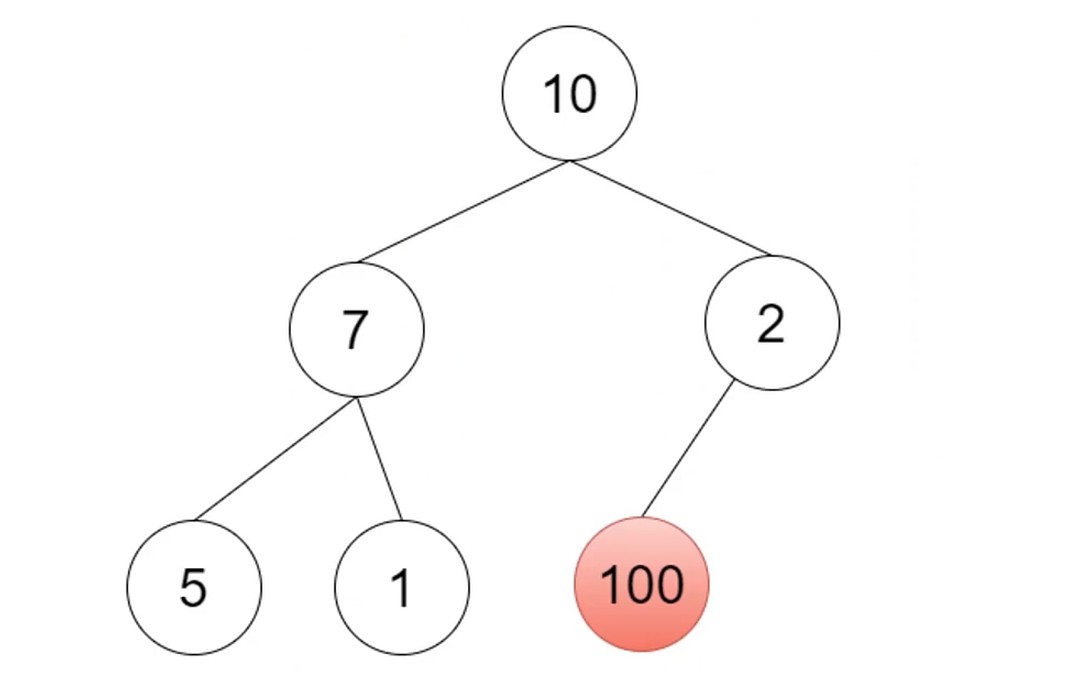
把100与父节点交换. 往上比较交换.
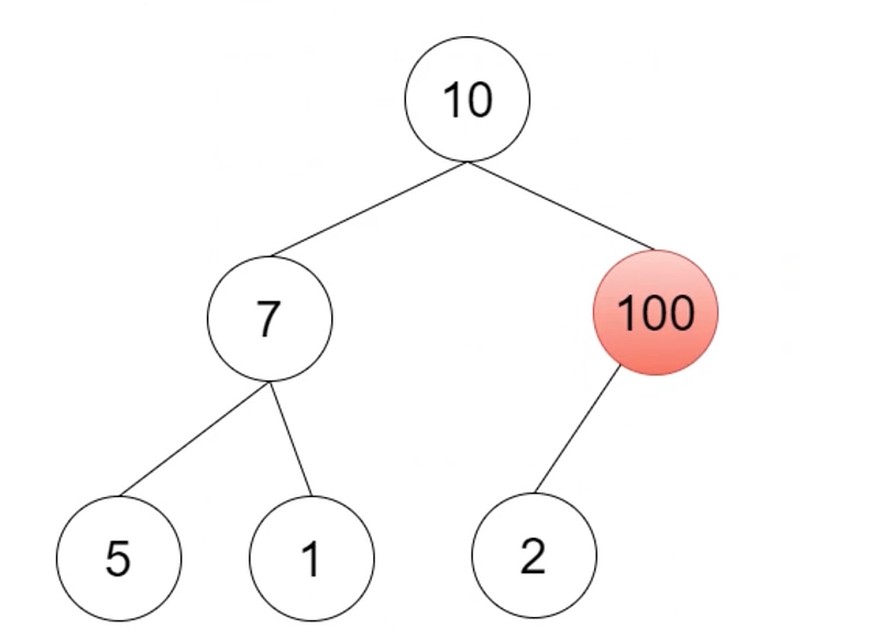
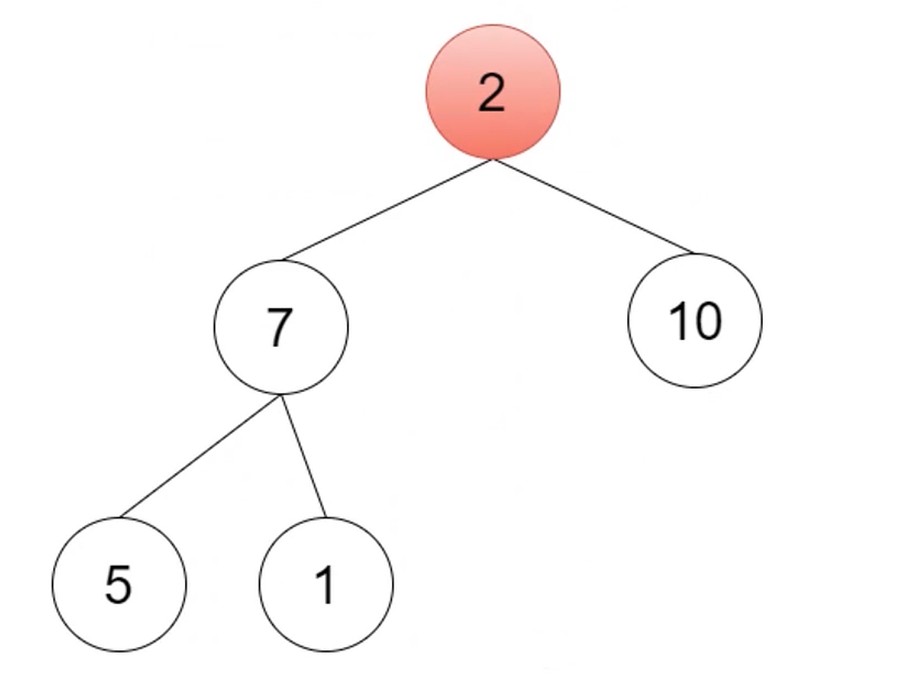
提取最大值, 也就是数组的第一个值.
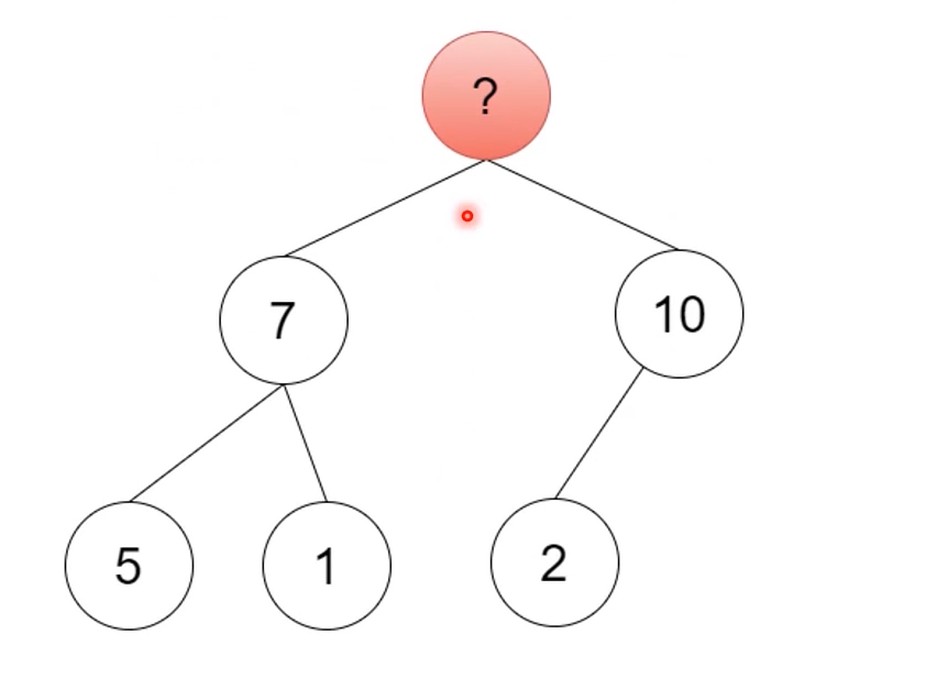
然后把2填补过去, 然后往下比较交换, 与较大的子节点进行比较.
复杂度分析
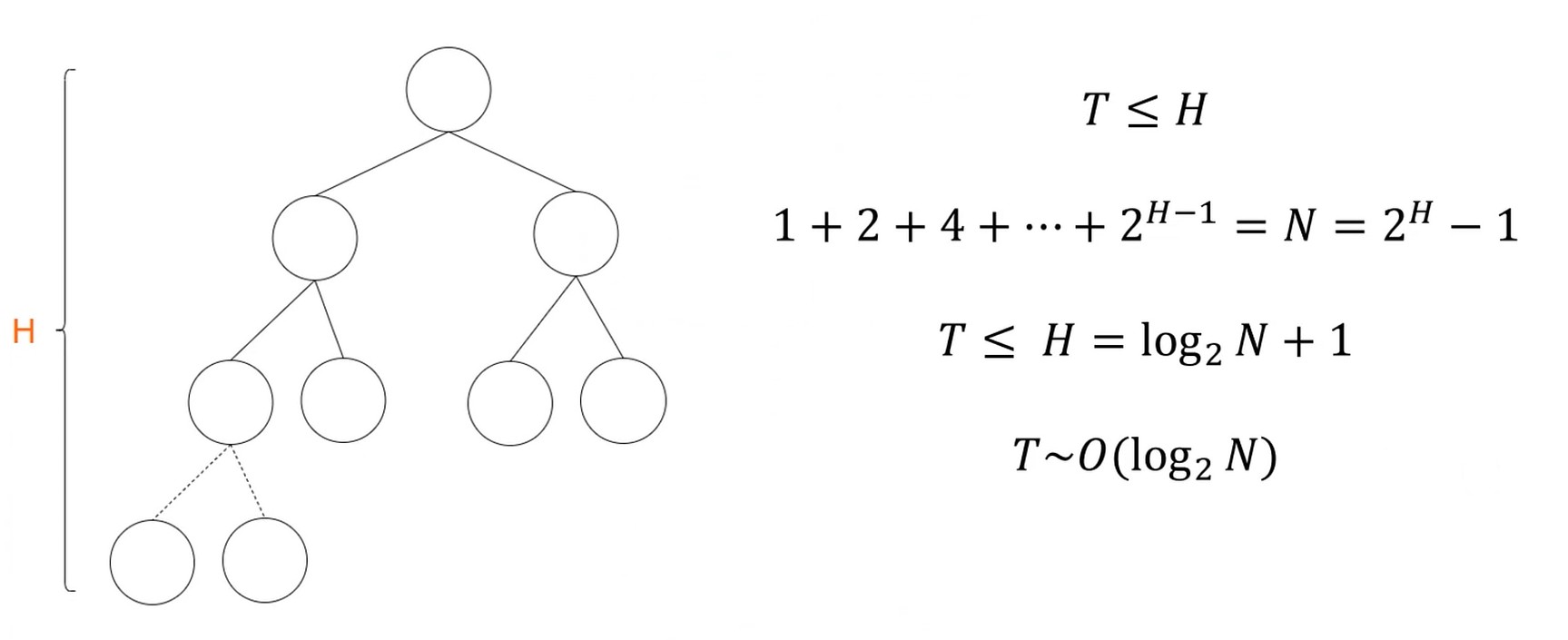
在 H 的范围内, 节点全部填满做复杂度分析.
可以看出树的高度和2的对数相关. 1T数据, 30次就能走完了. 提取最大值的速度很快.
Priority Queue

优先级队列提取全部

哲学家就餐问题
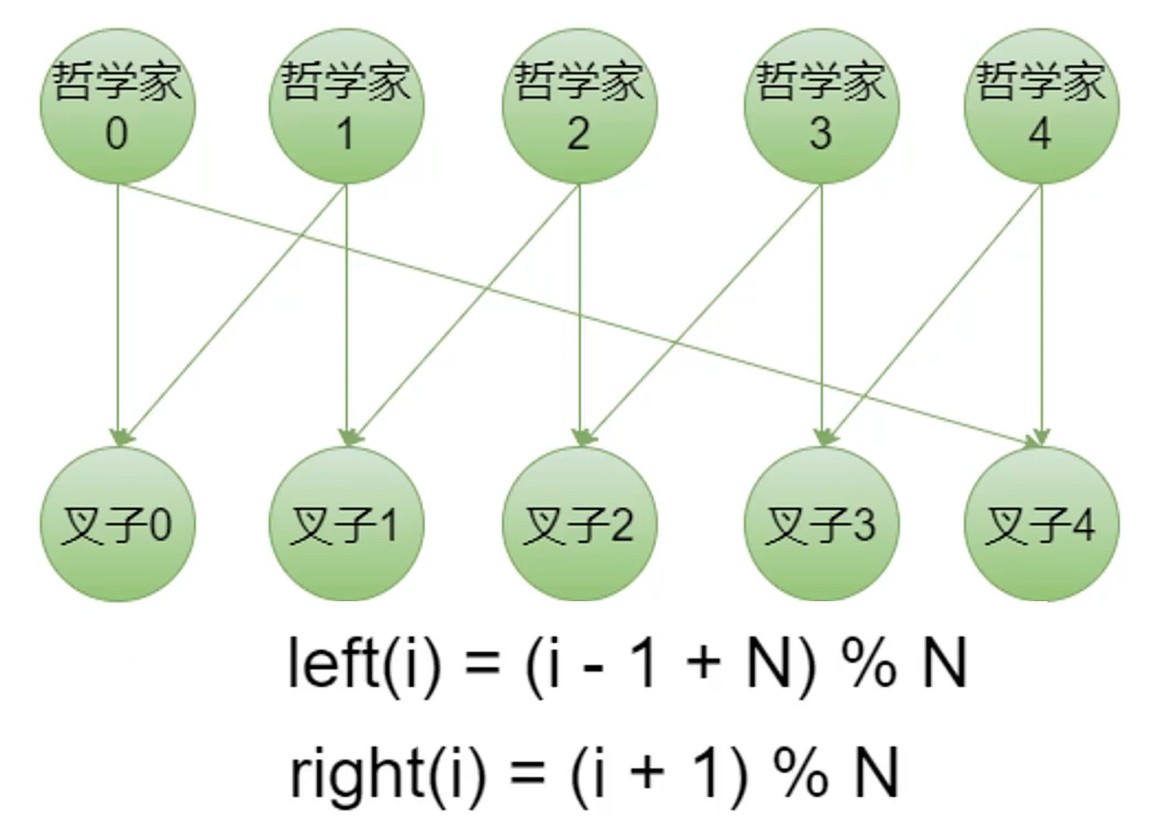
宏: 字符串查找替换

所有人同时拿起叉子–死锁问题
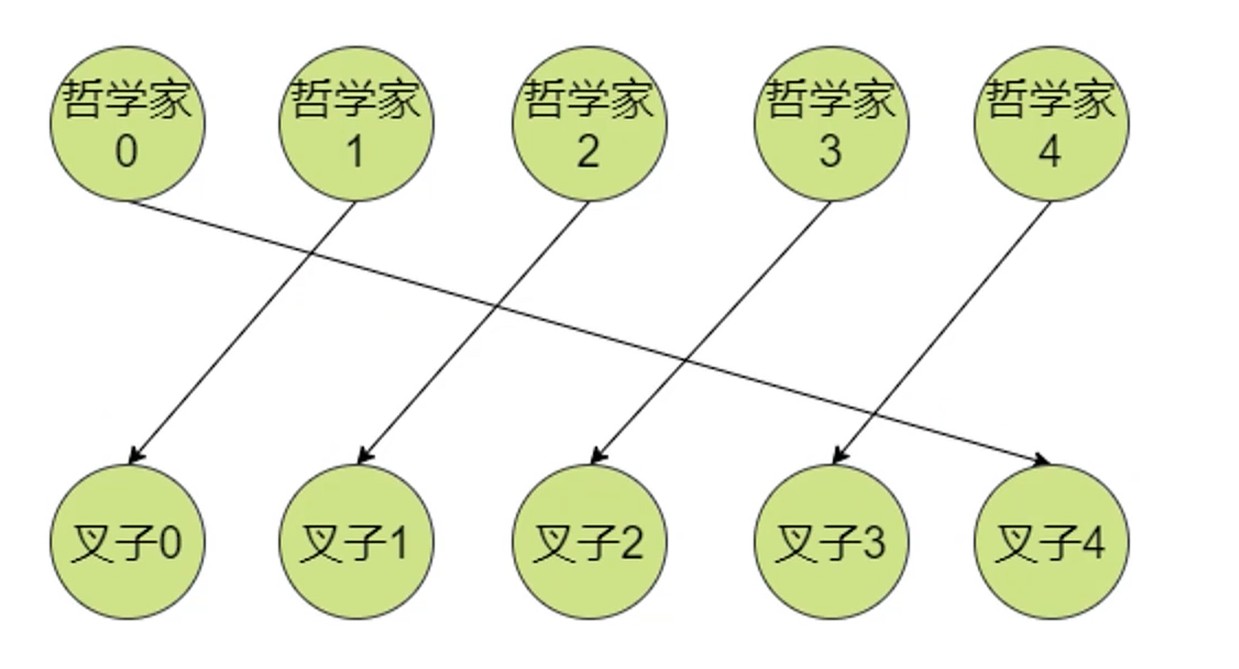
思考, 映射到mutex和semaphore.

拿起叉子的过程

放下叉子的过程

死锁
- 竞争资源
- 进程调度顺序不当
死锁四个必要条件
- 互斥条件
- 进程对资源的使用是排他性的使用
- 某资源只能由一个进程使用, 其它进程需要使用只能等待
- 请求保持条件
- 进程至少保持一个资源, 又提出新的资源请求
- 新资源被占用, 请求被阻塞
- 被阻塞的进程不释放自己保持的资源
- 不可剥夺条件
- 进程获得的资源在未完成使用前不能被剥夺
- 获得的资源只能由进程自身释放
- 环路等待条件
- 必然存在进程-资源的环形链
死锁的处理
防止: 破坏四个条件之中的一个即可.
- 程序一开始就申请所有资源, 这样就破坏了请求保持条件
- 一个进程请求新的资源得不到满足时, 必须释放占有的资源, 就是说可以被剥夺
- 可用资源线性排序, 申请必须按需要递增申请
银行家算法
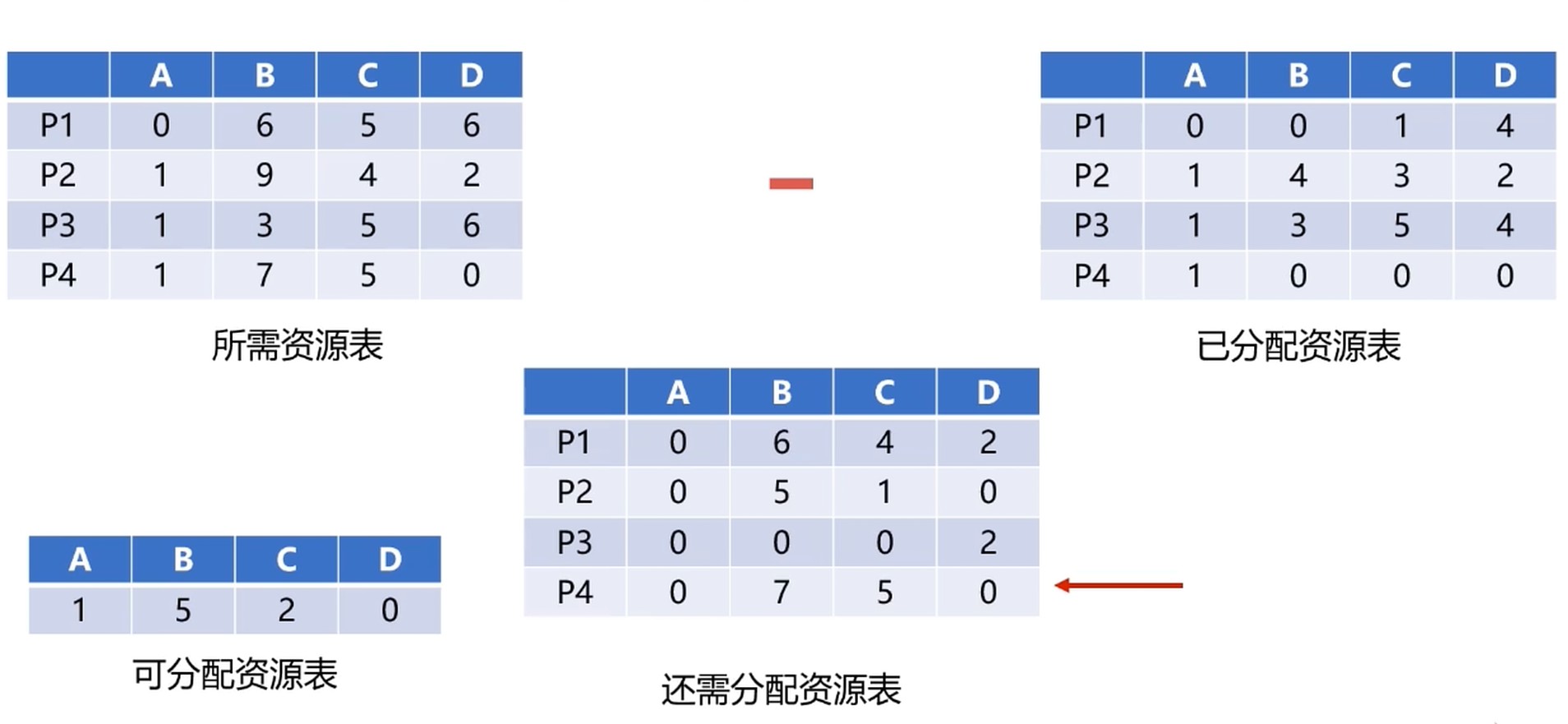
P2 满足需求, 可以先P2获取资源先, 等P2完成后, 释放资源后, 其它进程就有更多资源使用了.
存储管理
- 确保计算机有足够的内存处理数据
- 确保程序可以从可用内存中获取一部分内存使用
- 确保程序可以归还使用后的内存以供其它程序使用
内存分配与回收
需要合理分配, 如果用户程序不小心操作了操作系统内存中的数据, 有可能造成系统崩溃; 应用之间的访问也会变的不安全.
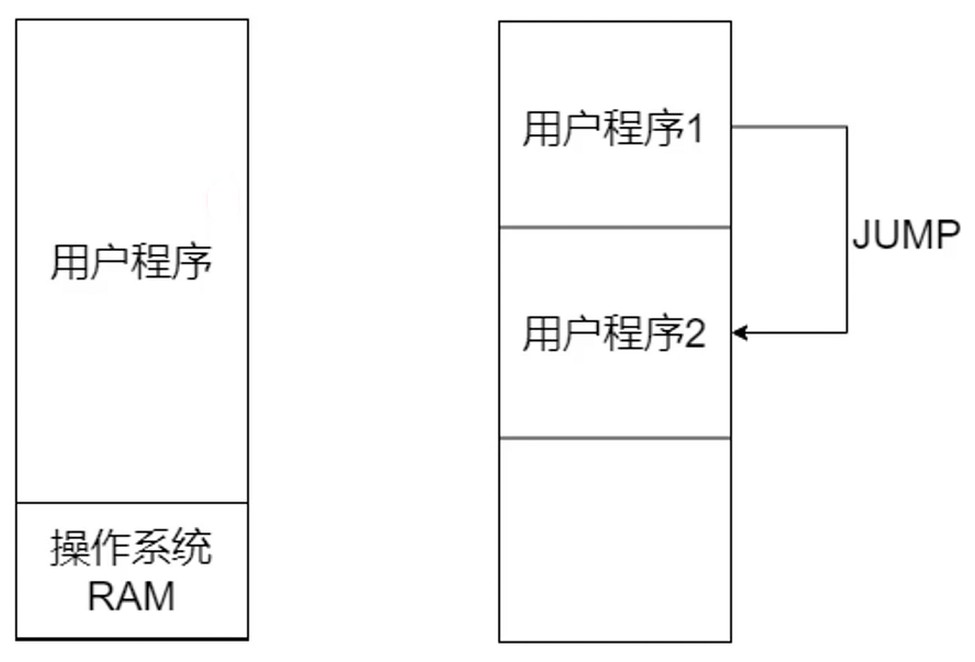
单一连续分配
- 单一连续分配, 最简单的内存分配方式
- 只能在单用户, 单进程的操作系统使用
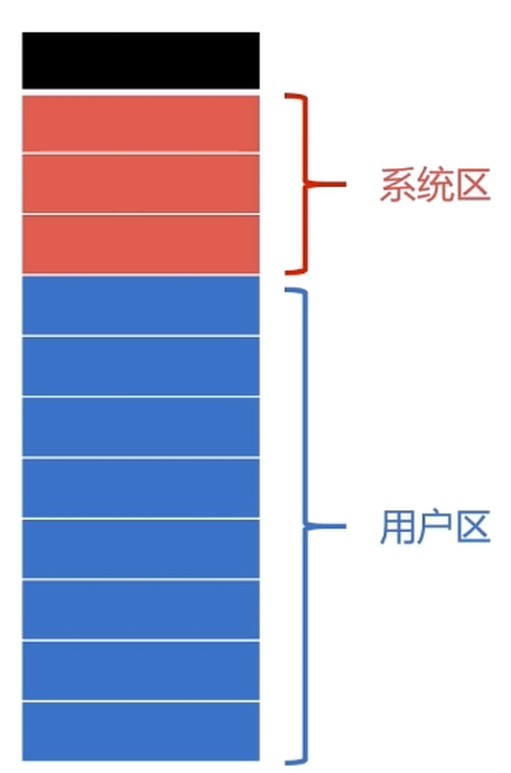
固定分区分配
- 是支持多道程序的最简单的存储分配方式
- 内存空间划分为若干个固定大小的区域
- 每个分区只提供一个程序使用, 互不干扰

动态分区分配
- 更加实际需要, 动态分配
- 相关数据结构和分配算法
动态分区空闲表数据结构

动态分区空闲链数据结构
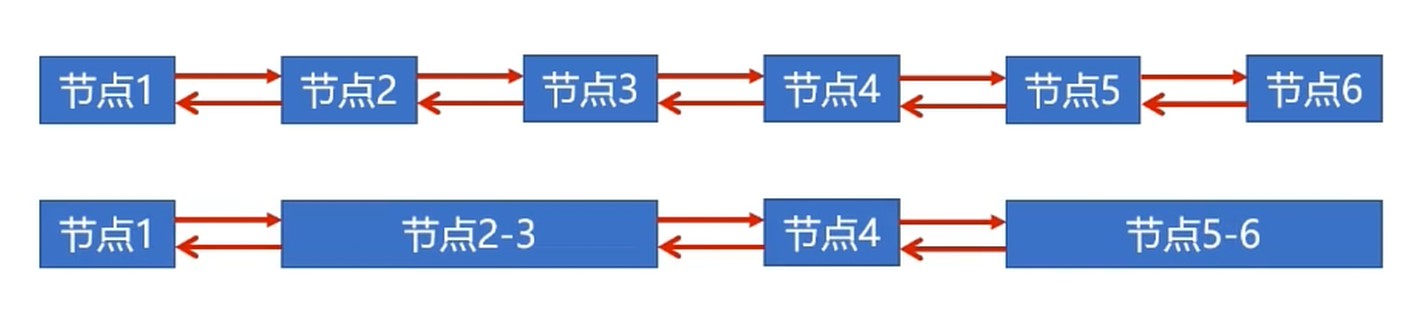
连续的空闲区域可合并到一个节点; 节点需要记录可存储的容量.
动态分区分配算法
- 首次适应算法(FF算法)
- 从头开始遍历链表, 没有找到合适的空闲区则分配失败
- 问题: 每次都是从头部开始, 使得头部地址不断被分配
- 最佳适应算法(BF算法)
- 空闲区链表按照容量大小排序
- 遍历空闲区链表找到最佳适合空闲区
- 避免大材小用
- 快速适应算法(QF算法)
- 要求有多个空闲区链表
- 每个空闲区链表存储一种容量的空闲区
内存回收
四种情况




进程使用内存划分
- 本质原因: 资源的稀缺
- 解决方案: 基地址+界限寄存器, 交换技术, 虚拟化技术等
地址空间–Address Space: 把真实的内存划分成不同的区间
- 进程间内存需要隔离
- 地址空间是进程用来寻址的独立地址集合
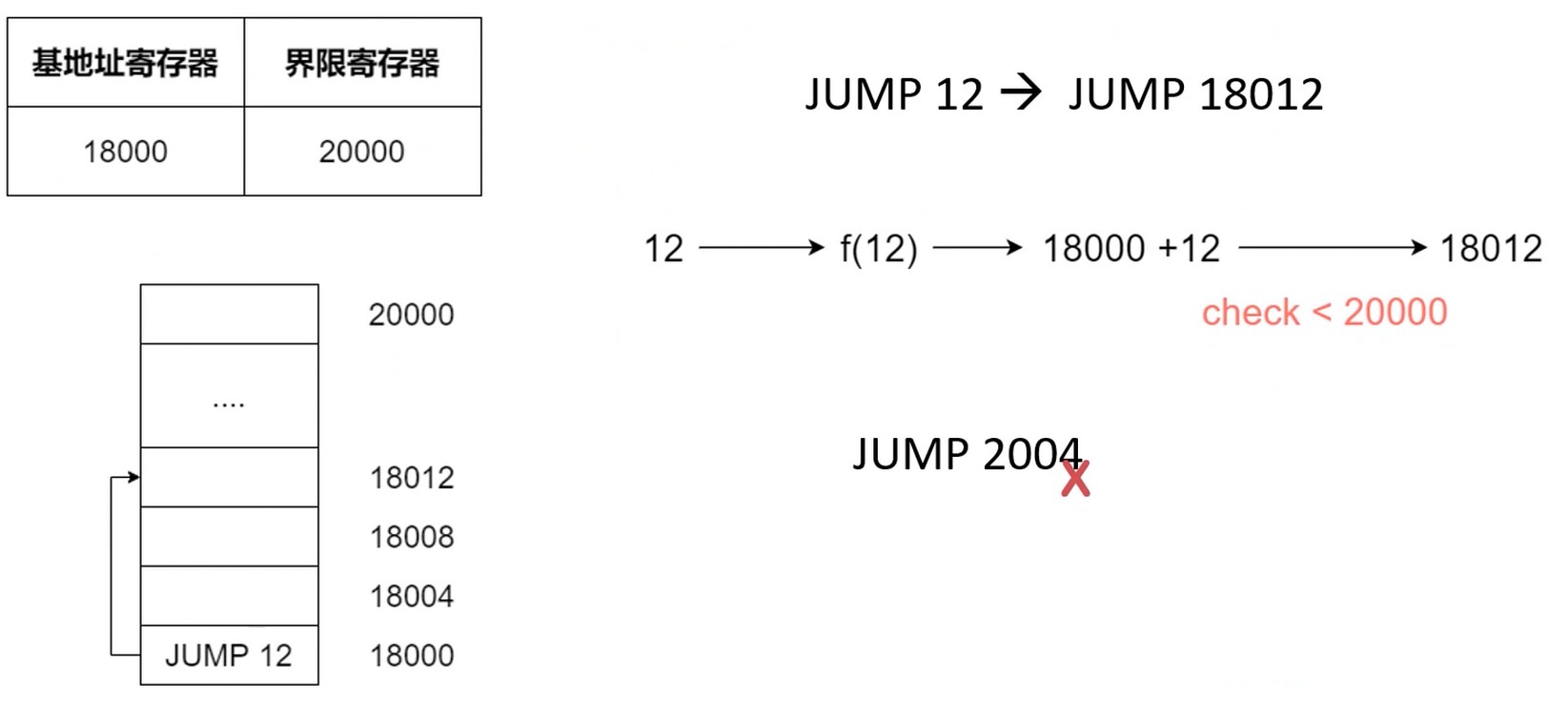
解决方案1: 基地址寄存器+界限寄存器
每个进程运行在自己的地址空间. 有界限范围.

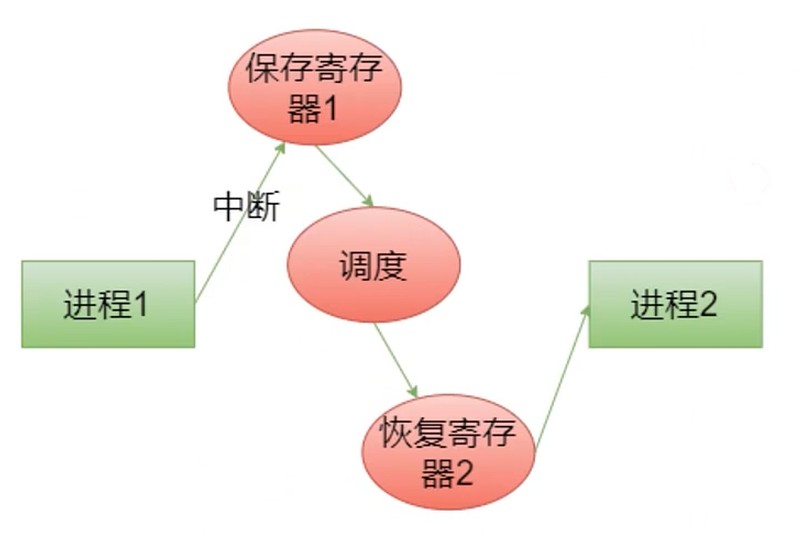
进程1切换到进程2的时候, 中断后会把进程1的寄存器都保存下来, 调度系统再去调度进程2.
缺点
- 每次都需要做一次加法(基地址寄存器)和一次比较(界限寄存器)
- 进程太多, 内存不够分怎么办? 内存超载.
- 交换(Swapping)
- 虚拟内存(VistualMemory)
段页式存储管理
操作系统管理进程的空间的方式. 虚拟内存的基础.
如果不对内存空间进行划分, 交换内存会有问题.

本质上都是为了解决资源稀缺的问题.
页式存储管理
字块是相对物理设备的定义
页面则是相对逻辑空间的定义
- 将进程的逻辑空间等分成若干大小的页面
- 相应得把内存空间分成与页面大小的物理块
- 以页面为单位把进程空间装进物理内存中分散的物理块
碎片化问题
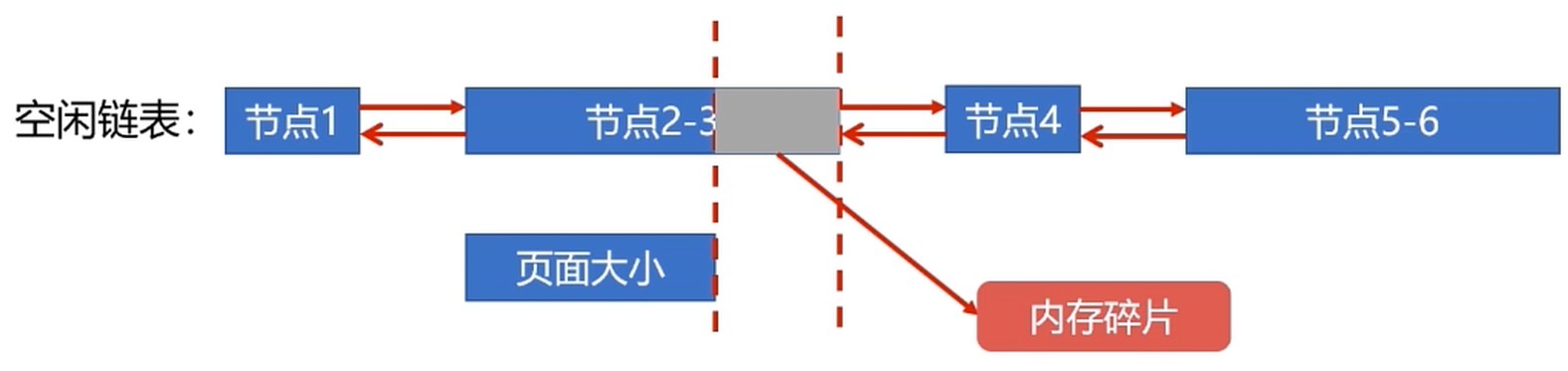
所以, 页面大小应该适中, 过大难以分配, 过小内存碎片过多
页面大小通常是 512B ~ 8K
页表
- 记录进程逻辑空间与物理空间的映射
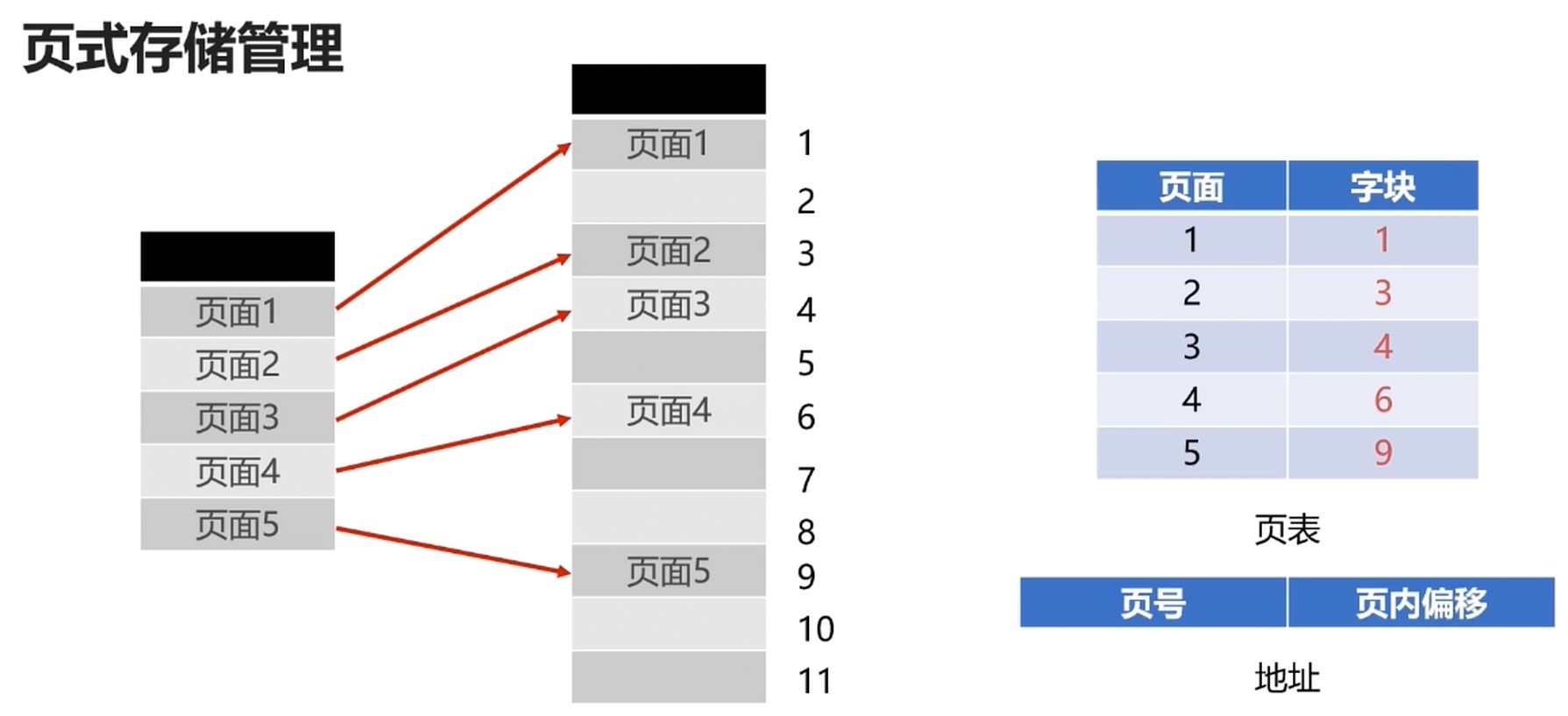
问题: 现代计算机系统中, 逻辑地址很大, 这样页表会很占用空间.
如32位逻辑地址的空间分页系统, 规定页面大小为4kb, 则在每个进程页表可达1M(2^20)个, 如果每个页表占用1Byte, 故每个进程仅仅页表就要占用1MB的内存空间.
分级页表, 按需区加载即可.
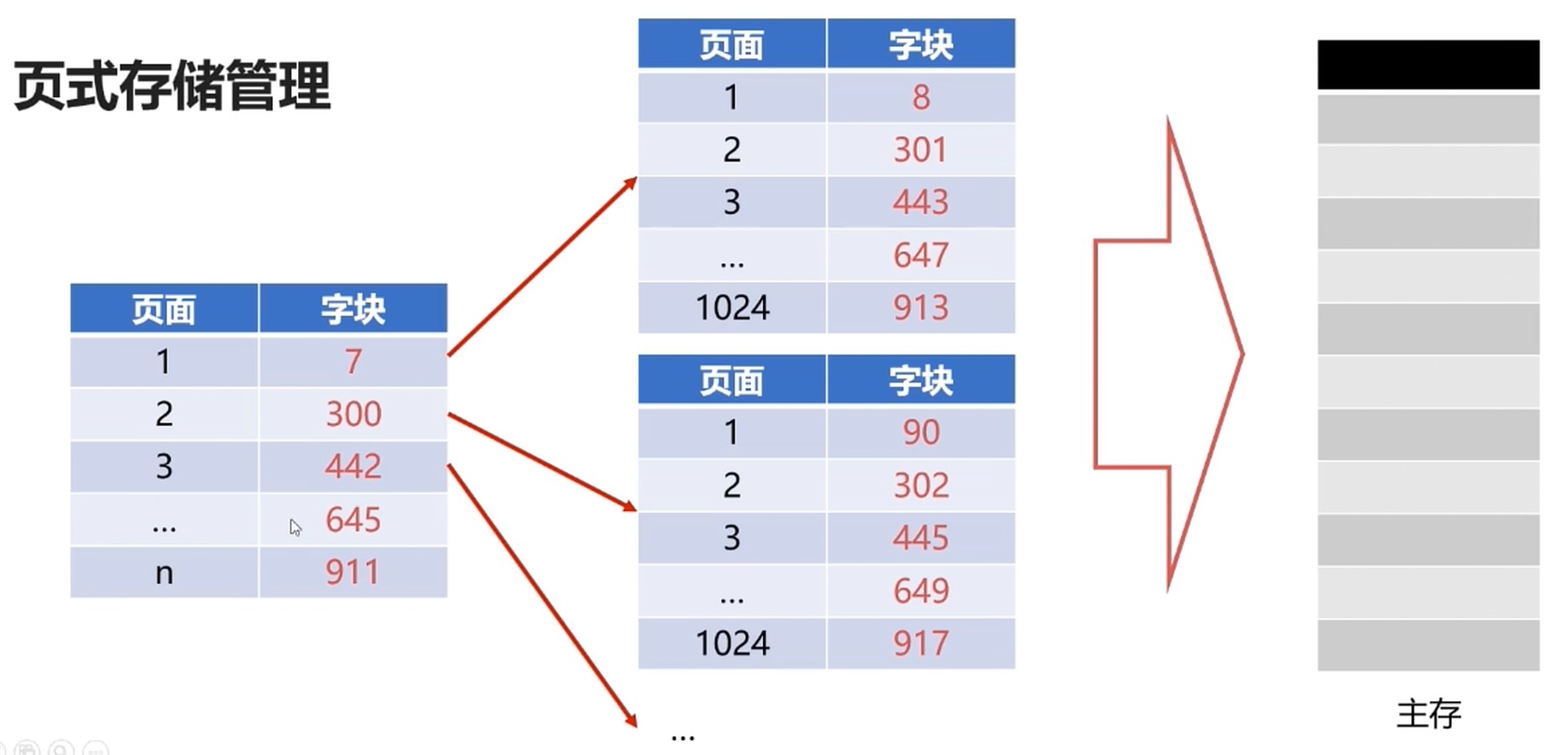
如果一段连续的逻辑分布再多个页面中, 将大大降低执行效率
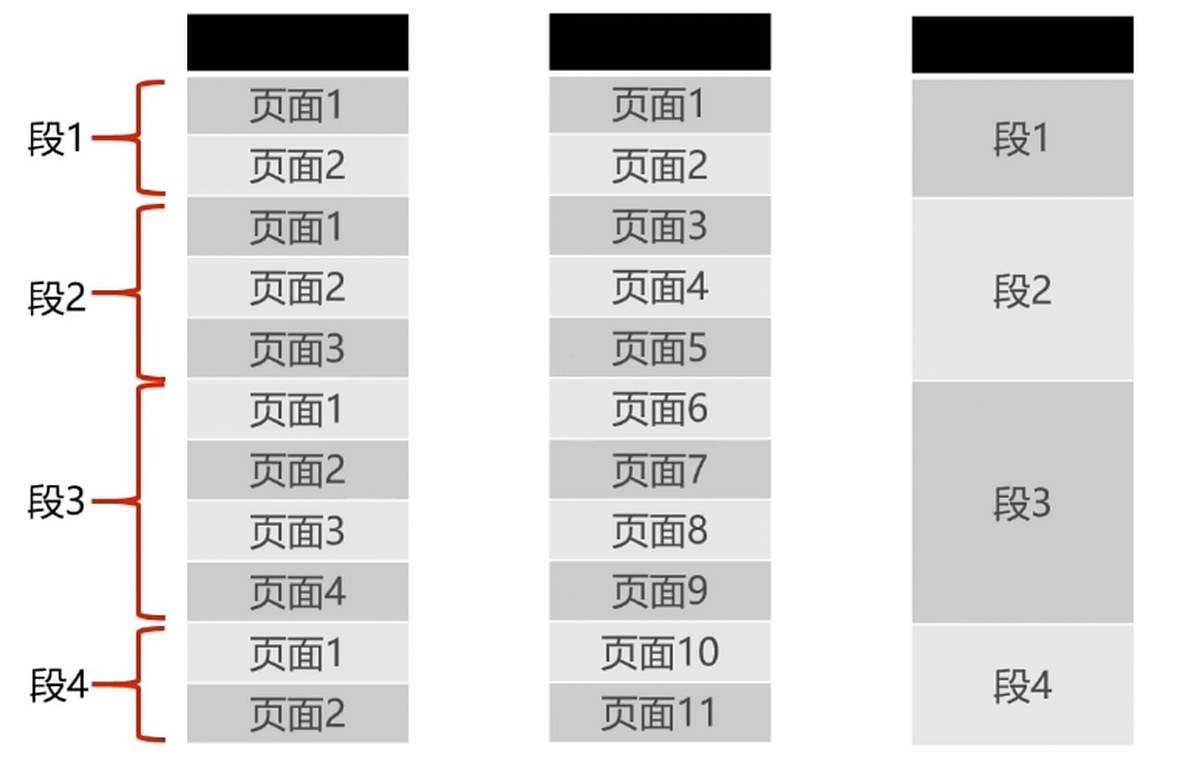
段式存储管理
- 将进程逻辑空间划分成若干段(非等分)
- 段的长度由连续的长度决定
- 主函数MAIN, 子程序段X, 子函数Y等.
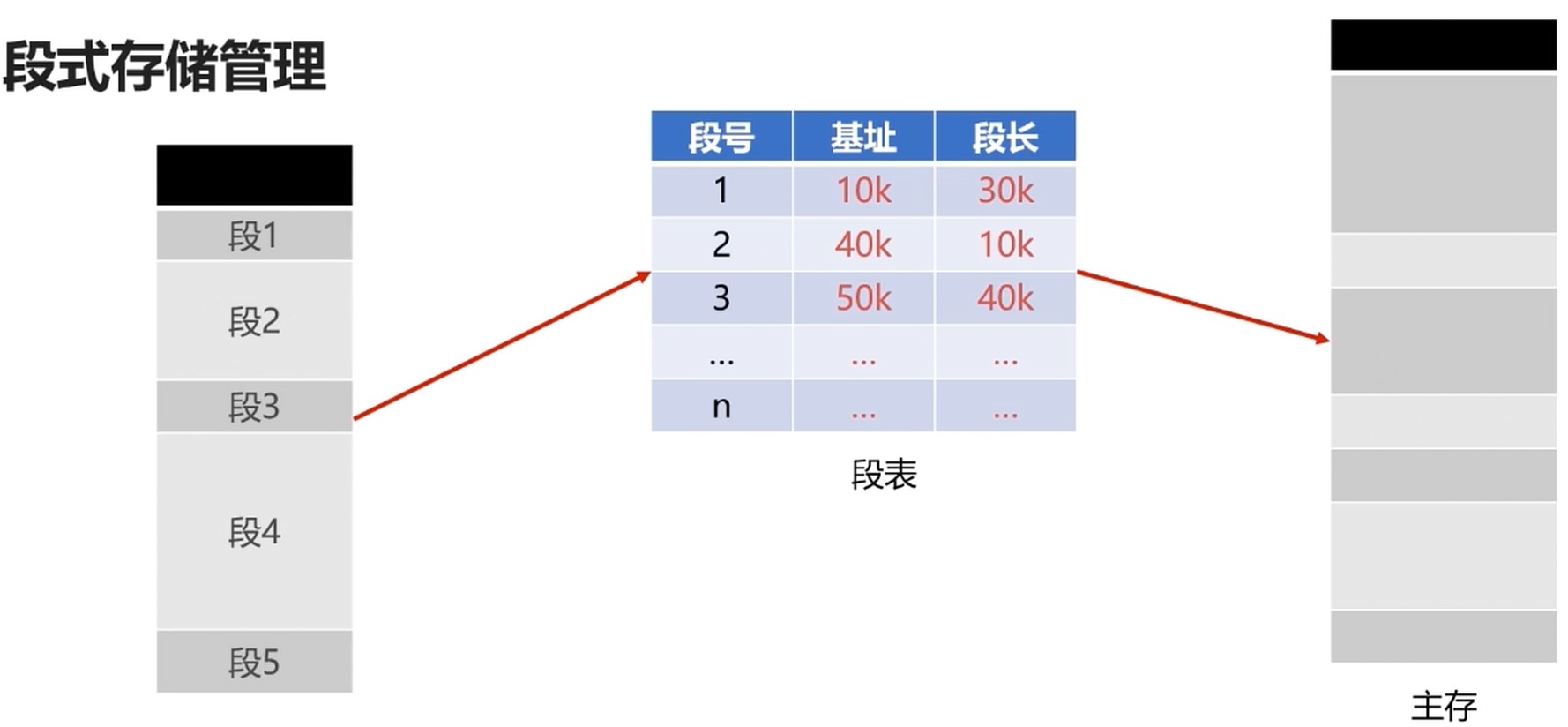
段式管理和页式管理都离散地管理了进程的逻辑空间.
- 页是物理单位, 段是逻辑单位
- 分页是为了合理利用空间, 分段是满足用户要求
- 页大小由硬件固定, 段长度可动态变化
- 页表信息是一维的, 段表信息是二维的
段页式存储管理
分页可以有效提高内存利用率(虽然说有内存碎片问题)
分段可以更好满足用户需求
两者结合, 形成段页式存储管理
先将逻辑空间按段式管理分成若干段
再把段内空间按页式管理等分成若干页

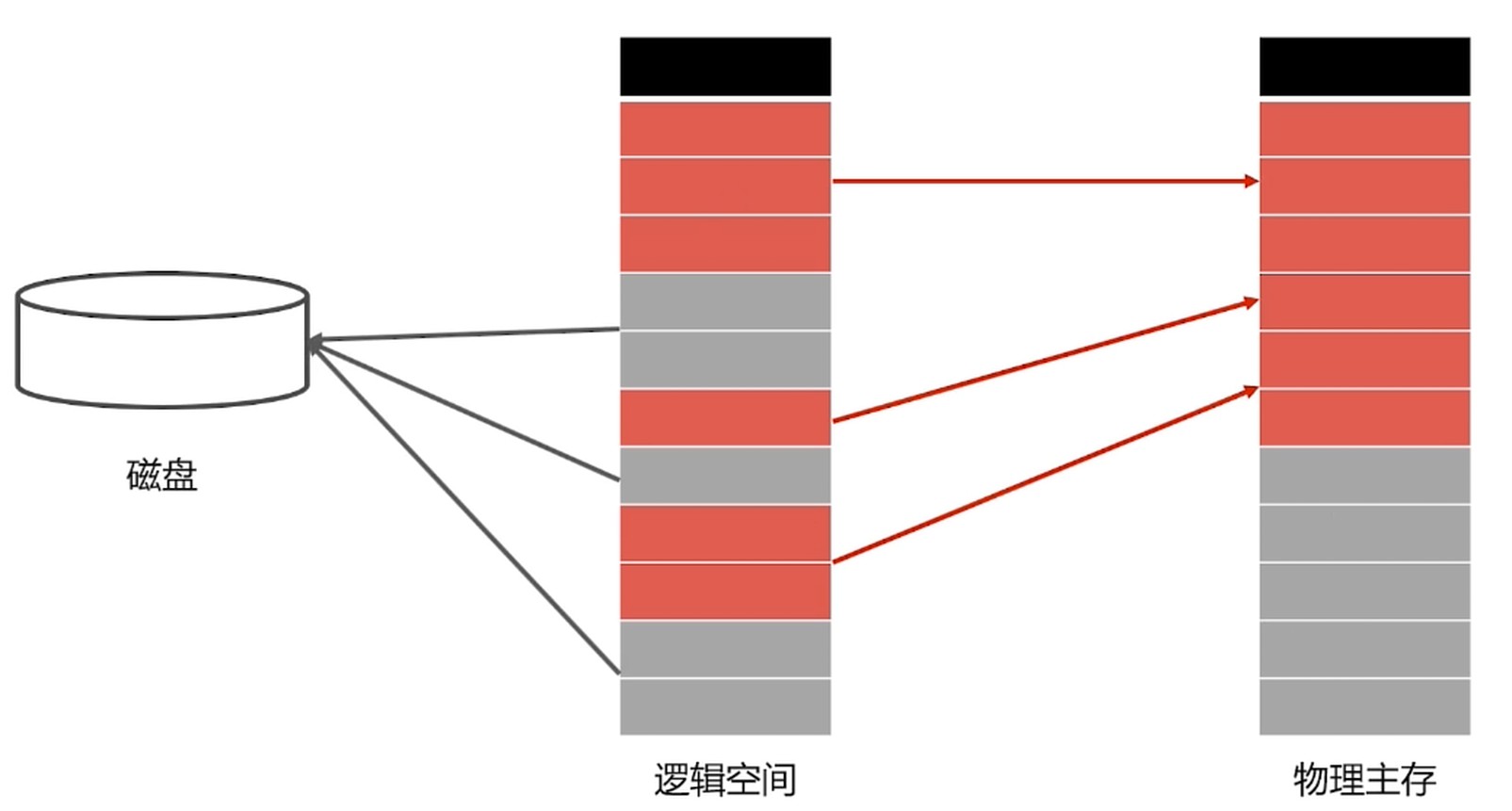
虚拟内存
虚拟化: 看似是无穷, 其实上资源是有限的.
原因
- 有些进程需要的实际内存很大, 超过物理内存.
- 多道程序设计, 使得每个进程可用物理内存更加稀缺.
- 不可能无限增加物理内存, 物理内存总有不够的时候.
实现
- 把程序使用内存使用数据结构划分, 切割成更小的块, 将一块块分配, 将部分暂时不使用的内存放置到辅存.
- 维护一张映射表, 这张表让进程认为自己是连续的.
程序的局部性原理
CPU访问存储器时, 无论时存取指令还是存取数据, 所访问的存储单元都趋于聚集在一个较小的连续区域中.
所以程序运行时, 无需全部装入内存, 转载部分即可.
如果访问页不在内存, 则发出缺页中断, 发起页面置换.
从用户层看, 程序拥有很大的空间, 即是虚拟内存.
总得来说, 实际是对物理内存的补充, 速度接近于内存, 成本接近于辅存.
虚拟地址空间
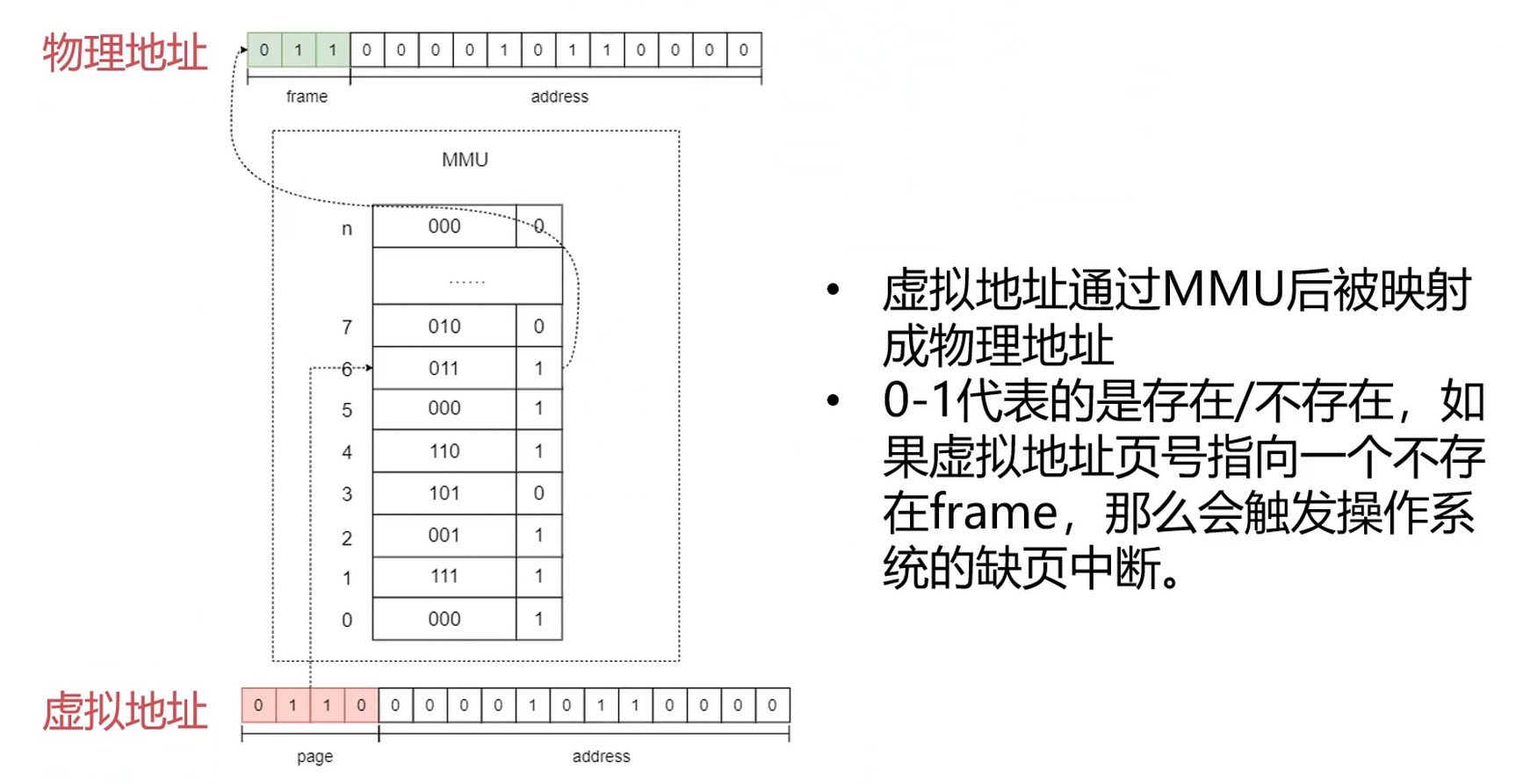
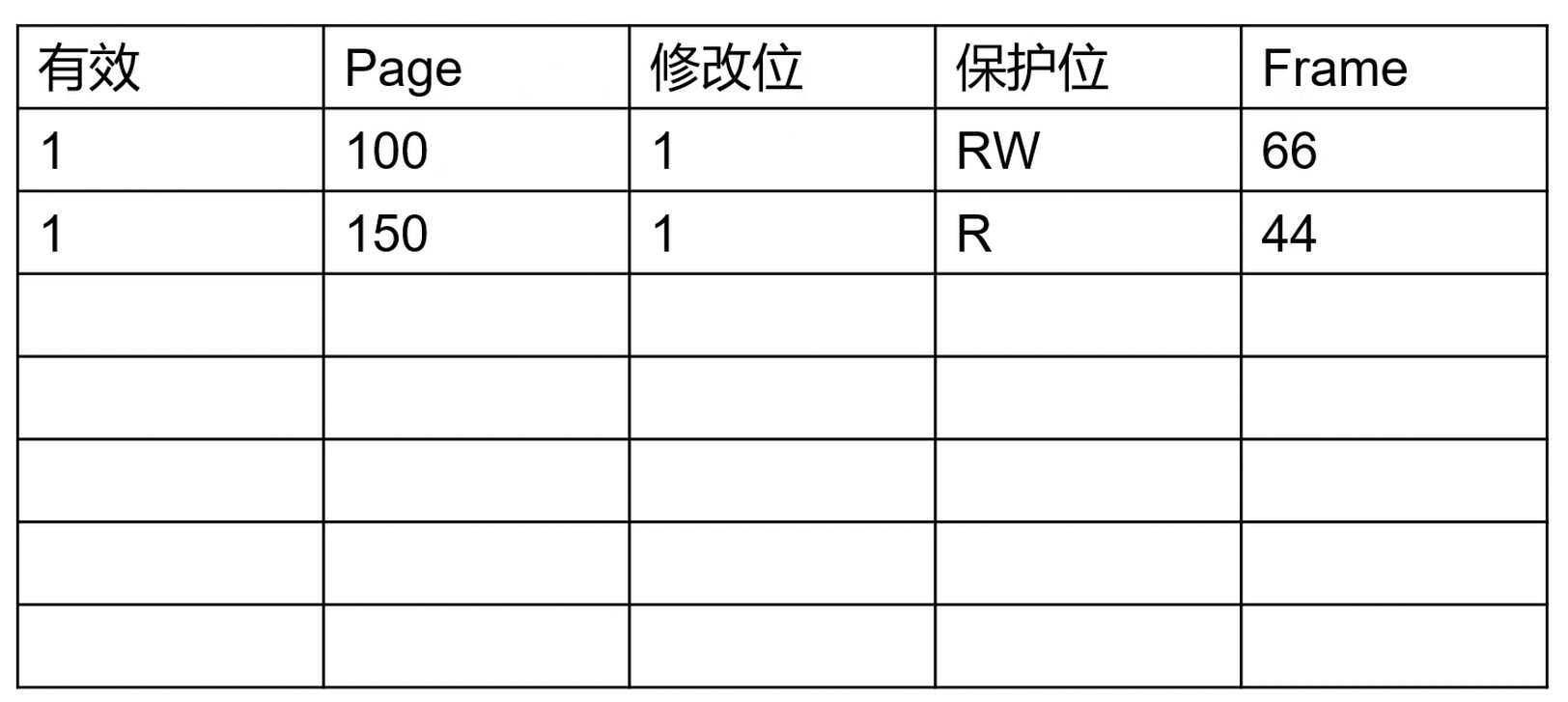
页表

页表项

FRAME: 真实内存的一块.
访问位: 可以判断是否可以被swapping到磁盘中去.
[在不在]位, 如果不在会触发缺页中断, 通过内核把真实的内存拿进来.
举例子:
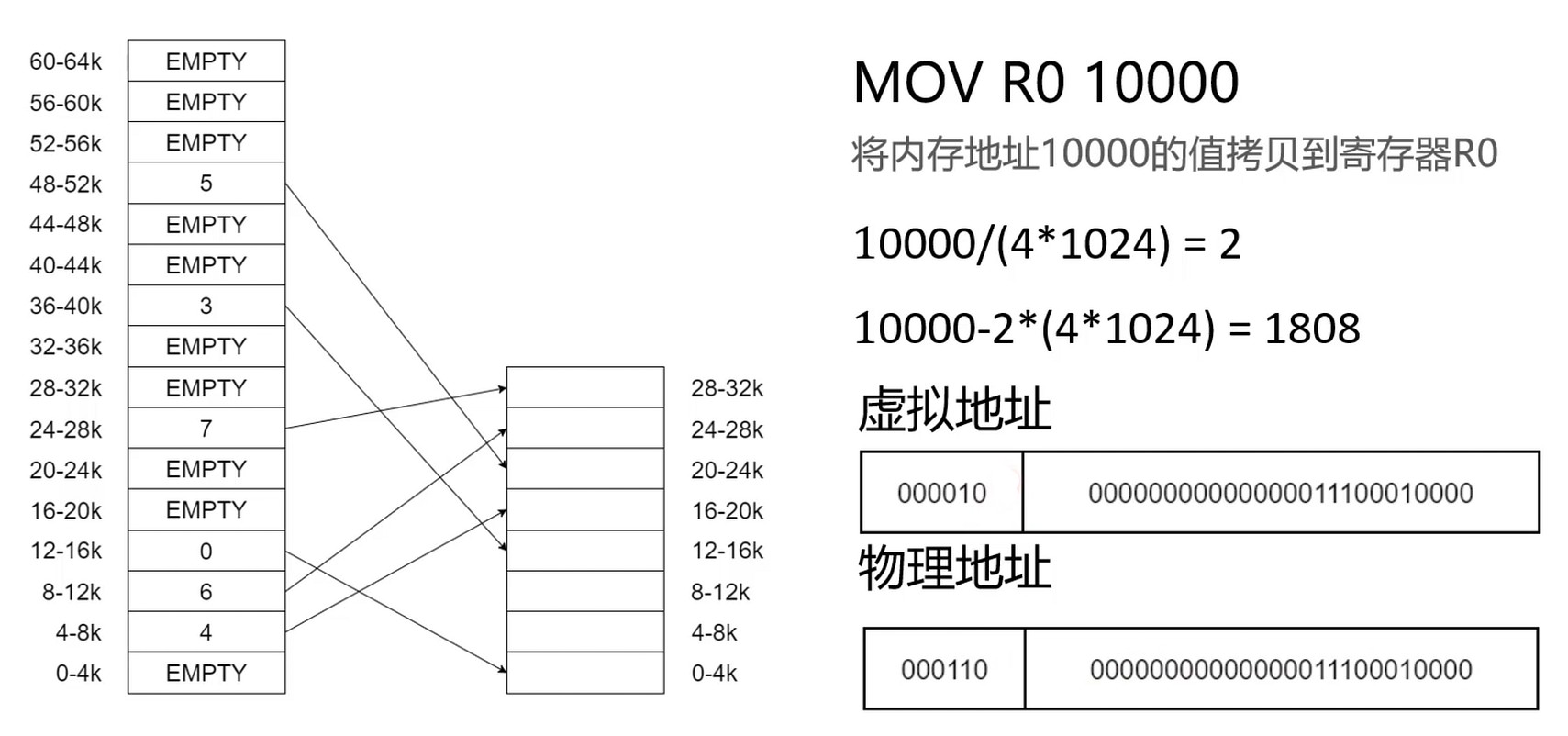
10000 其实是个虚拟地址
内存管理单元
MMU – Memory Management Unit
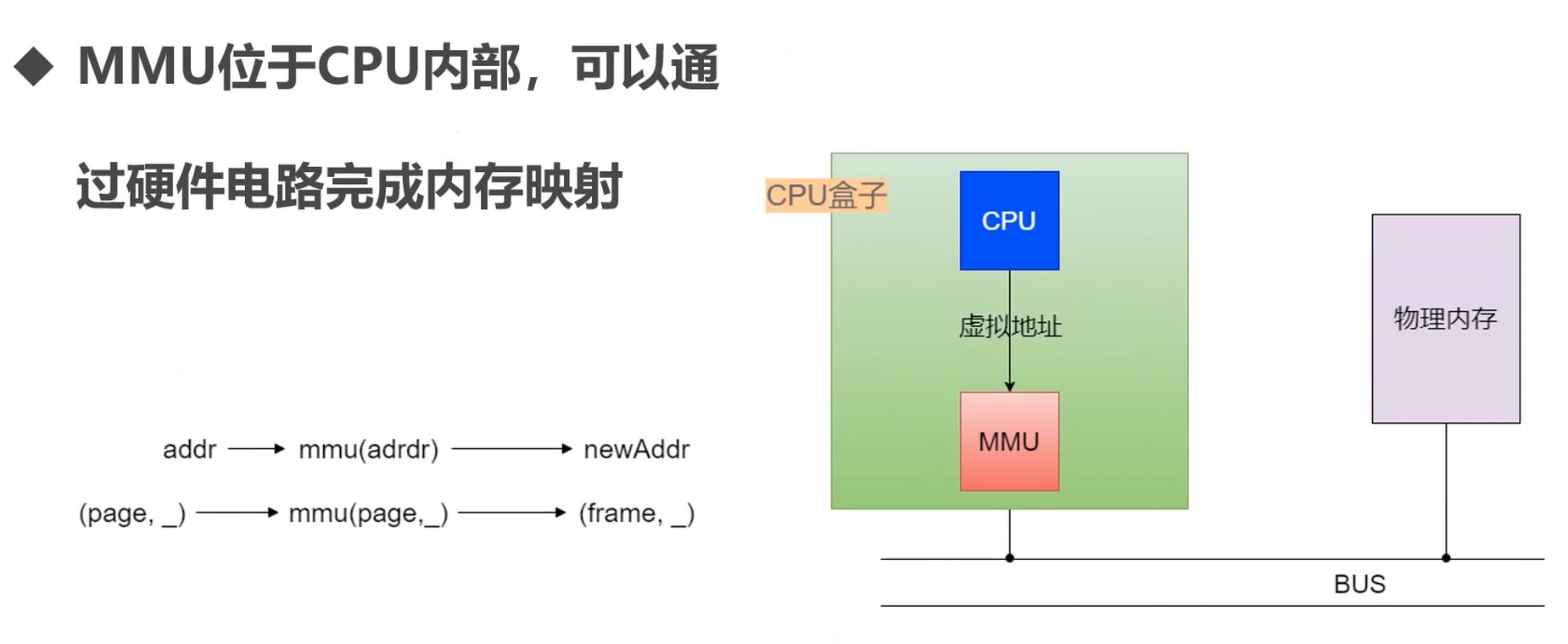
通过专门的硬件电路解决内存映射计算的问题.
MMU工作流程
MMU的页表由来
- 操作系统告诉 MMU 页表在内存中的位置 -> MMU 加载页表 -> MMU会自己利用页表进行地址转换
- CPU 对MMU中页表中的条目数量大小是有限制的, 有的会几个M, 也可以更大
- 操作系统内核中有负责MMU管理模块
缺页中断
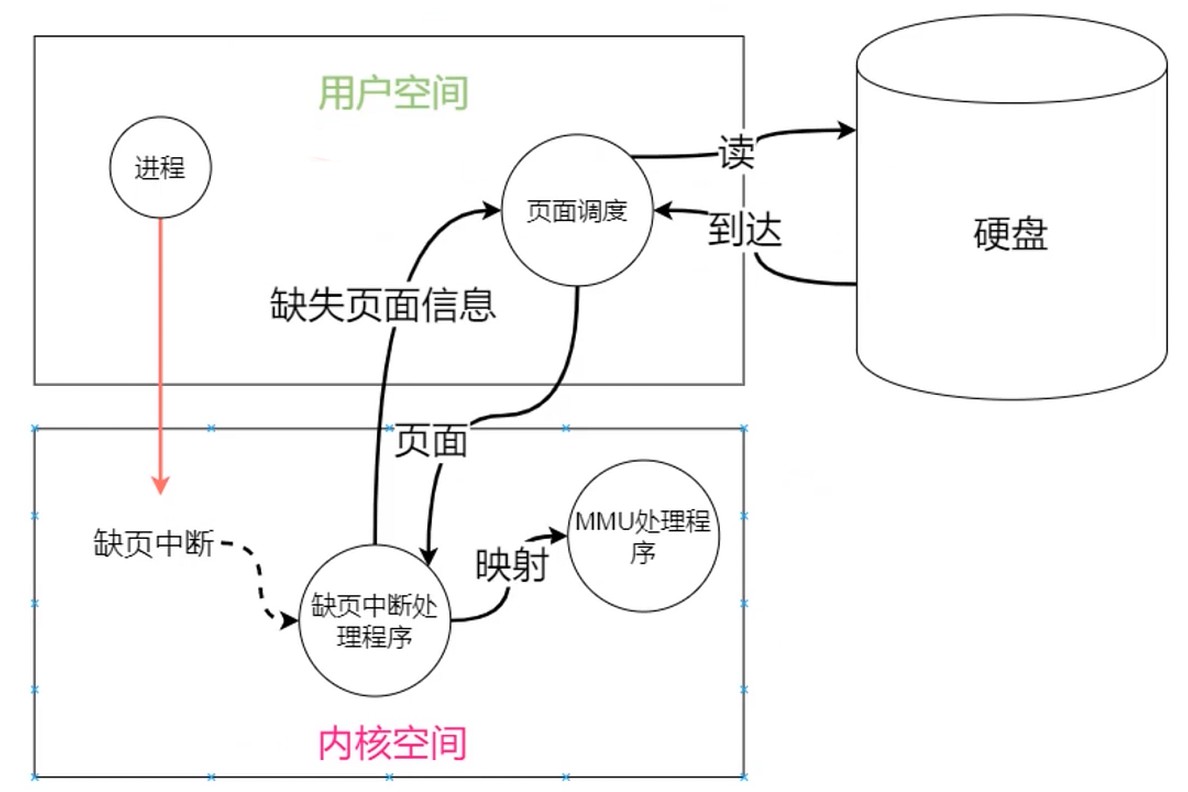
页面调度不在内核, 因为内核是基于最小程序来设计的.
多级页表
使用多级页表节省空间.
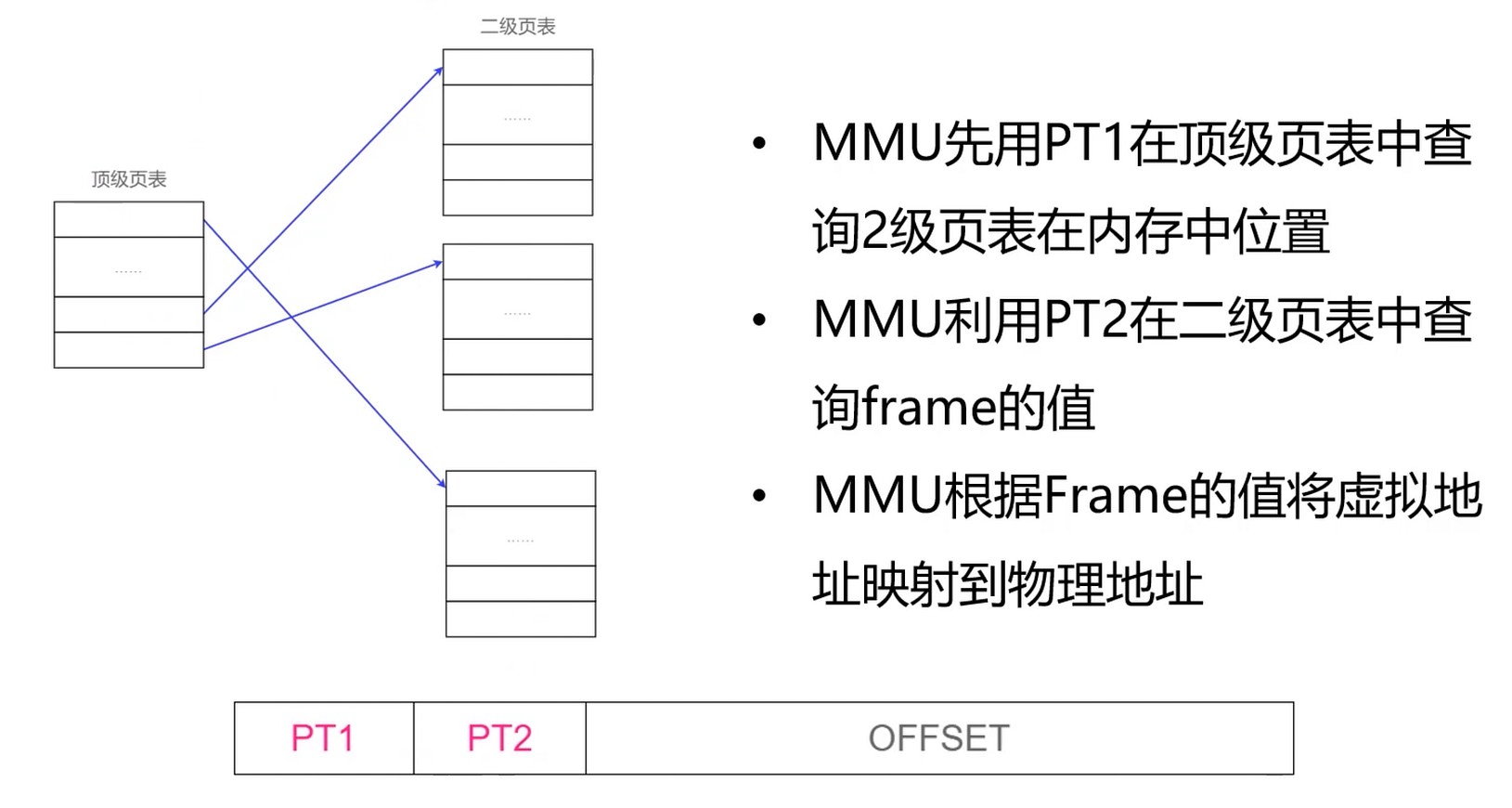
- 如果只有一级, 比如: 4G/4kb就需要1m的页表条目(以4kb为一块进行划分)
- 如果是两级
- 顶级页表需要1k条目
- 每个二级页表需要1k条目, 一共1k个二级页表, 这样反而还多了1k个
- 多级页表是个跳跃结构, 因为进程不会把所有4G内存都占满, 用到了再添加, 这样就节省了空间.
多级页表虽然节省了空间, 但是会增加 MMU 的计算次数. 所以引入了快表.
快表
是一个小型硬件设备–也叫做转换检测缓冲区(Translation Lookaside Buffer), 可以加速 MMU 的读写.
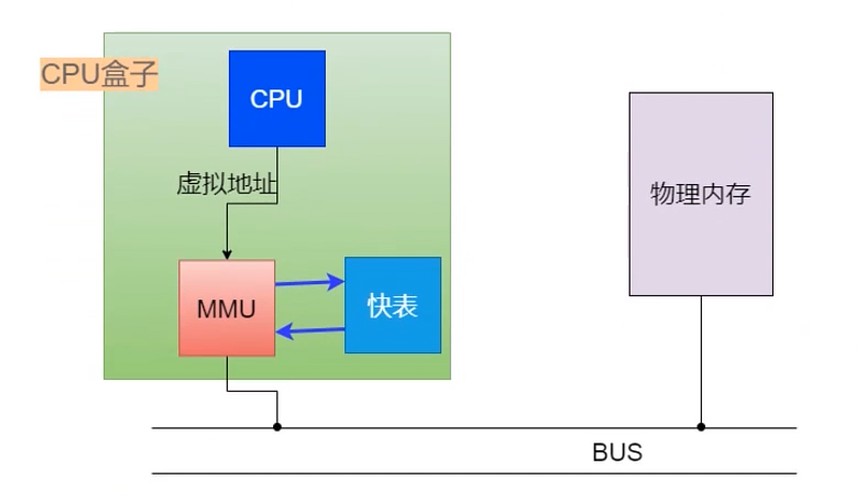
命中率会很高.
虚拟内存置换算法
- 先进先出算法(FIFO)
- 最不经常使用算法(LFU)
- 最近最少使用算法(LRU)
主存页面替换时机–主存缺页的时候.
- 替换策略发生在Cache-主存层次, 主存-辅存层次
- Cache-主存层次的替换策略主要是为了解决速度问题
- 主存-辅存层次主要是解决容量问题
Linux存储管理
Buddy内存管理算法
- 基于计算机处理二进制的优势, 具有极高的效率
- 主要是为了解决内存外碎片问题
页内碎片: 已经被分配出去的内存空间大于请求所需的内存空间, 不能被利用的内存空间就是内存碎片
页外碎片: 还没有分配出去, 不属于任何进程, 但是由于大小而无法分配给申请内存空间的新进程的内存空闲块
向上取整为2的幂大小. 70k -> 128k, 129k -> 256k
伙伴系统. 一片连续内存的”伙伴”是相邻的另一片大小一样的连续内存.
创建一系列空闲块链表, 每一种都是2的幂
对内存的处理都是以2的幂来处理的, 计算机处理2的幂时速度时最快
其实是将内存外碎片问题 -> 内存内碎片问题
Linux 交换空间
- 交换空间(Swap)是磁盘的一个分区
- Linux 物理内存满时, 会把一些内存交换到Swap空间
- Swap空间时初始化系统时配置的
特点
- 冷启动内存依赖(冷启动程序只在启动时要使用的那一块内存)
- 系统睡眠依赖
- 打井程依赖
这个概念其实和虚拟内存很相似.

程序语言的内存管理模型

段和段之间随着内存的增长碰撞怎么办? 虚拟化.
进程是对计算机资源的虚拟化.
线程是对CPU的虚拟化.
内存是对物理内存的虚拟化.
段是对虚拟内存(页表)的虚拟化.
所以, 资源稀缺的时候, 就可以想到虚拟化, 让资源可以无限抽象(例如货币).
Stack分配内存其实是离散的.
生活在虚拟世界, 不断虚拟, 虚拟到不知道底层是什么.
堆
- 一种数据结构(二叉树, 然后用数组去描述了).
- 操作系统中是程序对内存的一种抽象(杂乱无章的对象).
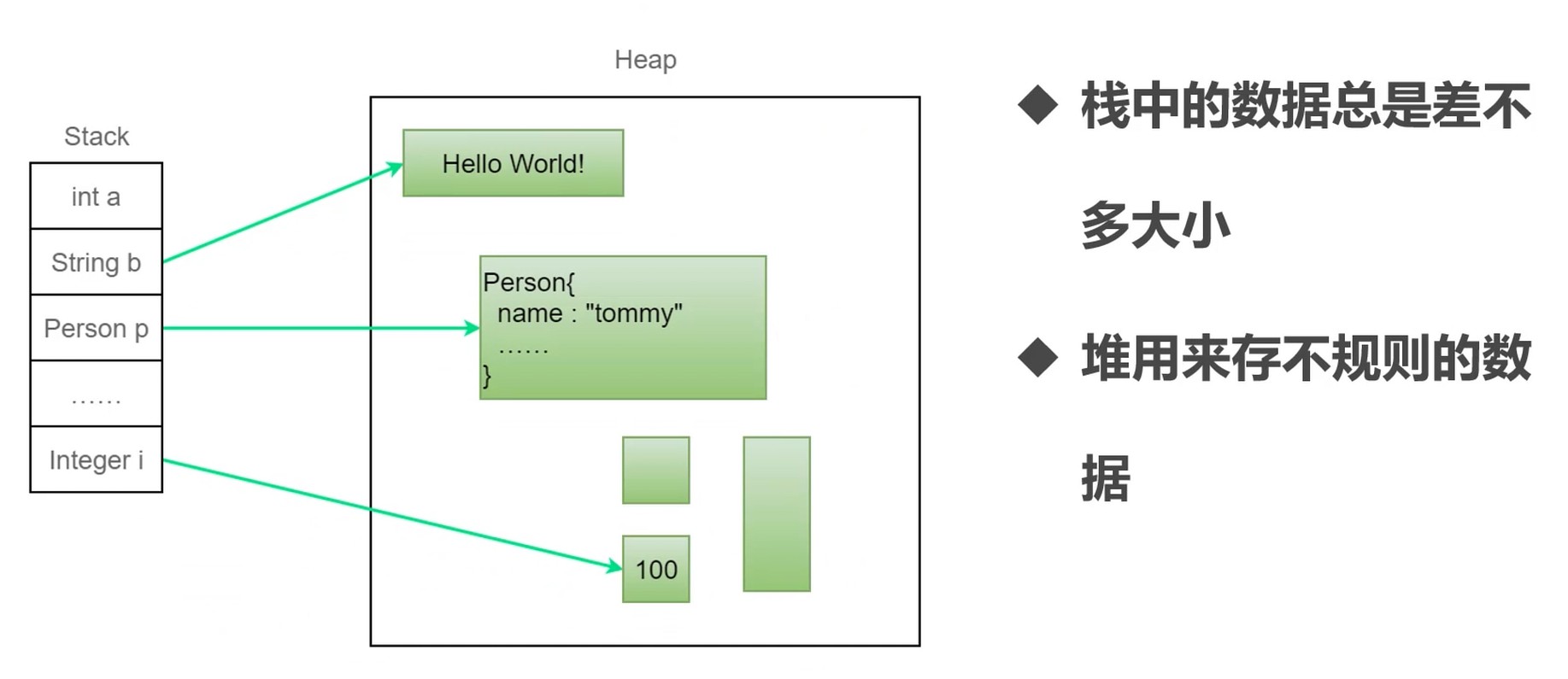
栈上存的是对象的地址, 而对象是存在堆上的, 而堆是由段组成, 每个段在页表有对应的映射, 而页表就映射到物理内存.
堆如何分配有很多算法.
如何管理内存
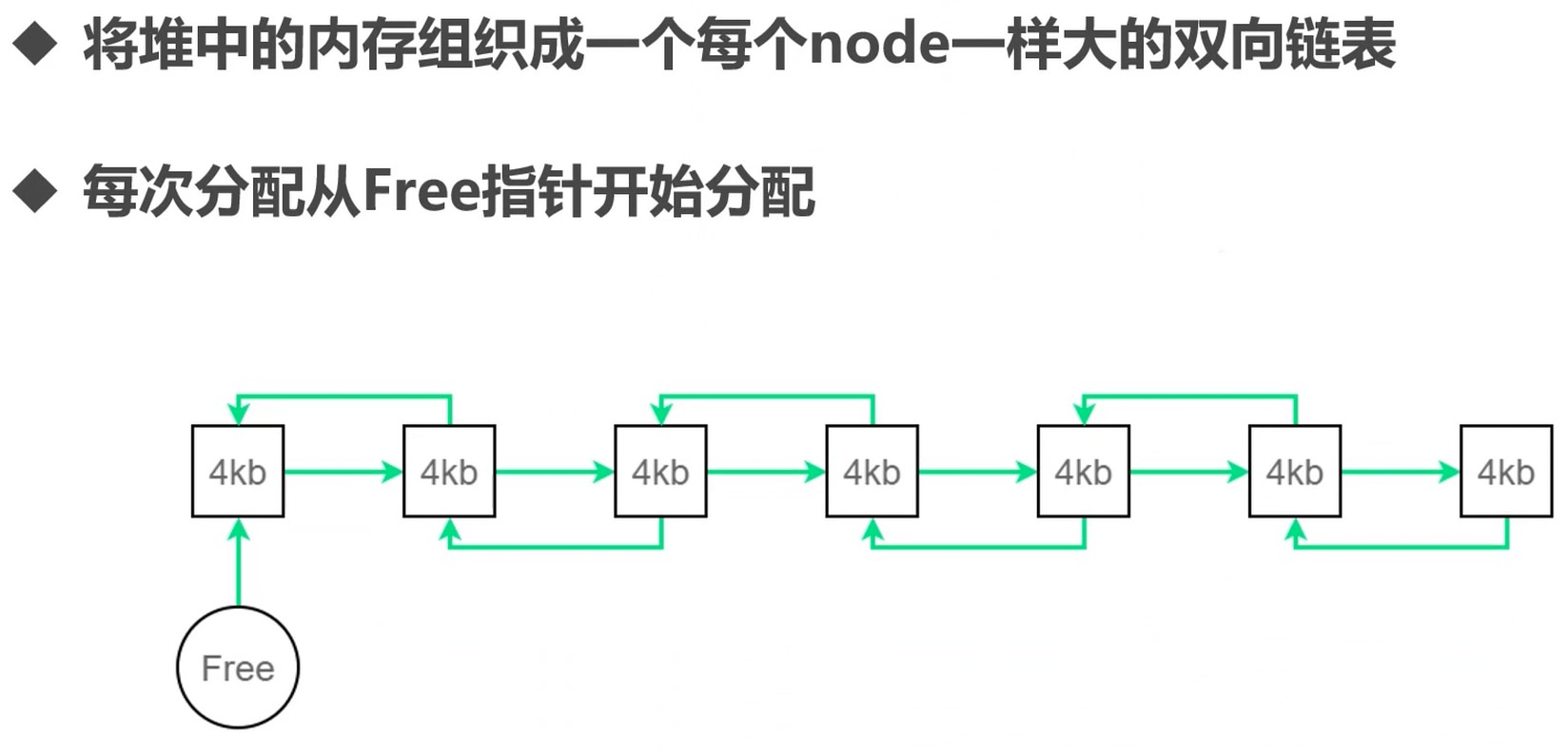

如果分配的基本单位不能被申请的内存整除, 那么怎么办?
另一种方式, 基于链表, 把内存划分成不同大小. 这样可以根据对象的大小来选择, 一个个填进去.
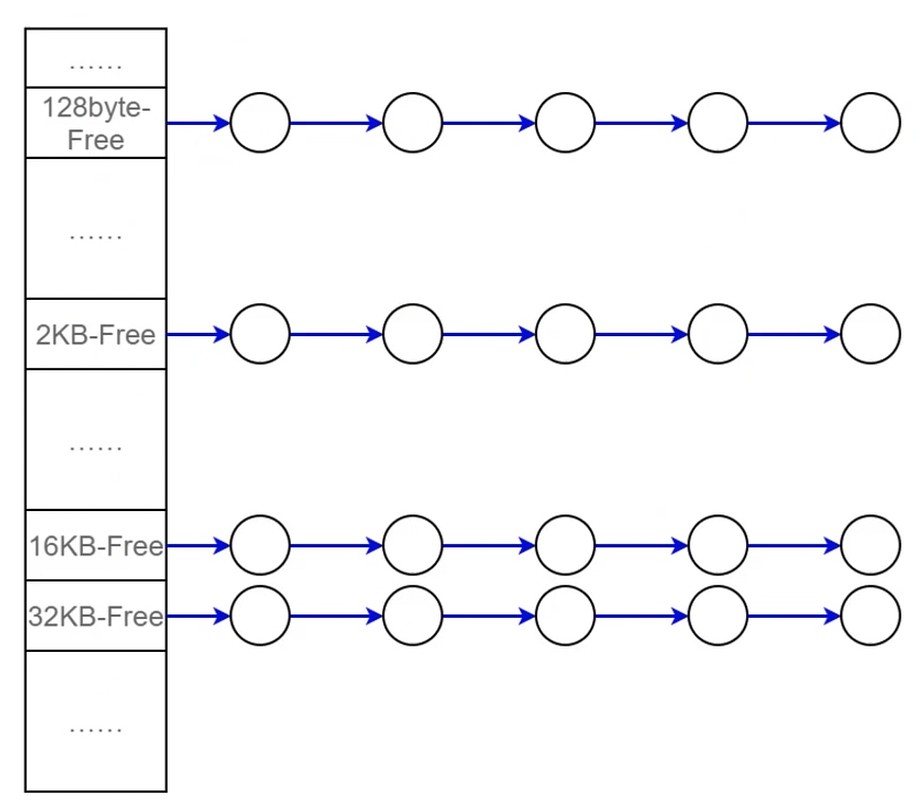
现在主流做法–slot
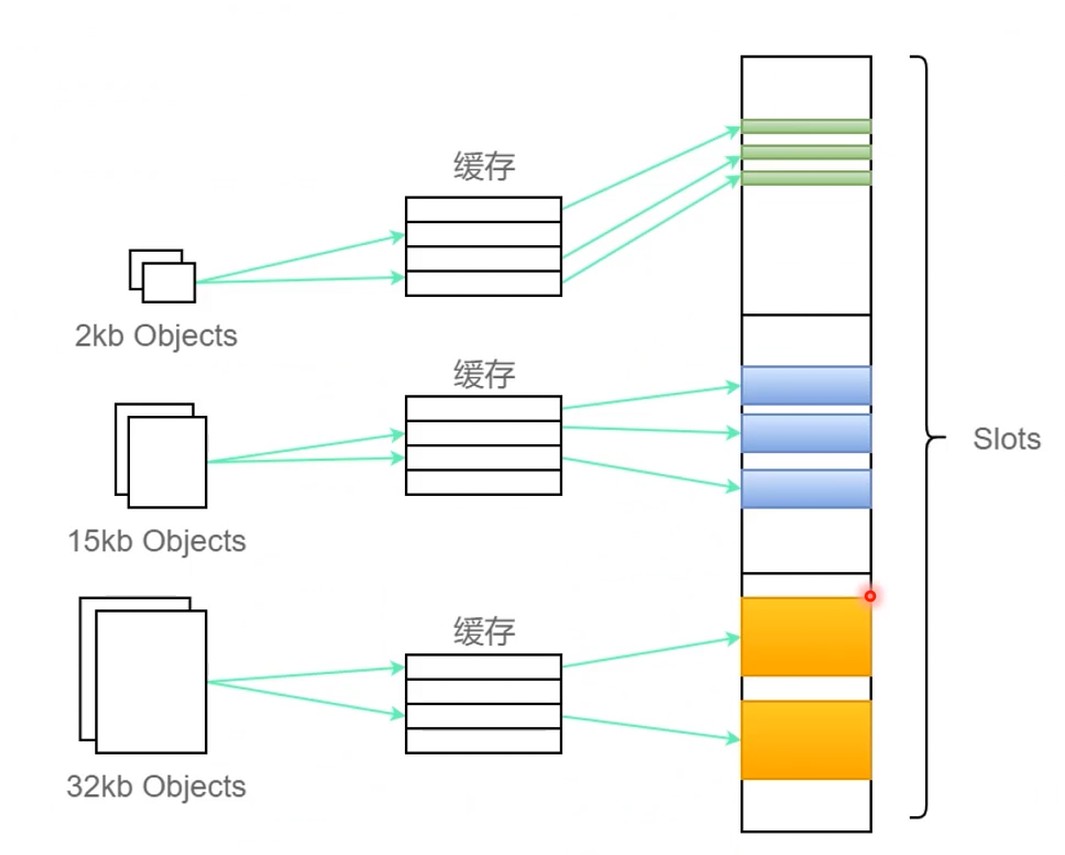
程序语言也用slot法管理内存吗?
- 部分没有虚拟机的语言, 创建对象时在 cache-slot 上的. 比如 c 的 malloc 就是直接分配一个合适大小的 cache, 依赖于操作系统
- 还有一些虚拟机的语言(v8, jvm), 有自己的内存管理
- 另一方面, 程序语言不需要像操作系统一样预留大量类型的slot等待分配, 因为程序大小不一, 功能也不一样
而内存回收这一块, 没有通用解!!
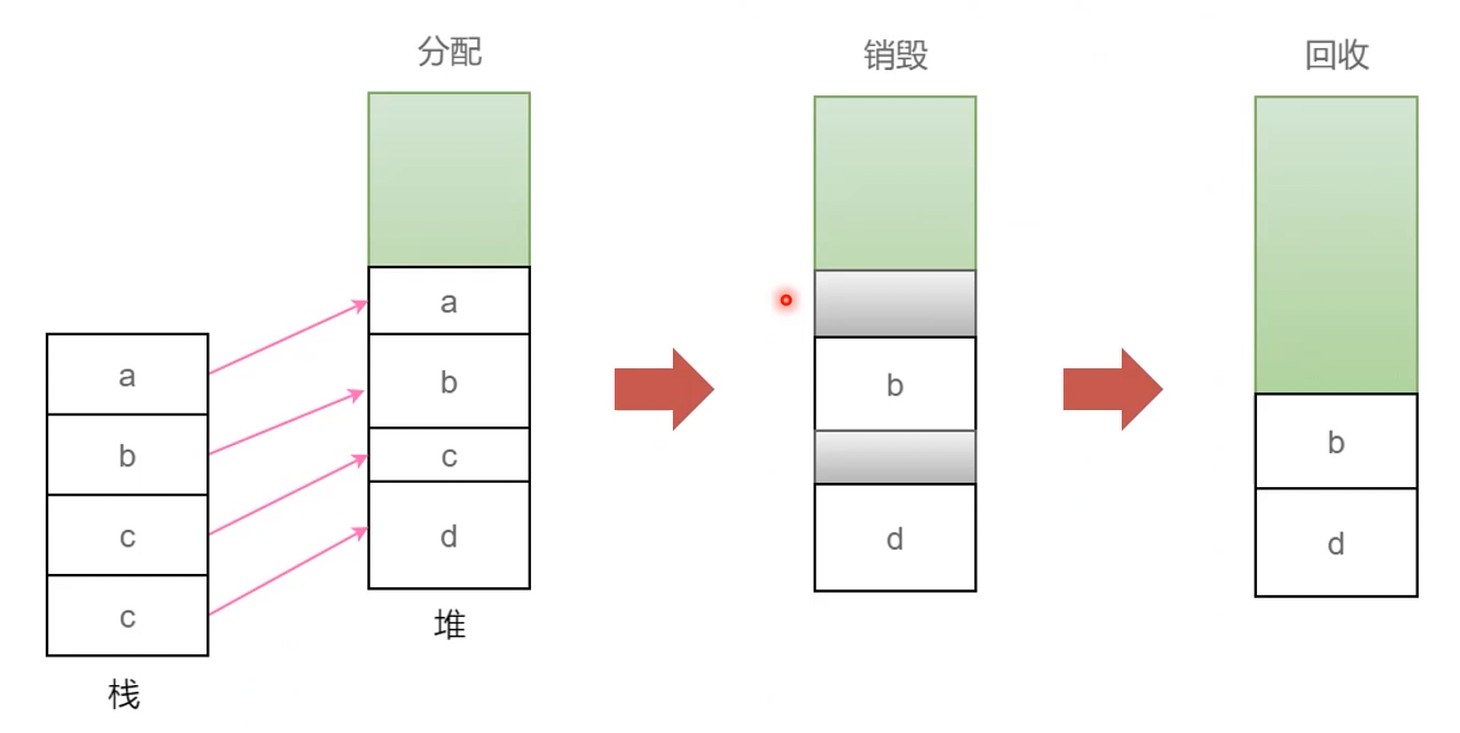
回收a,c的时候, 如何尽量不去影响b和d.
年代分层, 解决整理时STW的问题.
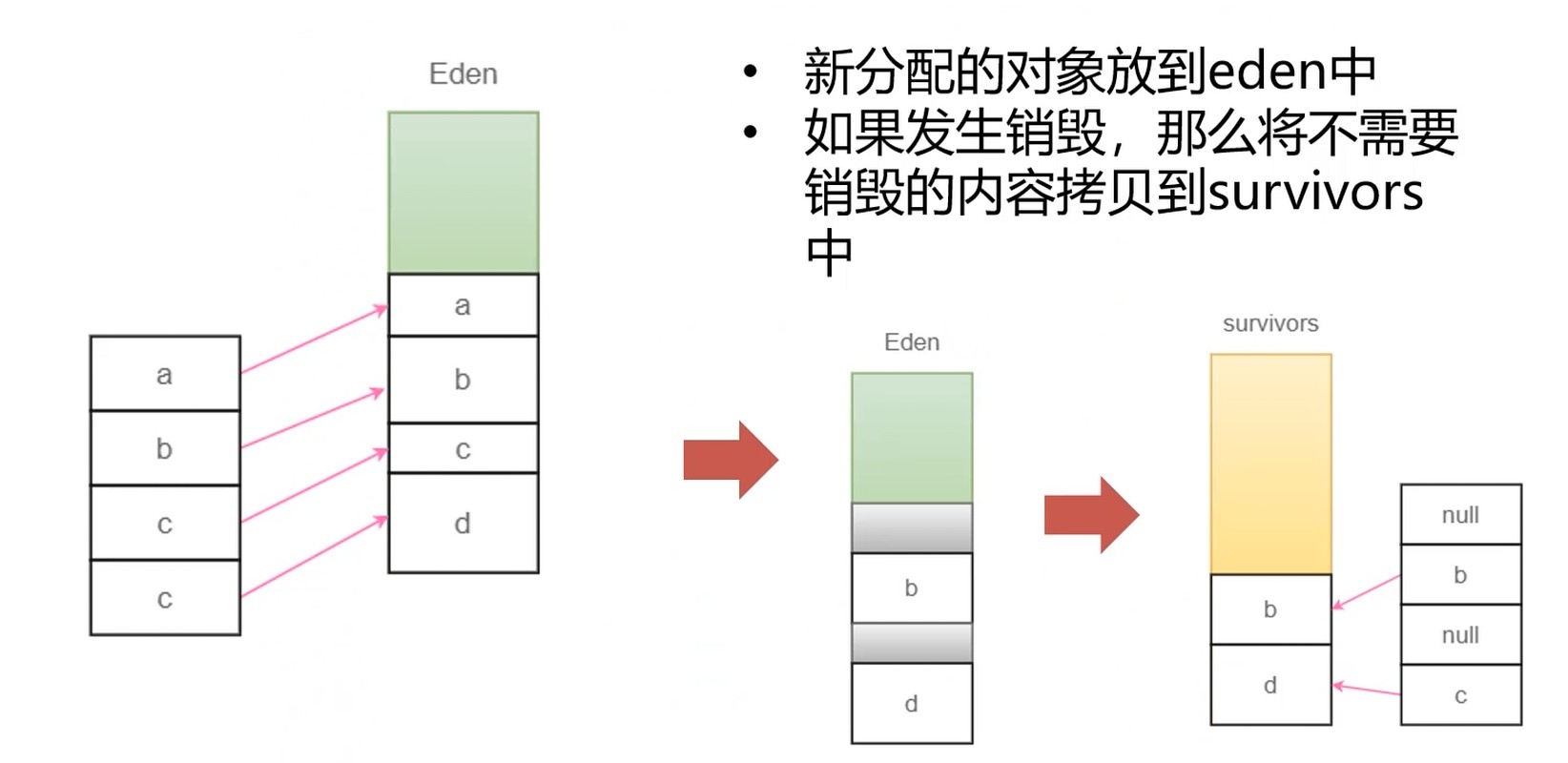
垃圾回收算法
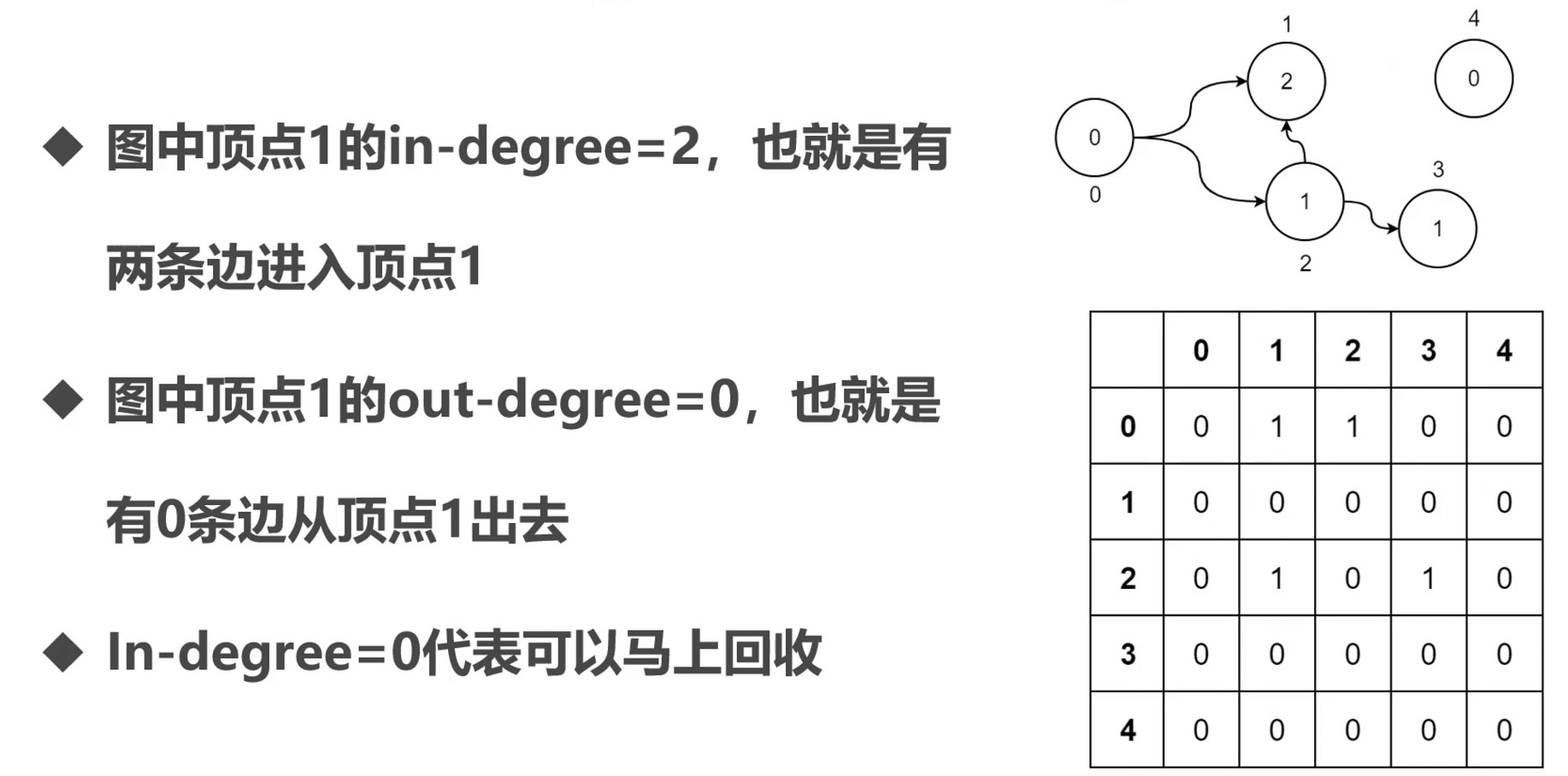
图和引用计数
不使用的对象怎么处理?
- 如何衡量一个对象不再被使用了
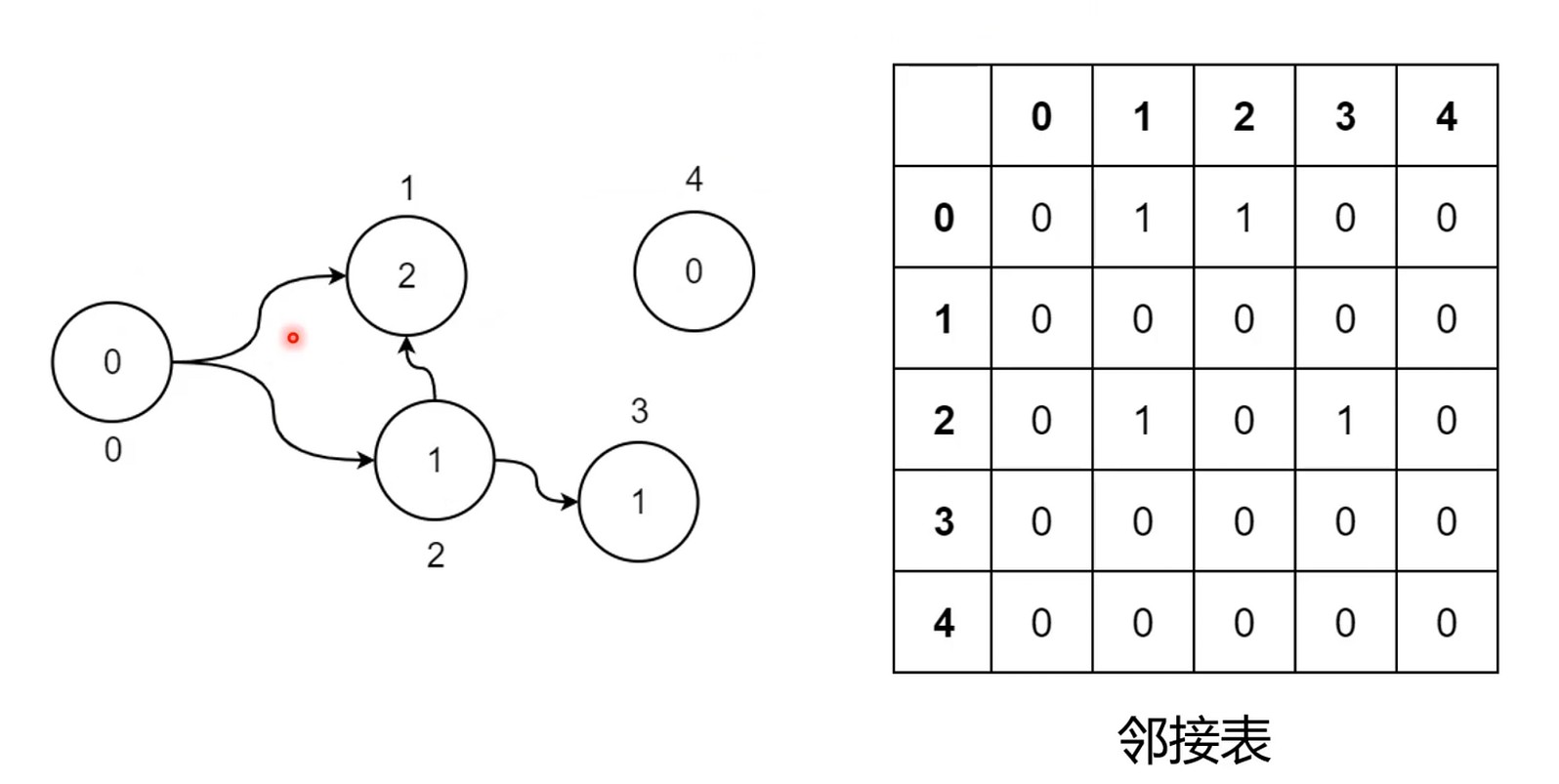
可以使用二维数组存下图.

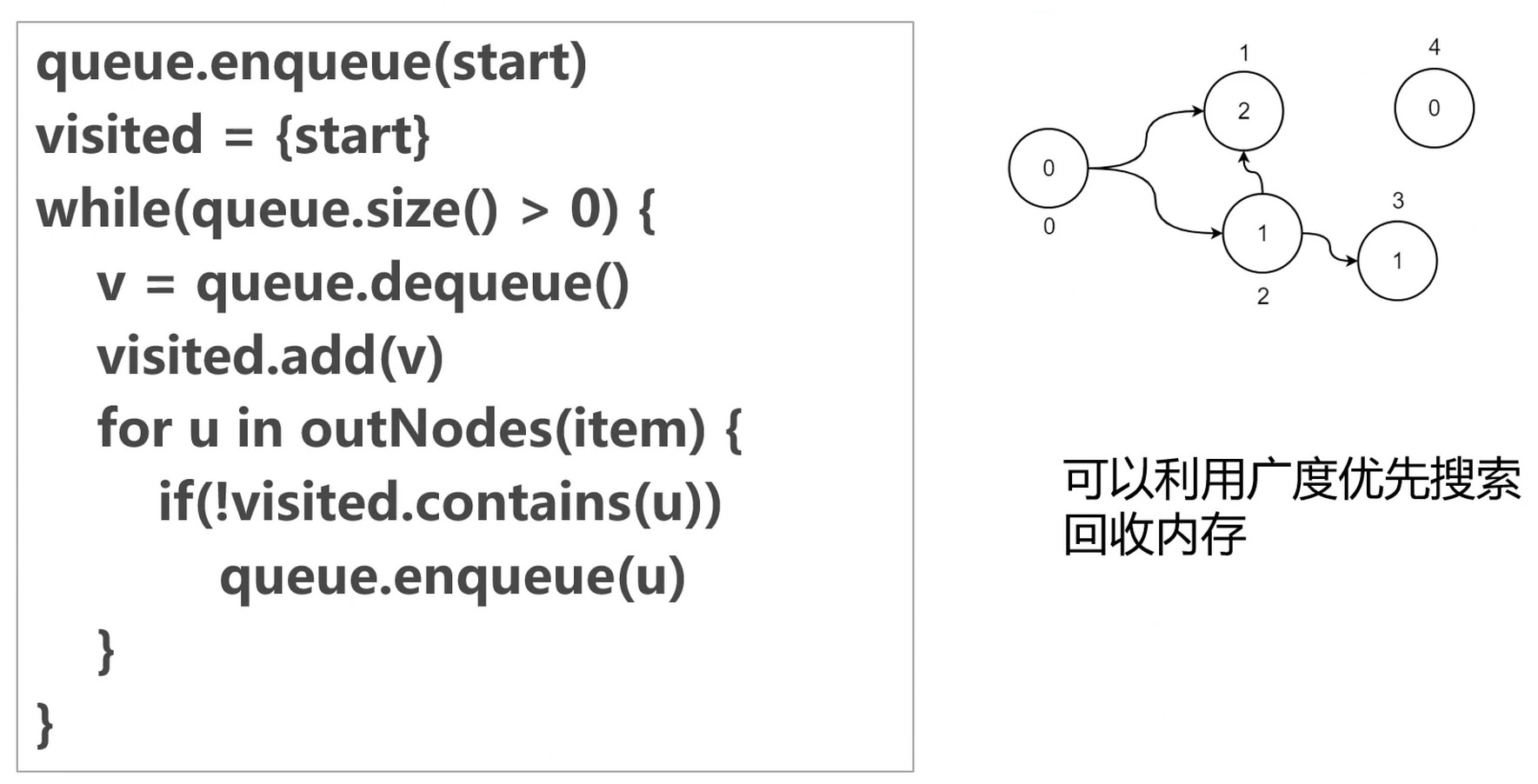
广度优先搜索(BFS算法)
产生的问题
- 基于扫描的引用计数策略性能太慢了–基于图策略
- 每个对象需要多维护一个引用(ref)–开销问题
- 如果GC程序是另外的线程, ref的维护会产生竞争条件, 处理GC时会 STW
标记, 扫地, 整理
gc使用的重要场景
- 内存需要被反复利用的场景
- 大量的对象被分配和回收
- 高并发场景
标记清除算法
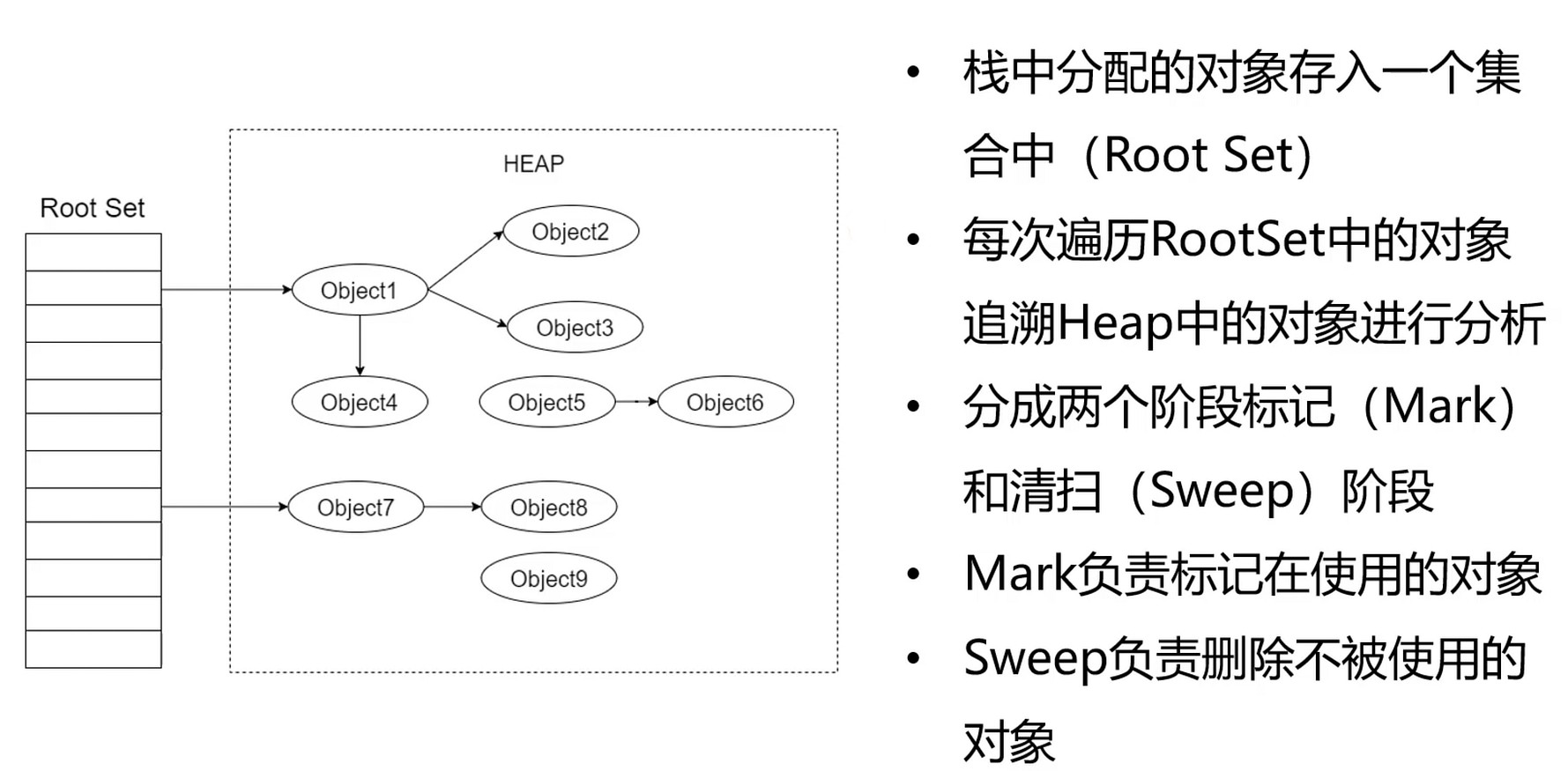
GC角度看程序世界
对于GC而言, 除了自己做的事情, 其它事情都属于Mutator.
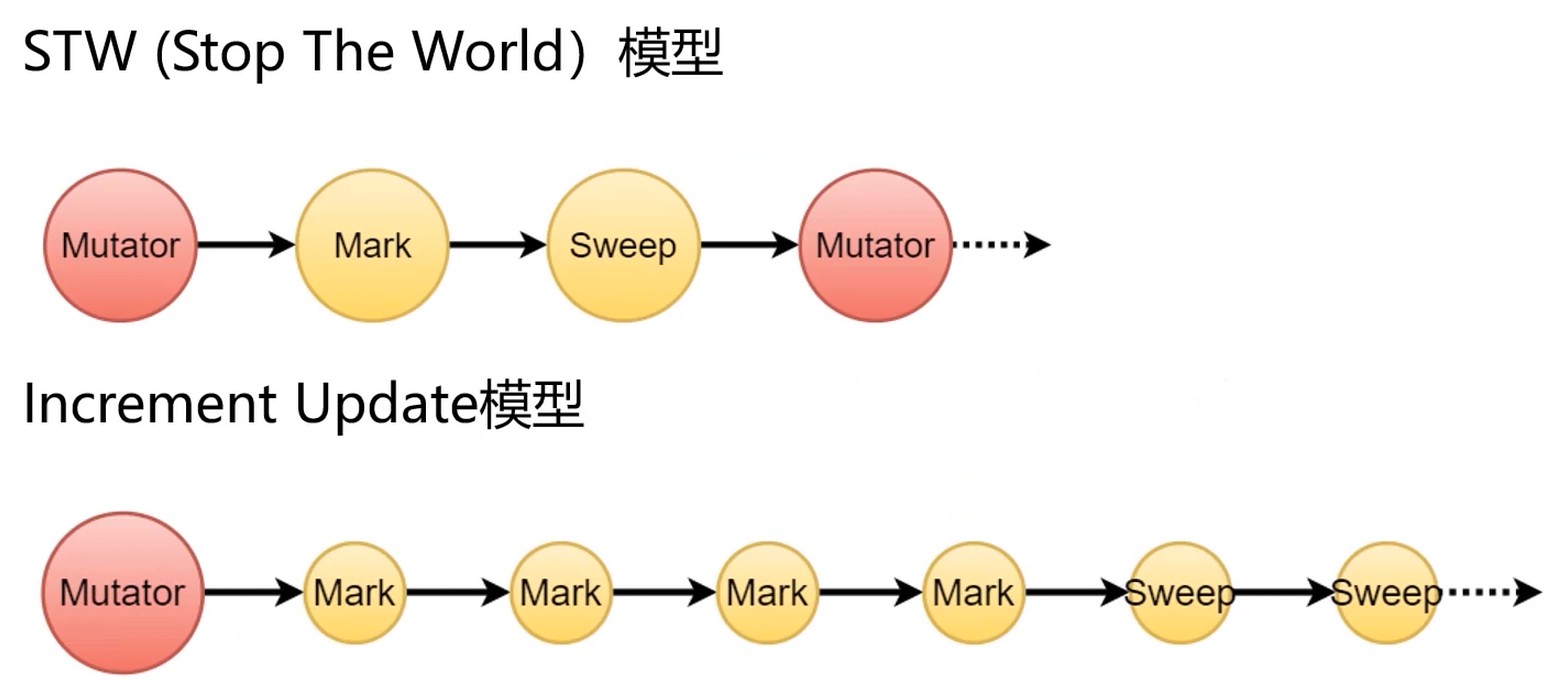
STW : 一个串行的模型. 一次回收较多, 消耗时间更多
Increment Update: 增量更新模型. 每次更新少点, 所以体验更好.
Concurrent Update: 并发更新模型.
很难做到不STW, 但是可以缩短STW的时间, 让用户感知程序是一个连续的模型.
三色标记-Tri-Color Mark
白: 需要回收; 黑: 不需要回收; 灰: 中间地带.
GC的目的就是跑赢mutation.
文件管理
- 文件系统
- 文件的逻辑结构
- 辅存的存储空间分配
- 目录管理
文件系统
一种抽象机制, 通过给存储在磁盘上的数据每个起一个名字, 每个叫做一个文件, 提供根据文件名操作这些信息的方法(读写修改等).
目录是一种特殊的文件, 它用来对文件进行分类.
由于不同的存储设备, 物理结构不一样, 所以操作系统在这之上进行了抽象–物理块, 目前使用比较多的是 4kb 的块.
物理块是操作系统最底层的抽象了. 在这之上就可以构建文件系统了.
空闲物理块
文件系统的布局
引导块 一般硬盘最低的地址空间(MBR).
魔数(Magic Number), 也叫[幻数], 原指原子核中质子数和中子数的某个特定数值. 处于这个数值的原子核会很稳定.
Java.class 文件, 开头4个字节: 0xCAFEBABE
DOS可执行文件开头, 0x00004550
文件的逻辑结构
- 磁盘上信息的一种抽象. 把信息抽象成拥有名字的一个集合
- 不同文件系统对于文件的表示方式不同, 但是提供相似的操作接口(POSIX标准)
- Portable Operation System Interface
逻辑结构的文件类型
- 有结构文件: 由一个定长的记录和可变长的记录组成; 定长记录存储文件格式, 文件描述等结构化数据项; 可变存储文件的具体内容.
- 文本文件
- 文档
- 多媒体文件
- 无结构文件: 也称为流式文件; 文件内容长度以字节为单位.
- 二进制文件
- 链接库
顺序文件: 按照顺序存放在存储介质中的文件.
磁带的存储特性使得磁带只能存储顺序文件.
顺序文件时所有逻辑文件中存储效率最高的.
顺序文件对增删改效率很低.
索引文件
- 可变长文件不适合使用顺序文件格式存储
- 索引文件是为了解决可变长文件存储的文件格式
辅存的存储空间分配
分配方式
- 连续分配
- 顺序读取文件内容非常容易, 速度很快
- 链表分配
- 将文件存储在离散的盘块中
- 需要额外的存储空间存储文件的盘块链接顺序
- 索引分配
连续分配
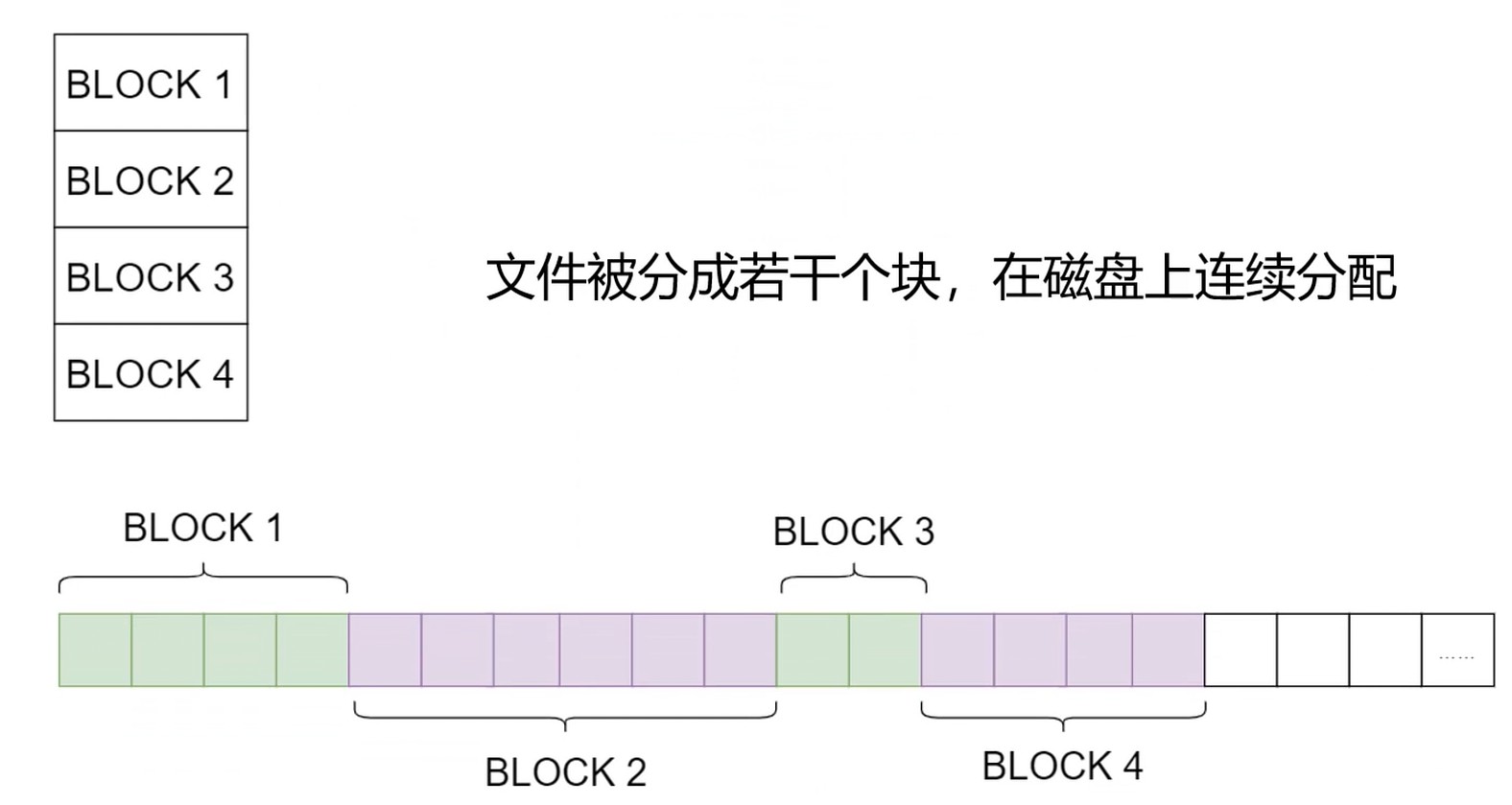
连续分配–碎片问题. 解决: 磁盘碎片整理.
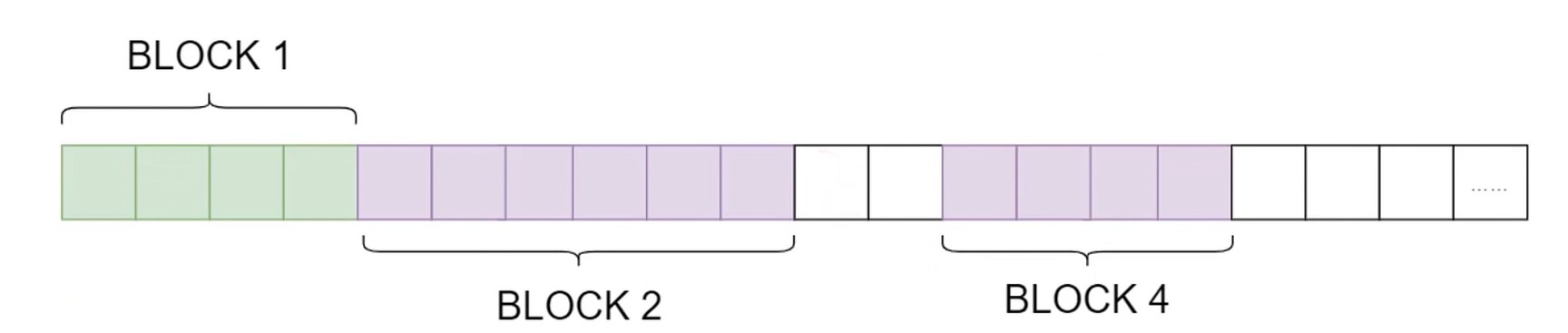
链表分配
隐式分配

每一块有额外的开销, 所以会不足4kb.
显式分配
也是内存中的分配表, 简单来说就是在内存中维护了一份链表.
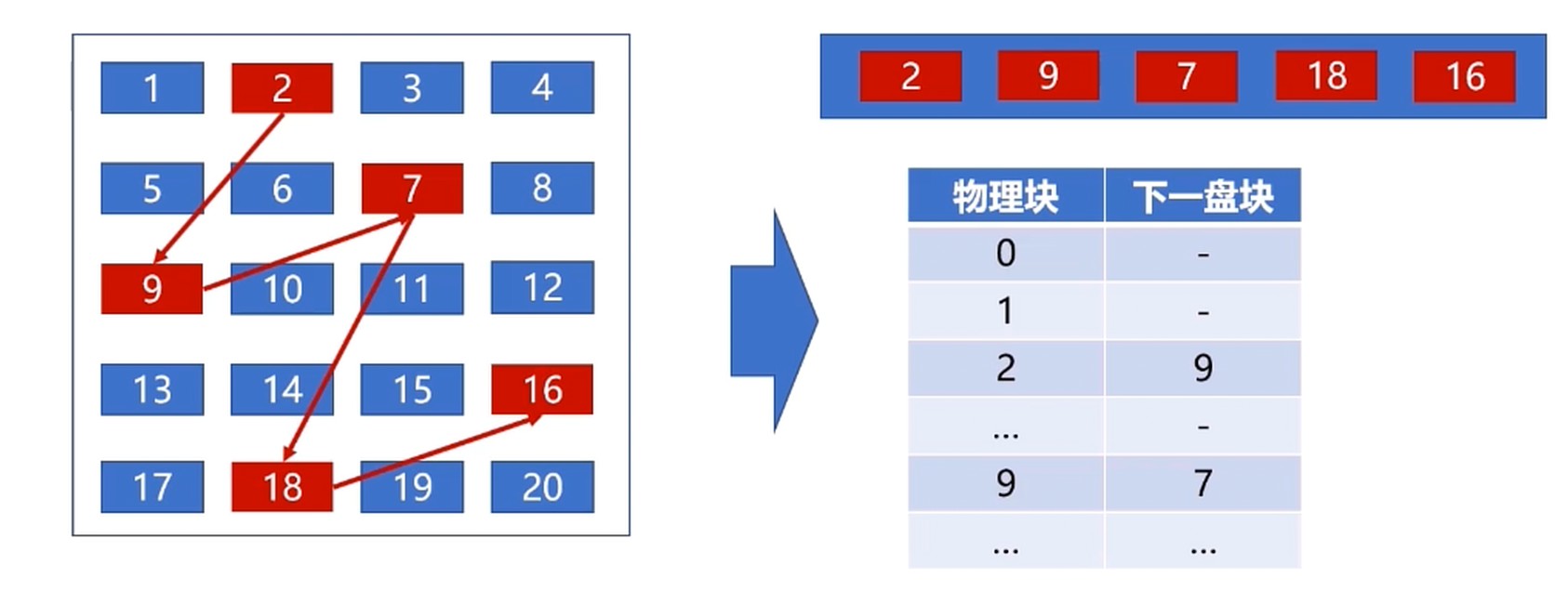
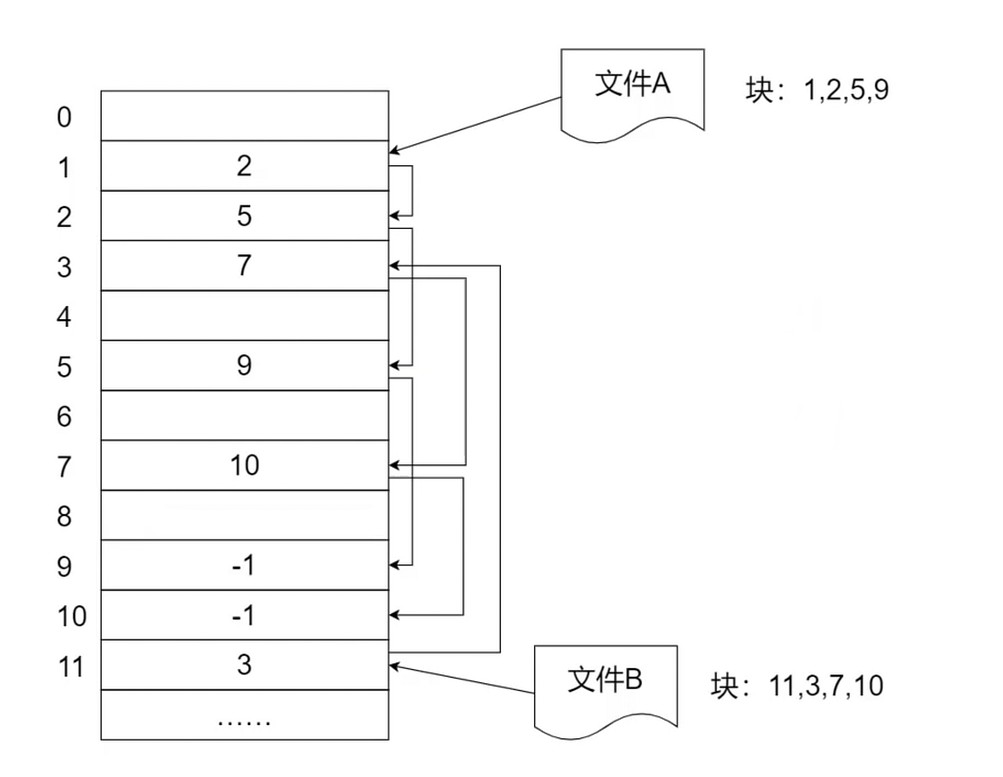
-1 说明文件结束了.
这个也是FAT(File Allocation Table)的工作原理.
- 不支持高效的直接存储(FAT记录项多)
- 检索时FAT表占用较大的存储空间(需要将整个FAT加载到内存)
- 1T的硬盘, 每个块 4k 需要多大的 FAT 表?
- 1T = 2^30^ k. 1T/4k * 4byte = 2^30^ / 4 * 4byte = 1G
索引分配
- 把文件的所有盘块集中存储(索引–index-node)
- 读取某个文件时, 将索引文件读取到内存即可
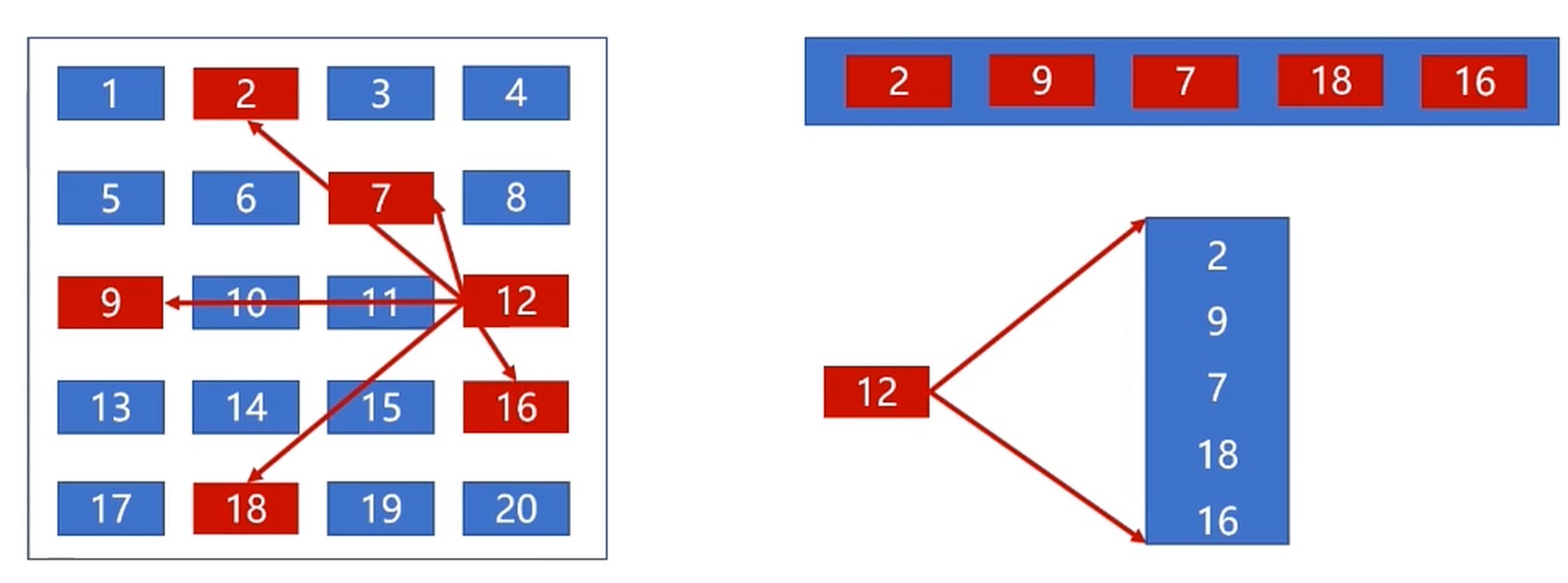
- 每个文件拥有一个索引块, 记录所有盘块信息
- 索引分配方式支持直接访问盘块
- 文件较大时, 索引分配方式具有明显优势
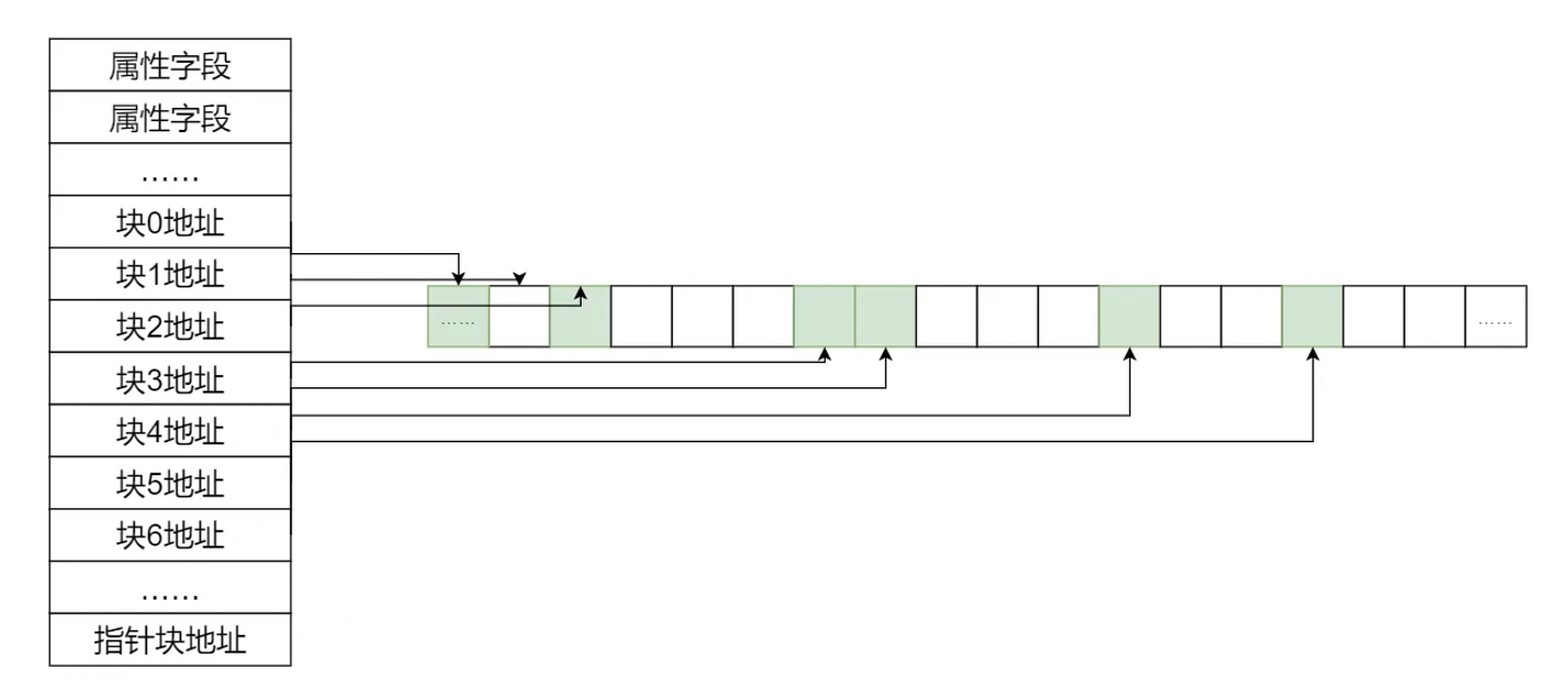
文件由索引节点组成, 而一个索引节点的大小是固定的. 需要的时候再载入内存, 而 FAT 是要整个载入内存.
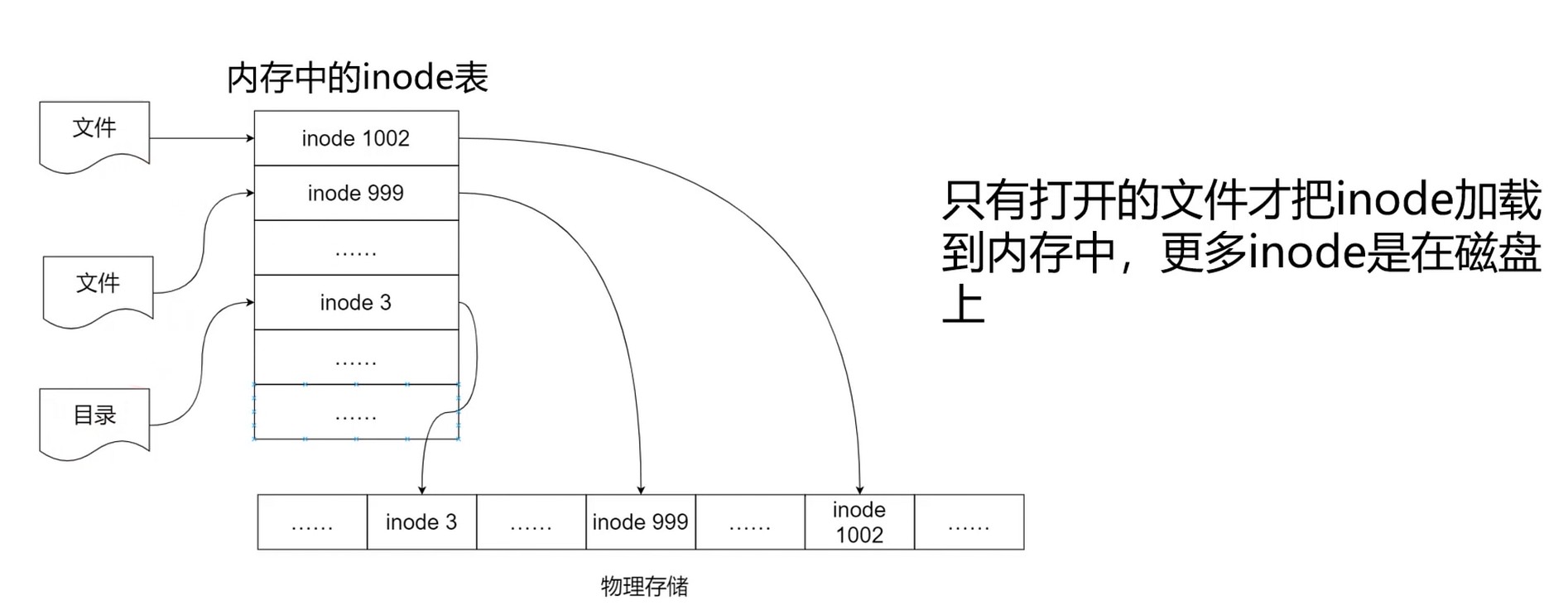
要注意的是目录也是文件, 会有自己的inode.
如果文件的大小大于索引节点的大小, 会进行分级, 会是一个树状结构, 而树的查询效率和树的高度相关.
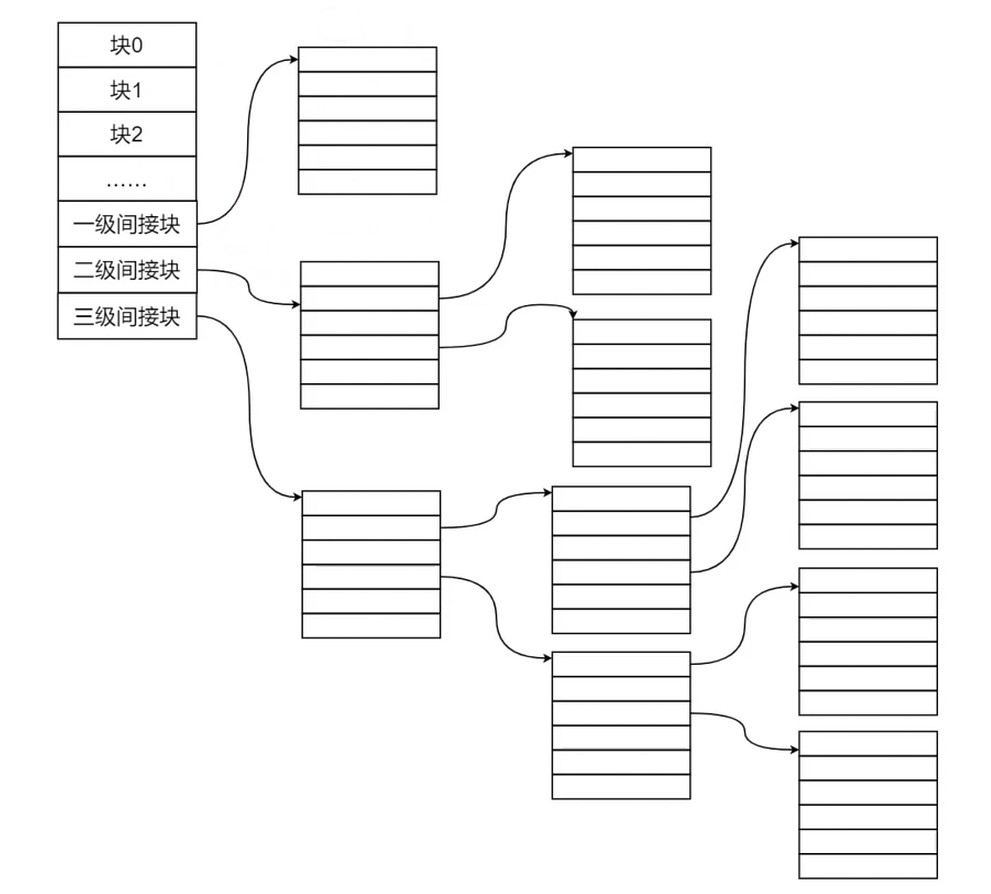
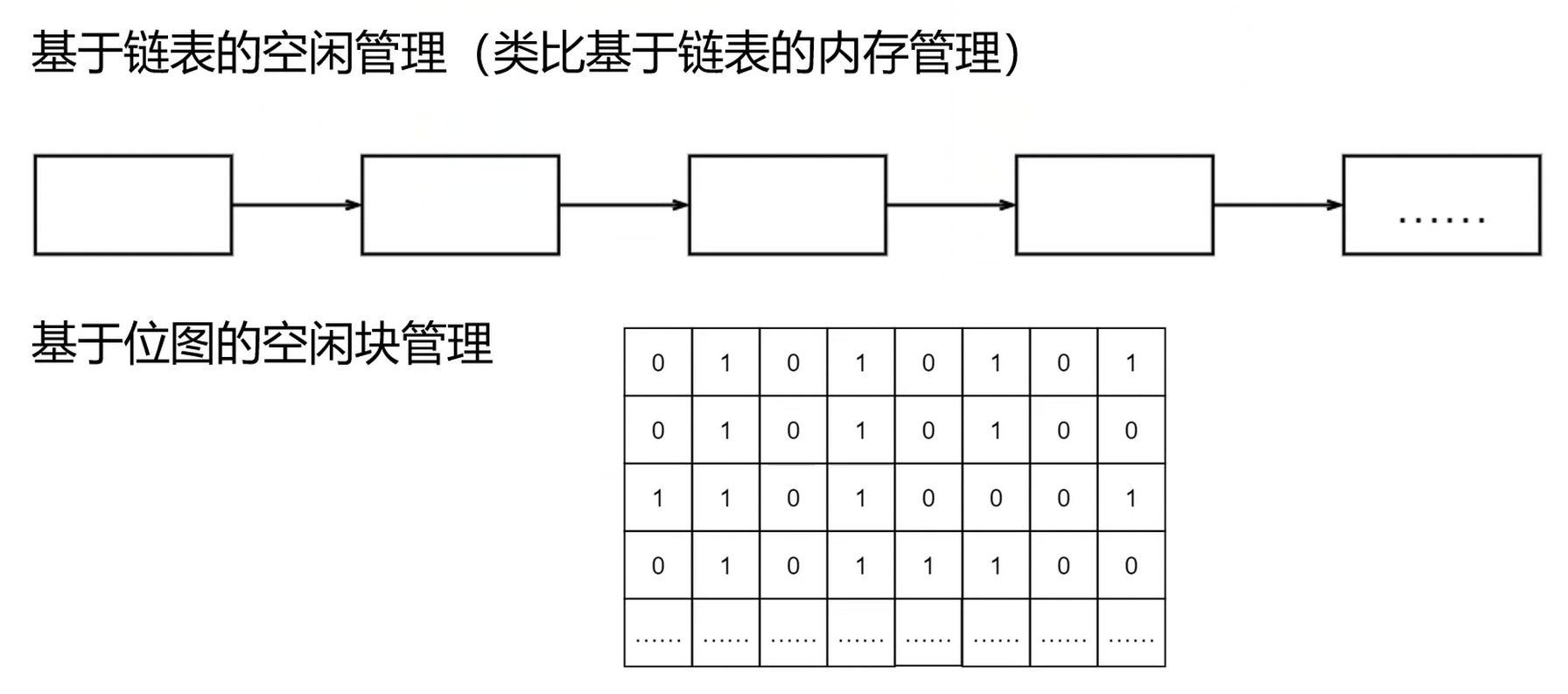
存储空间管理
空闲表, 空闲链表, 位示图
空闲链表
- 把所有空闲盘区组成一个空闲链表
- 每个链表节点存储空闲盘块和空闲的数目
位示图
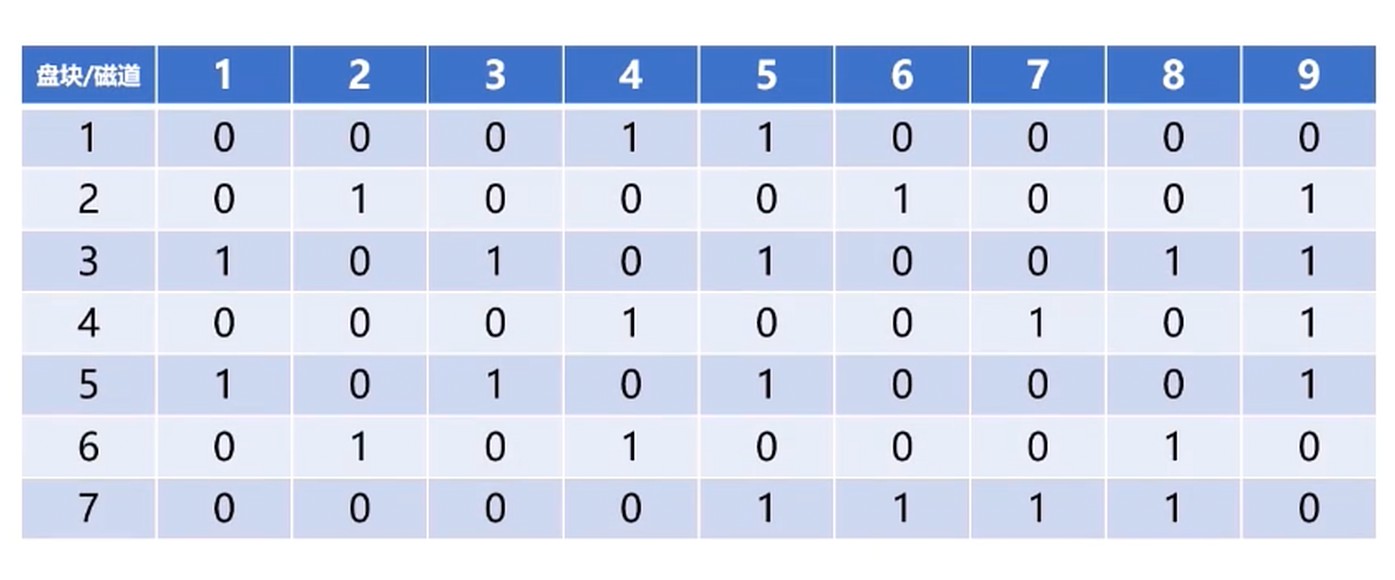
0表示未使用; 1表示已经使用了
- 位示图维护成本很低
- 可以非常容易找到空闲盘块
- 使用0/1比特位, 占用空间小
目录管理
目录用来管理文件的集合, 形成树状结构–目录树
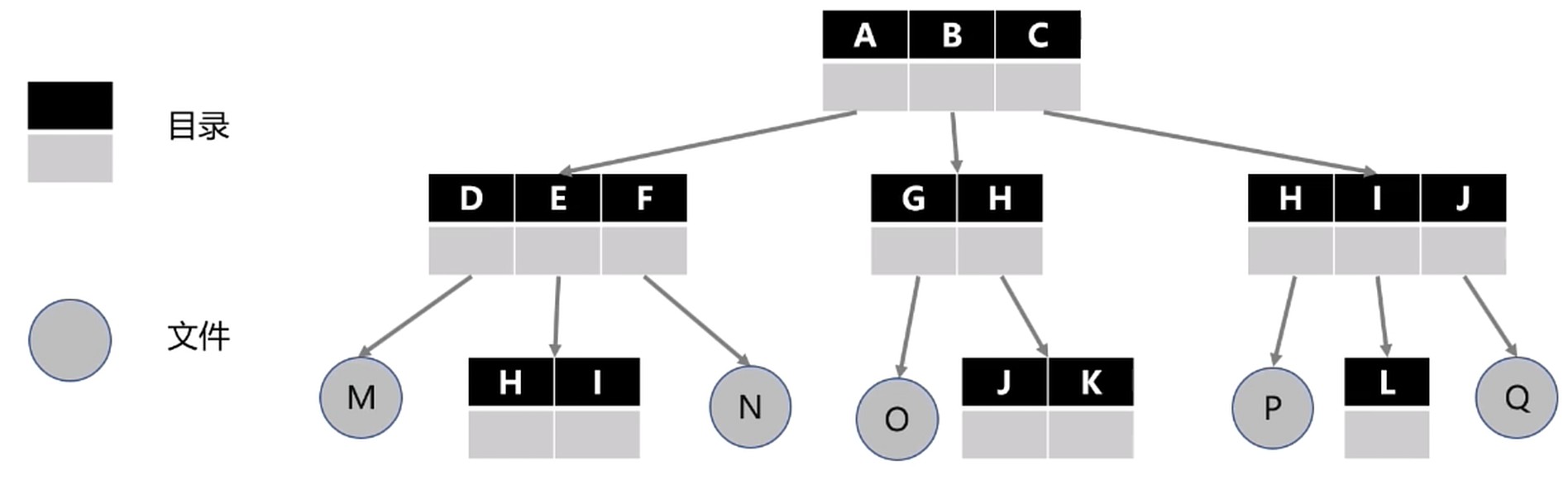
任何文件和目录都只有一个路径. 下图是目录的结构:
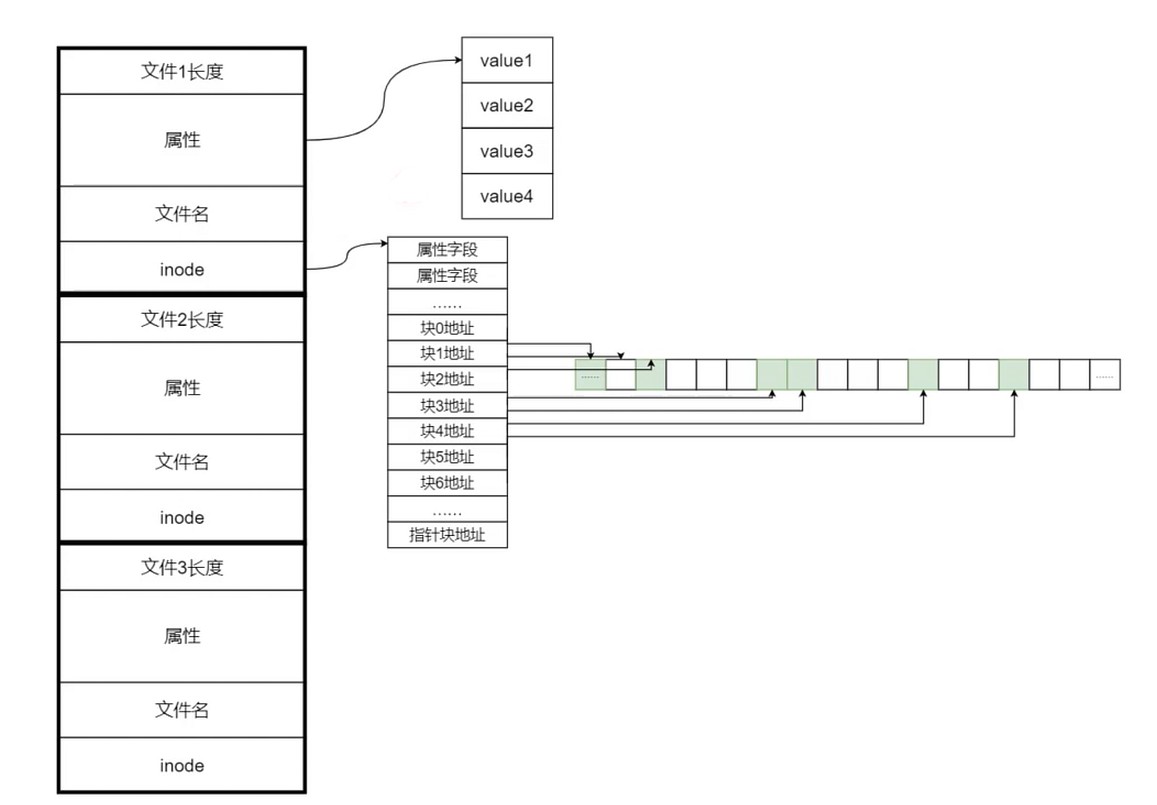
从图可以知道, 文件除了在自身的属性, 在目录中也有会一些对应的属性.
寻址文件. 先读取目录的内容, 根据目录的内容描述再一步步找到对应的文件.
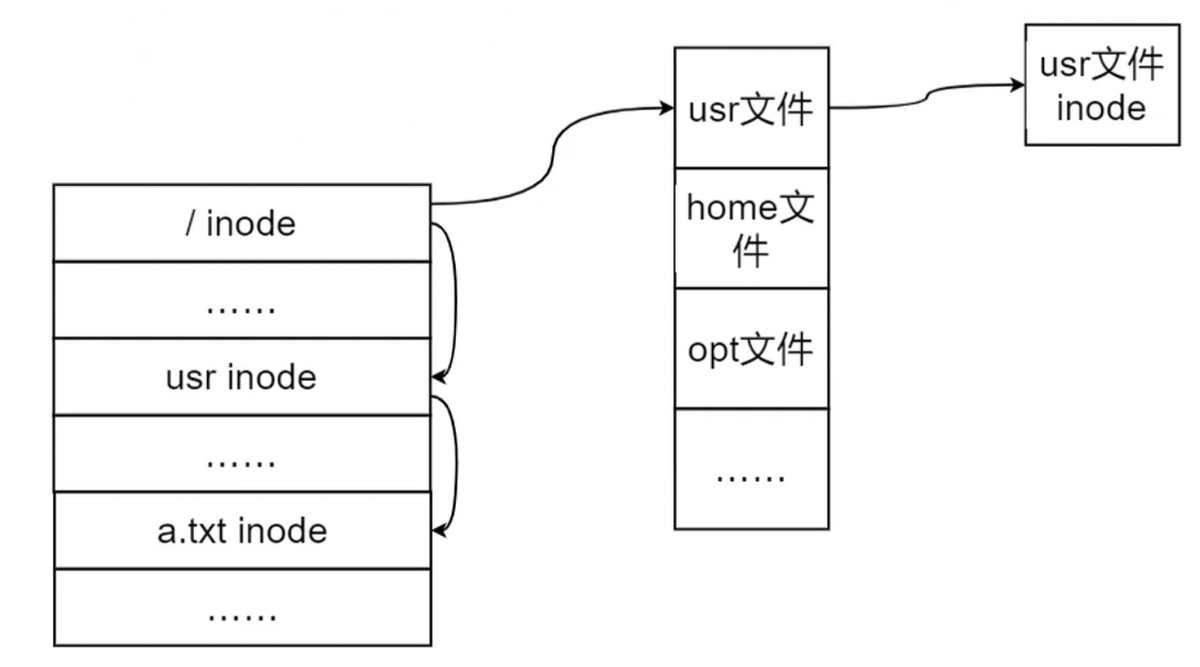
实际效率不够高. 如果一个目录下的文件很多, 这样的话, 链表就会很长, 查询的时候效率就会出现问题.
利用 哈希表 加速目录–文件查询
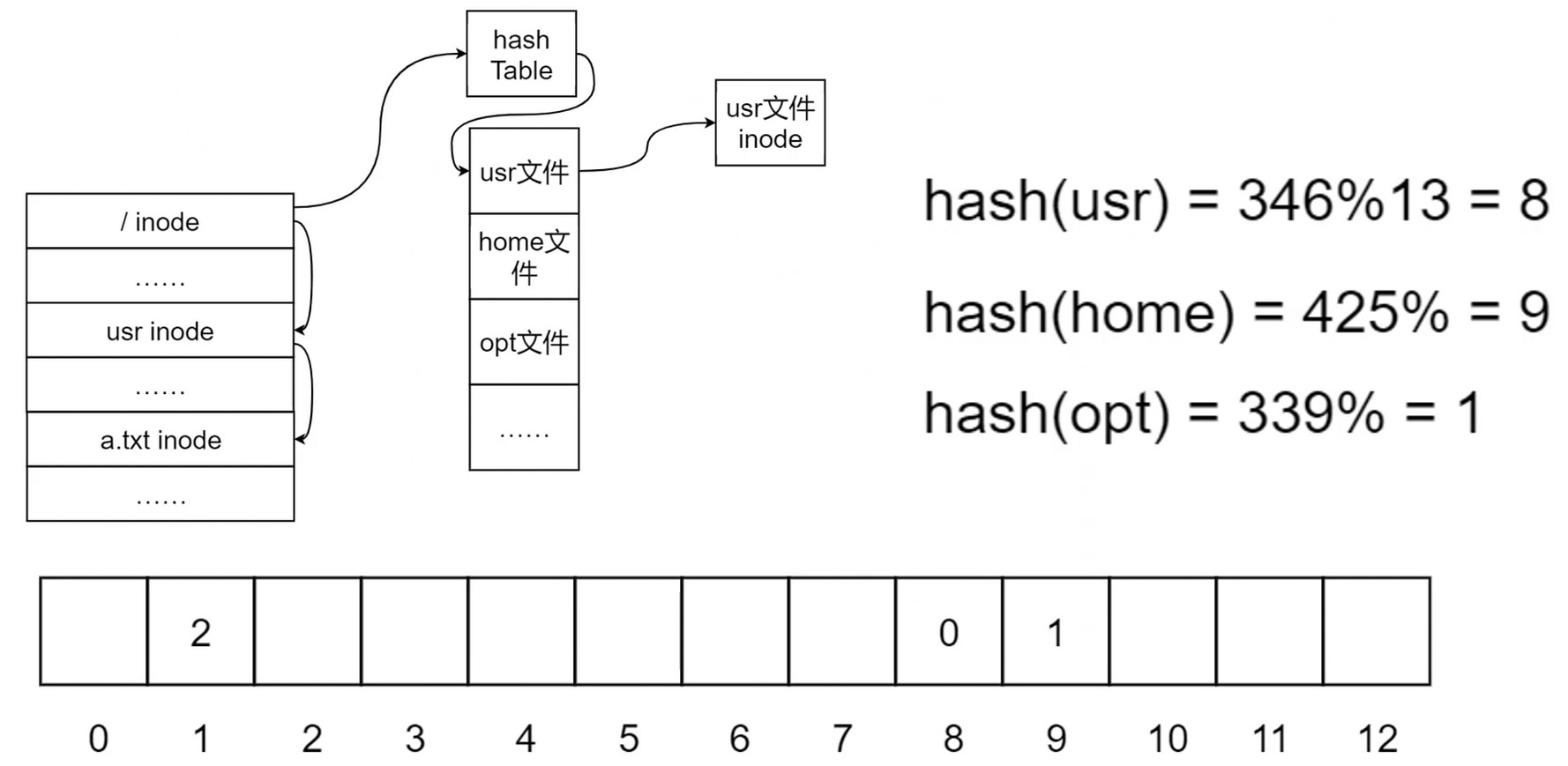
共享文件
文件共享 – 链接
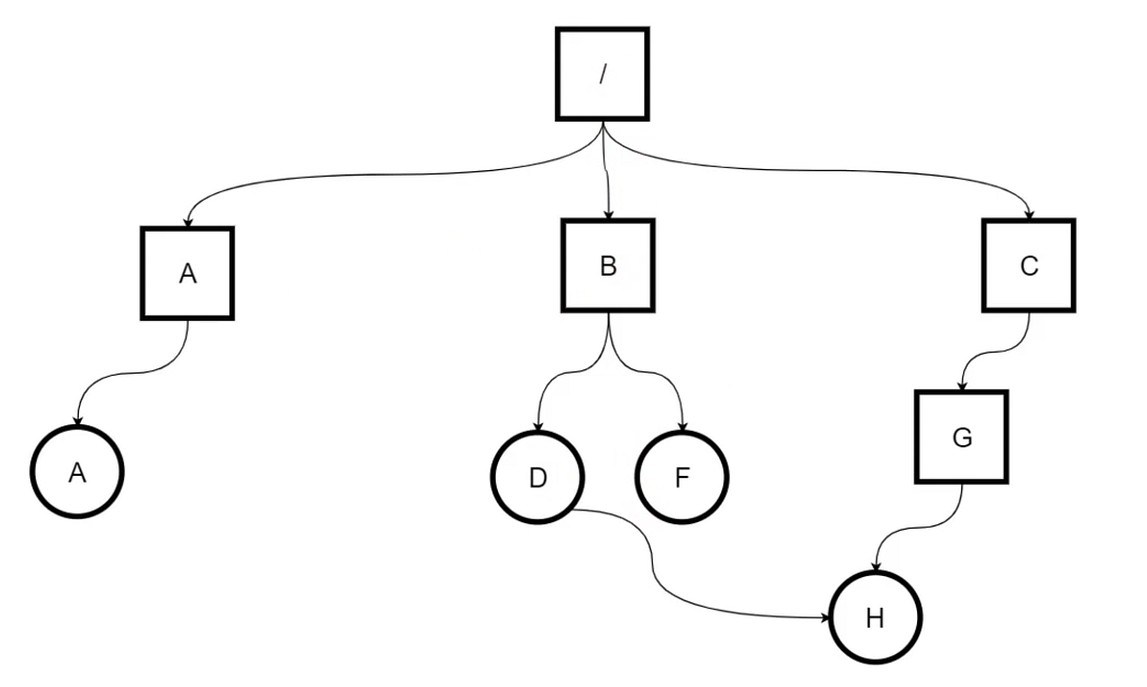
硬链接/符号链接
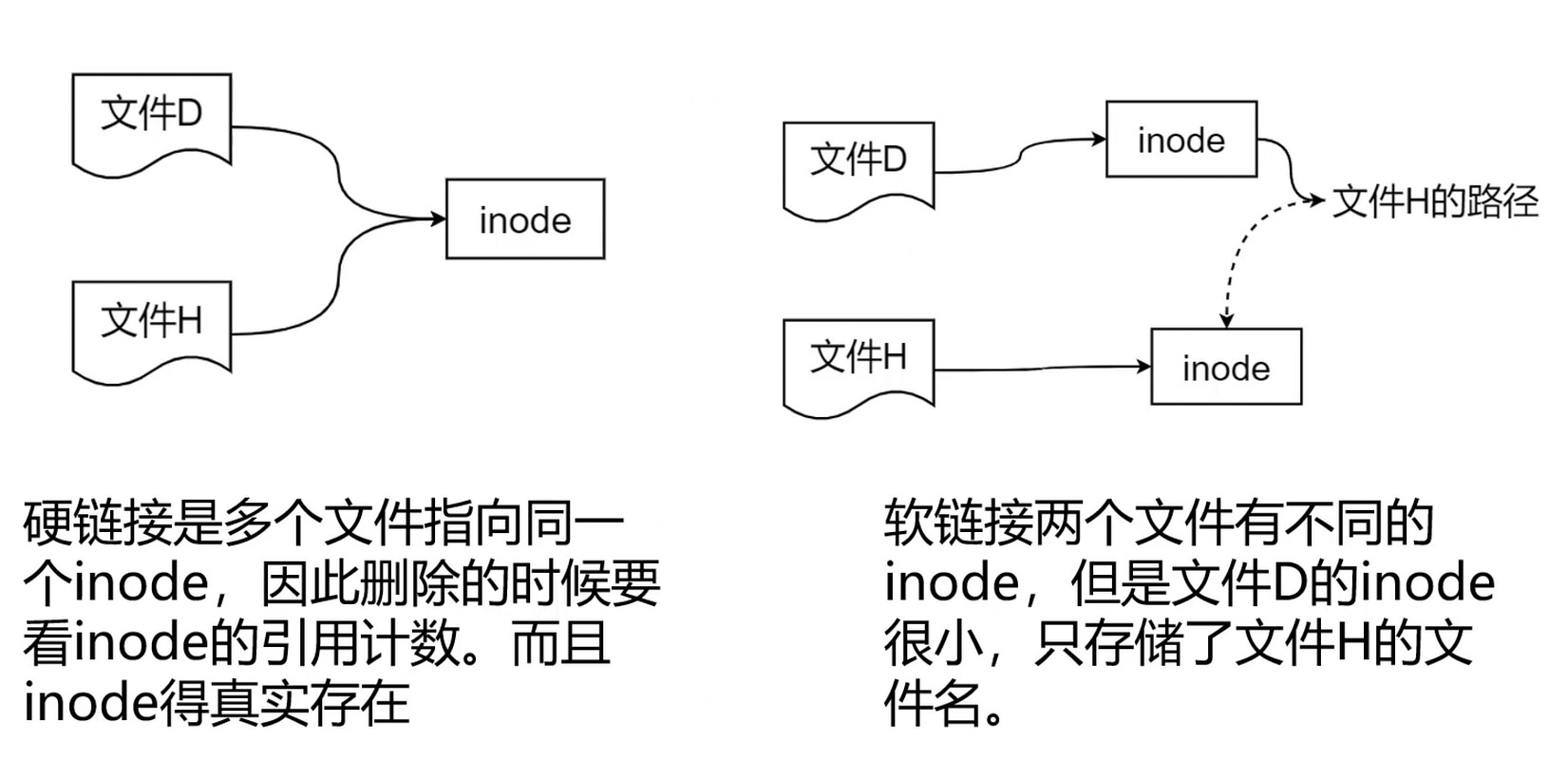
软链接速度没有硬链接快, 因为两次寻址, 但是软链接是解耦的.
Linux文件系统
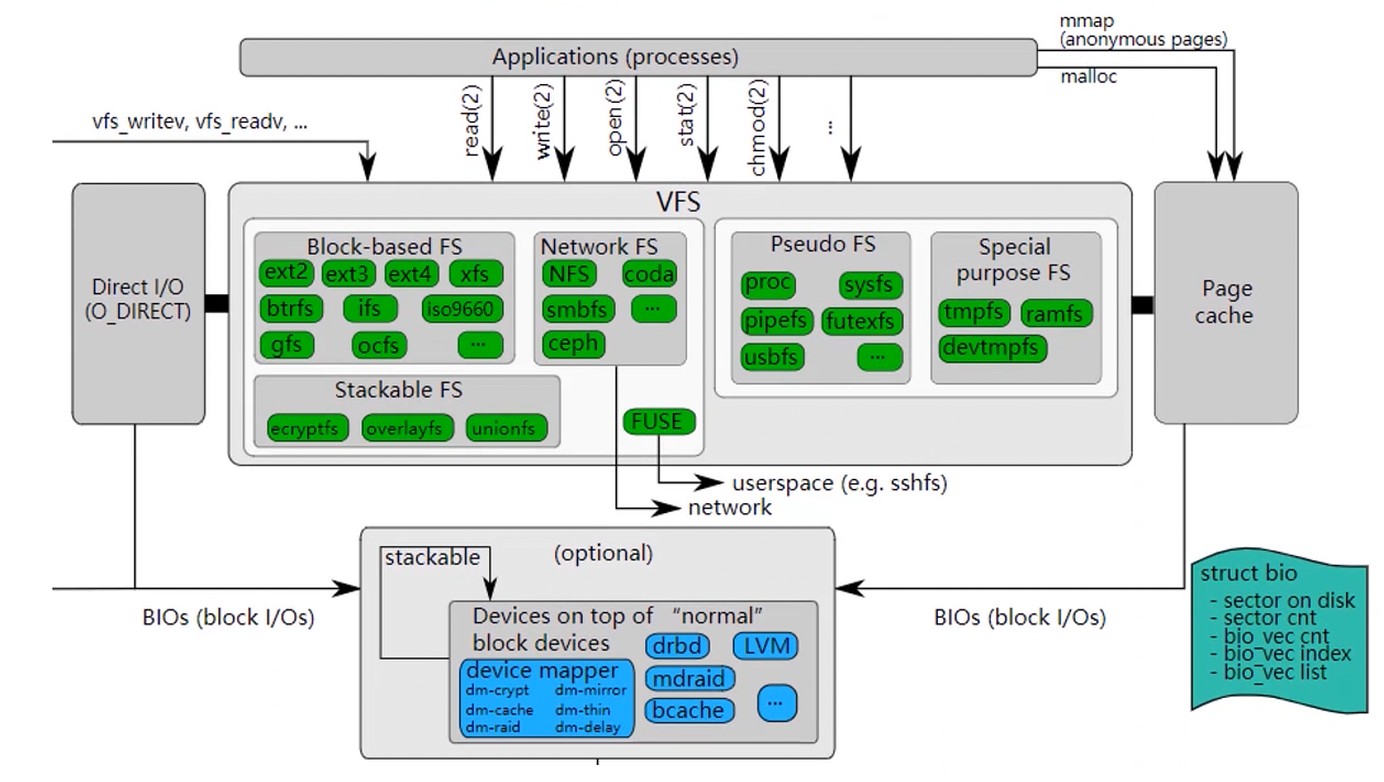
Linux的VFS, 虚拟文件系统, 可以挂载各种各样的文件系统.
FAT: File Allocation Table, 微软Dos/Windows使用的文件系统
NTFS: New Technology File System, WindowsNT环境文件系统
EXT2/3/4: Extended file system, 扩展文件系统, Linux的文件系统
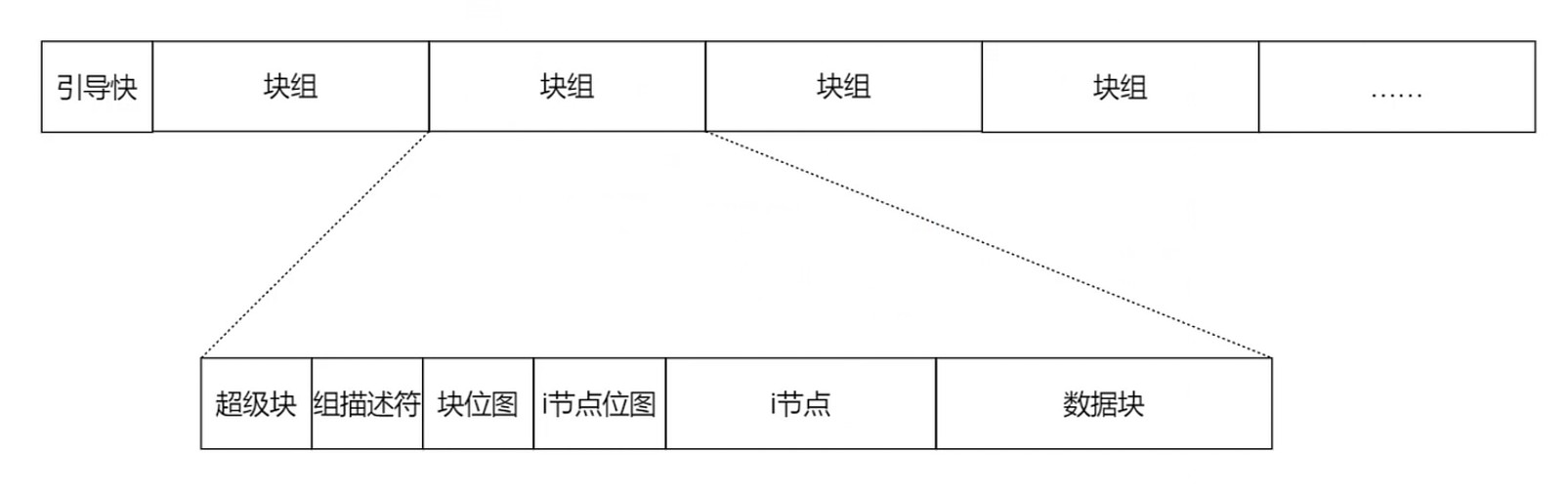
EXT文件系统


- 文件名不是存放在 Inode 节点上的, 而是存放在目录的 Inode 几点的
- 列出目录文件的时候, 无需加载文件的Inode
Inode bitmap : Inode 的位示图; 记录已分配的 Inode 和为分配的 Inode
Data block : 存放文件内容的地方; 每一个block都有唯一的编号; 文件的 block 记录再文件的 Inode 上.
Block bitmap: 和 Inode bitmap 类似; 记录 Data block 的使用情况.
Superblock: 记录整个文件系统相关信息的地方; block和inode的使用情况; 时间信息, 控制信息等.
# 查看文件系统
df -T
# 查看 Inode 信息
dump2fs /dev/sdb > dump2fs.log
# 查看文件的具体信息. 修改名字再查看信息. 会发现 Inode 值是不变的, 也就是说 名字 不是文件的唯一标识.
stat dump2fs.log
Linux目录
- bin 可执行二进制文件
- etc 配置文件
- home 用户的主目录
- usr 系统应用目录. local 管理员安装的文件目录
- opt 额外安装的可选应用程序所放置的位置
- proc 虚拟文件系统目录, 是系统内存的映射. 里面数字就是进程. 一切皆文件的思想
- root 超级管理员的主目录
- sbin 存放二进制可执行文件, 只有root才能访问
- dev 设备目录
- mnt 系统管理员安装临时文件系统的安装点, 系统提供这个目录让用户临时挂载其他的文件系统
- boot 系统引导时需要的文件
- lib 系统运行时的库
- var 用于存放运行时需要改变数据的文件
Linux 文件类型
- 套接字(s)
- 普通文件(-)
- 目录文件(d)
- 符号链接(l)
- 设备文件(b, c)
- FIFO(p)
VFS和基于日志的文件系统
虚拟文件系统(Virtual File System)
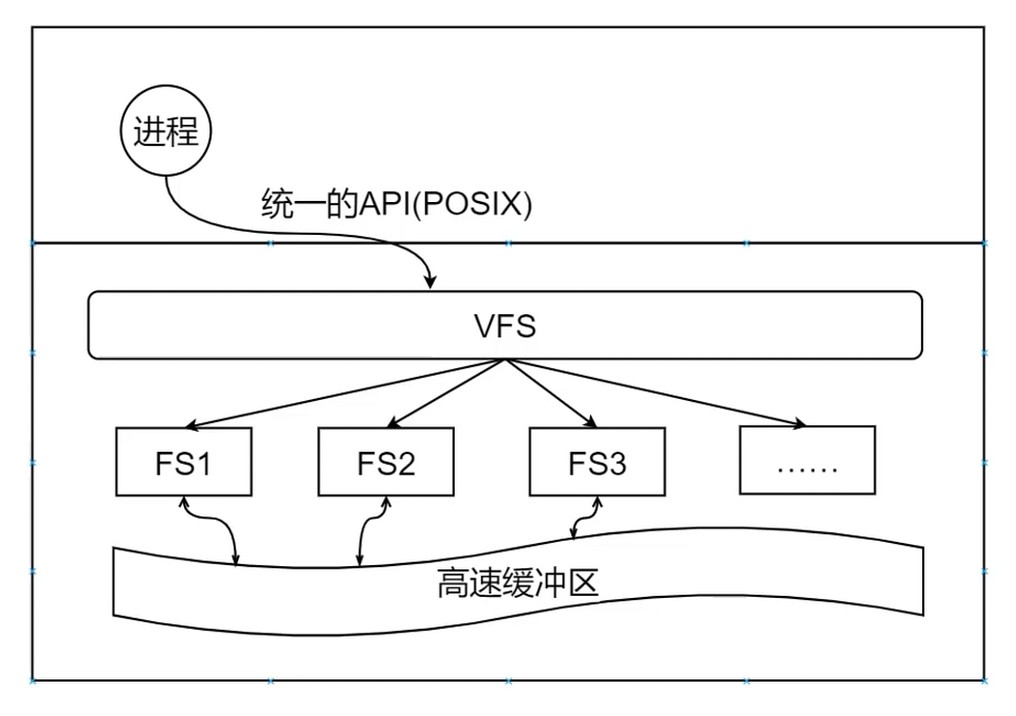
和进程对接的是 POSIX 的 API
任何架构的设计都离不开缓存的设计.
高速缓存区: 类似CPU的缓存, 内存管理的快表. 频繁使用的文件会被缓存.
由操作系统提供是因为操作系统能全局地看待问题.
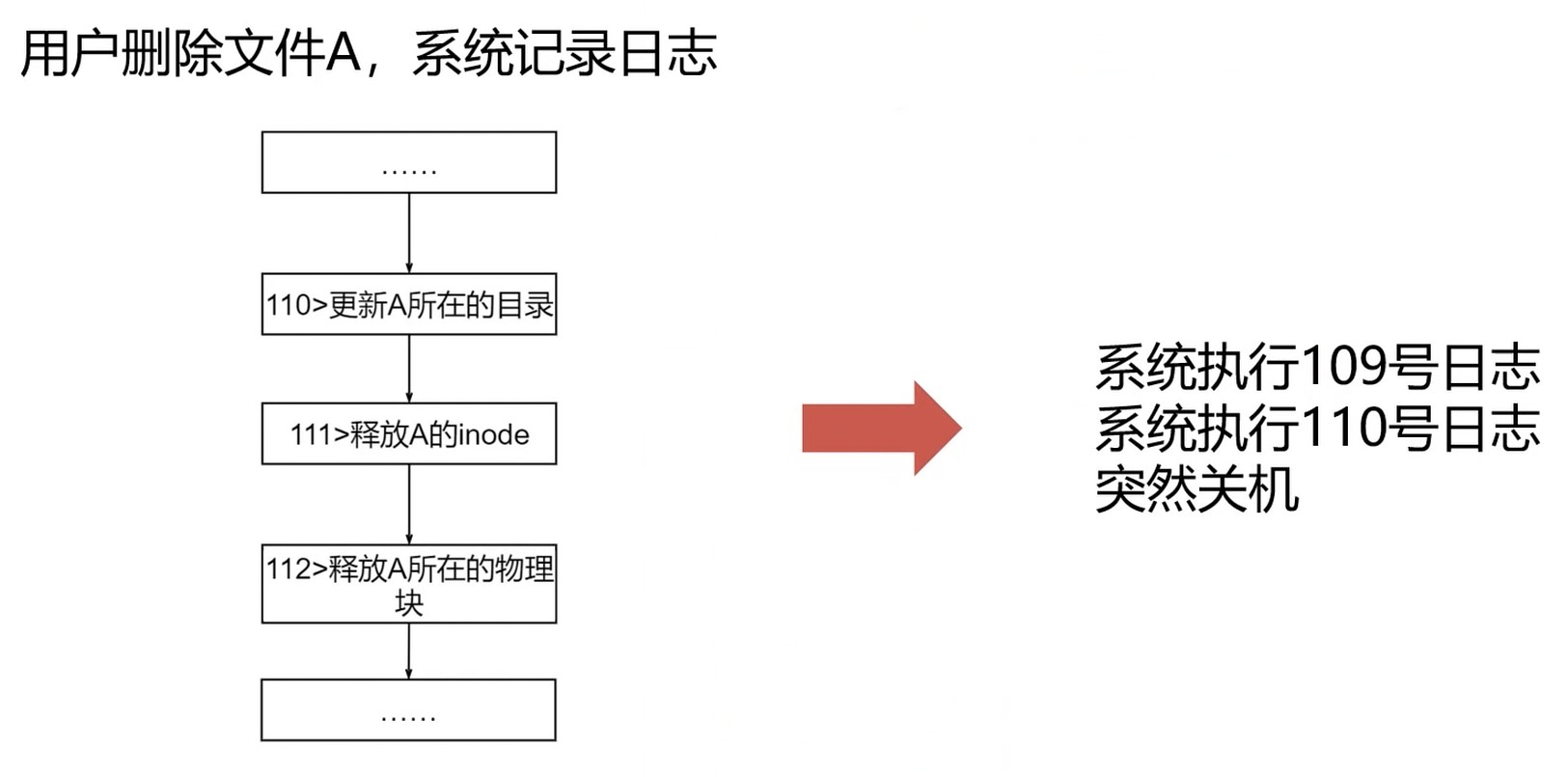
删除文件操作
- 更新A所在的目录
- 释放A的inode
- 释放A占用的物理块(将物理块加入空闲列表/位图)
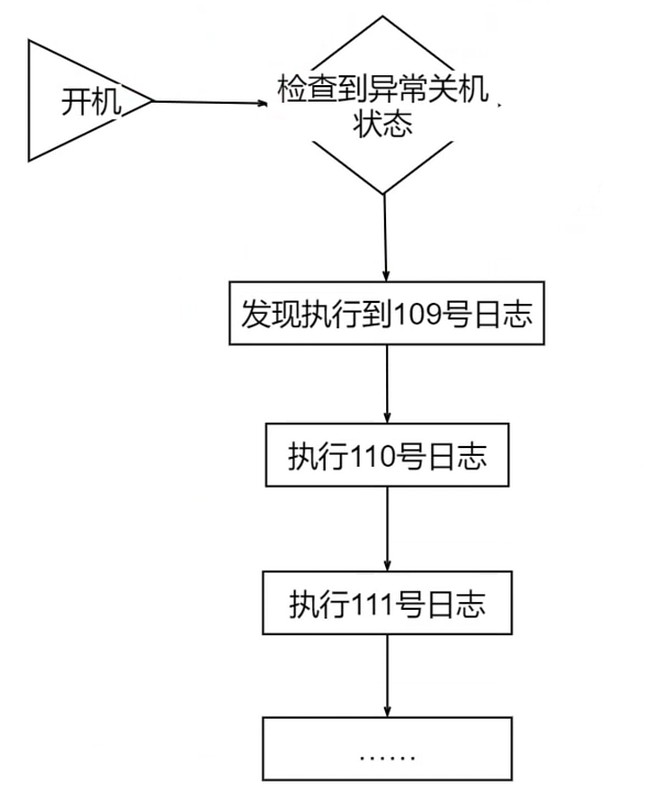
基于日志的文件管理
故障恢复

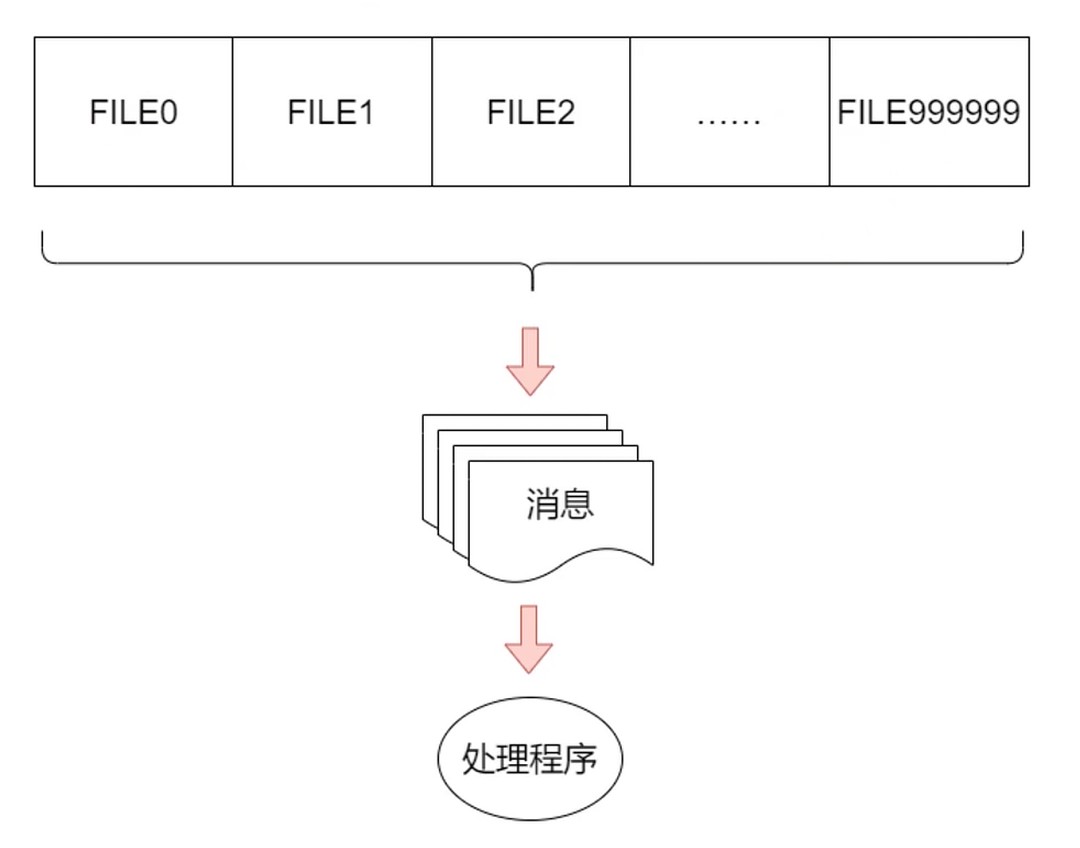
高并发下socket如何处理
select/poll/epoll
- 场景: 有100w个socket连接需要处理
- linux下socket连接抽象成文件(100w个文件句柄)
- 系统其实就是不断检查100w个文件中有没有数据到来
- 100w个socket并发很高要, 稍有不慎, 就造成系统雪崩
使用阻塞IO? 所谓阻塞是进程的阻塞. 肯定不行, 有巨大的调度成本, 包括切换和等待成本.
多路复用(Multiplexing): 多个信号复用一条链路.
把100w个socket分成1000组, 每组由一个线程负责.
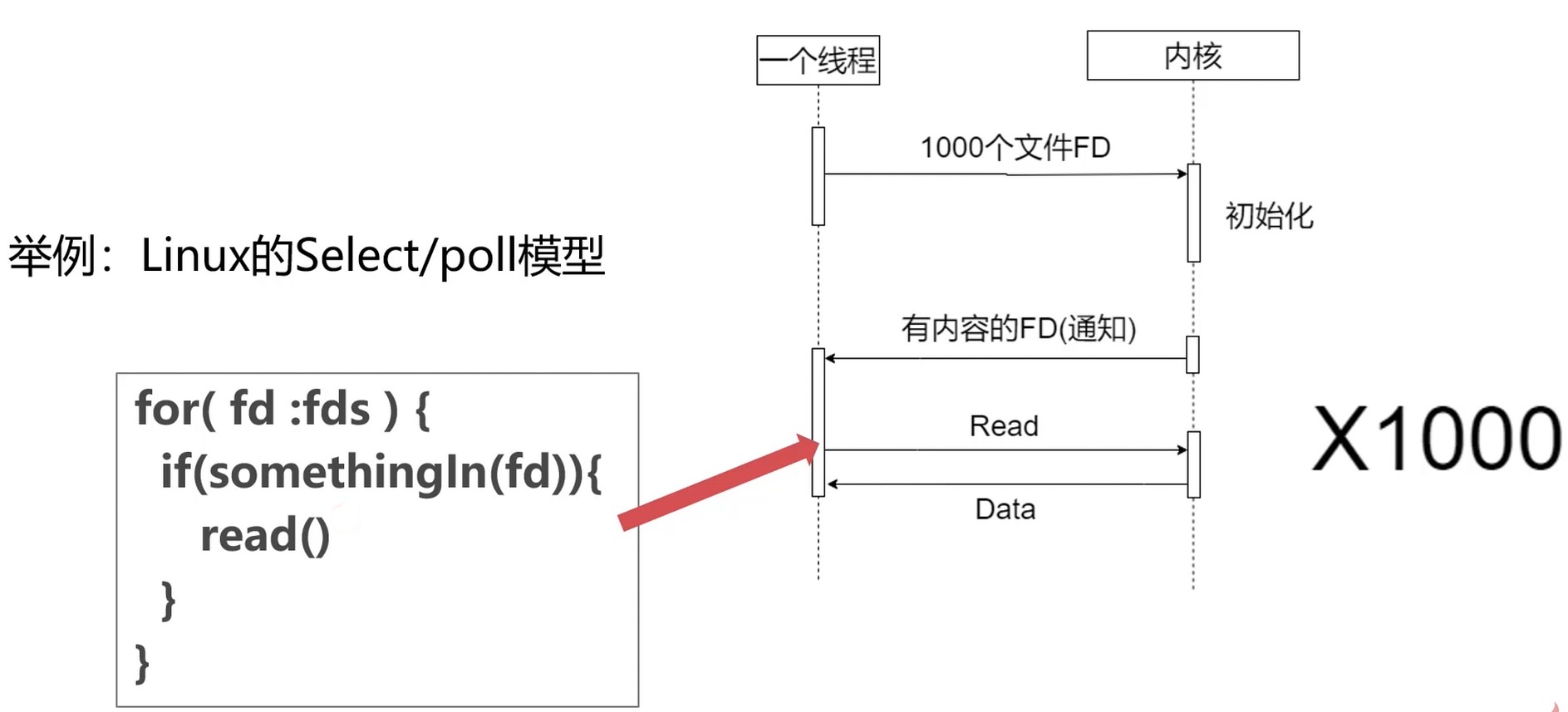
select/poll 是异步模型, 内核有数据才通知线程.
select/poll 是阻塞模型, 发生后线程会进入阻塞状态.
句柄的遍历受数据结构的影响. select 用数组, poll使用链表.
本质问题: 在遍历过程中, 不断拷贝句柄到内核, 然后内核不断返回数据, 线程又要遍历返回的数据.
解决拷贝FD问题
增量传递, 一次传所有句柄, 之后可以增删.
允许增加操作系统内核的FD, 那么应该使用怎样的数据结构保证高效? insert, find, delete都在O(1)
- 数组: insert
O(1), findO(n), delete~O(n) - 链表: insert
O(1), findO(n), delete~O(1) - 哈希表: 效果不好, 适合全集很大, 抽样很少的场景
- 平衡树(二叉搜索树–红黑树): insert
O(logn), findO(logn), delete~O(logn)
通过以上思路, 就出现了 epoll
- 增量向内核传输FD(同理增加删除FD)
- 内核返回事件(不是FD)
- 事件中带有可以被读取的FD(避免线程遍历)
设备管理
广义的IO设备
对CPU而言, 凡是对CPU进行数据输入的都是输入设备.
对CPU而言, 凡是CPU进行数据输出的都是输出设备.
按照信息交换单位分类(ls指令列举出来的设备文件类型就是按照这个分类的)
- 块设备(Block): 磁盘, SD卡
- 字符设备(Char): shell, 打印机
IO设备的缓冲区(CPU与IO设备的速率不匹配)
- 减少CPU处理IO请求的频率
- 提高CPU与IO设备之间的并行性
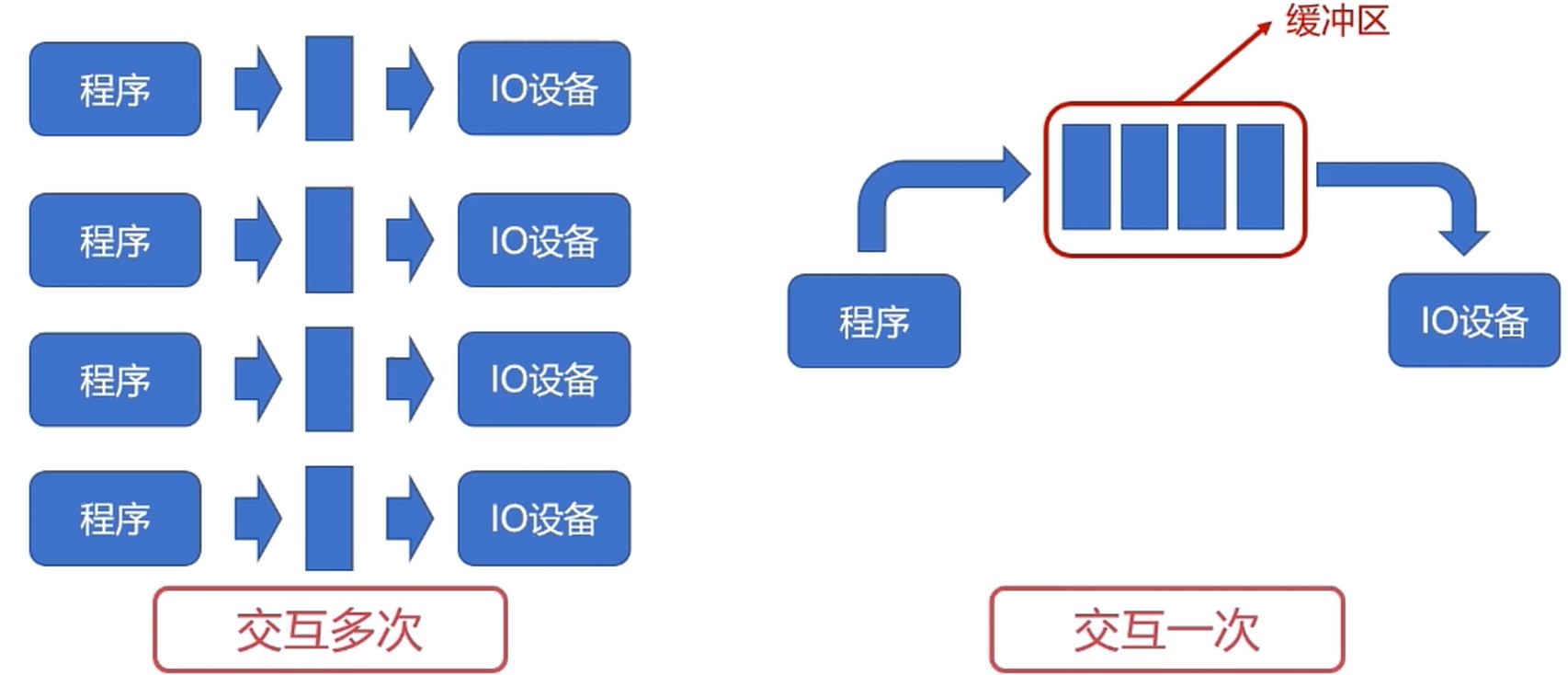
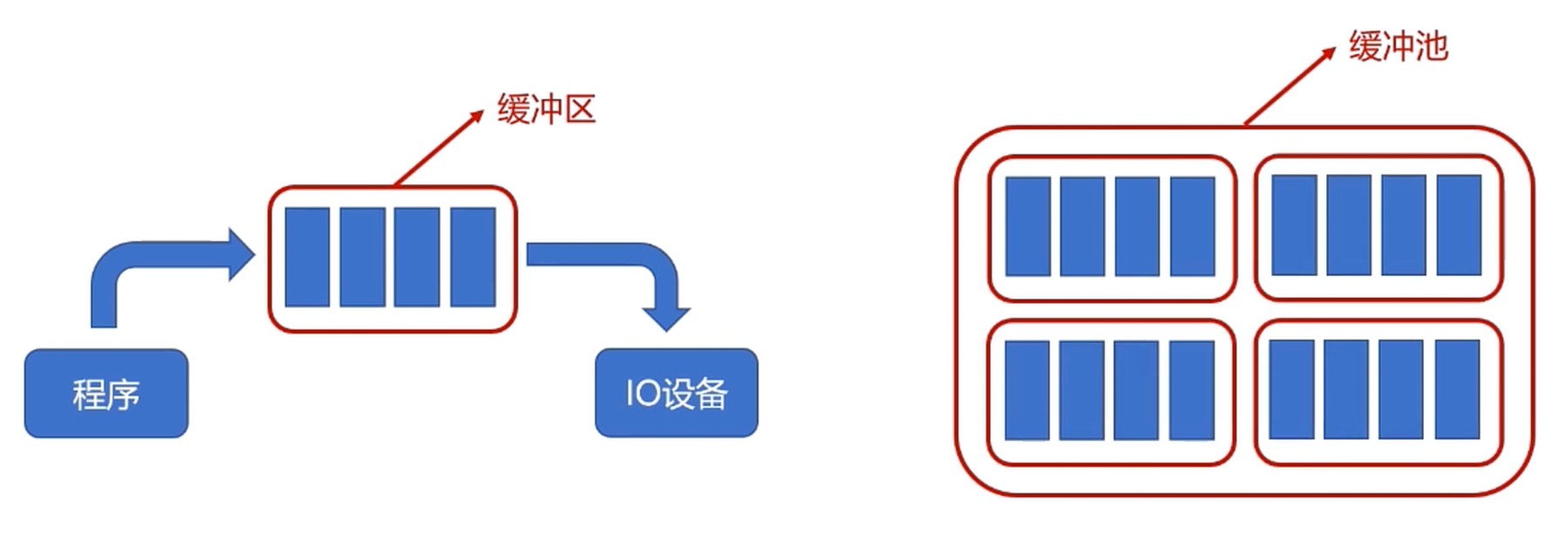
- 专用缓冲区只适用于特定的IO进程
- 如果这样的IO进程较多时, 对内存的消耗也很大
- 操作系统划出了可供多个进程使用的公共缓冲区, 称之为缓冲池.
缓冲池化, 缓冲区不是进程专属, 由缓冲池来管理.
SPOOLing 技术
- 是关于慢速字符设备如何与计算机主机交换信息的一种技术.
- 利用高速共享设备将低速的独享设备模拟为高速的共享设备.
- 逻辑上, 系统为每个用户都分配了一台独立的高速共享设备.
所以该技术属于虚拟设备技术.
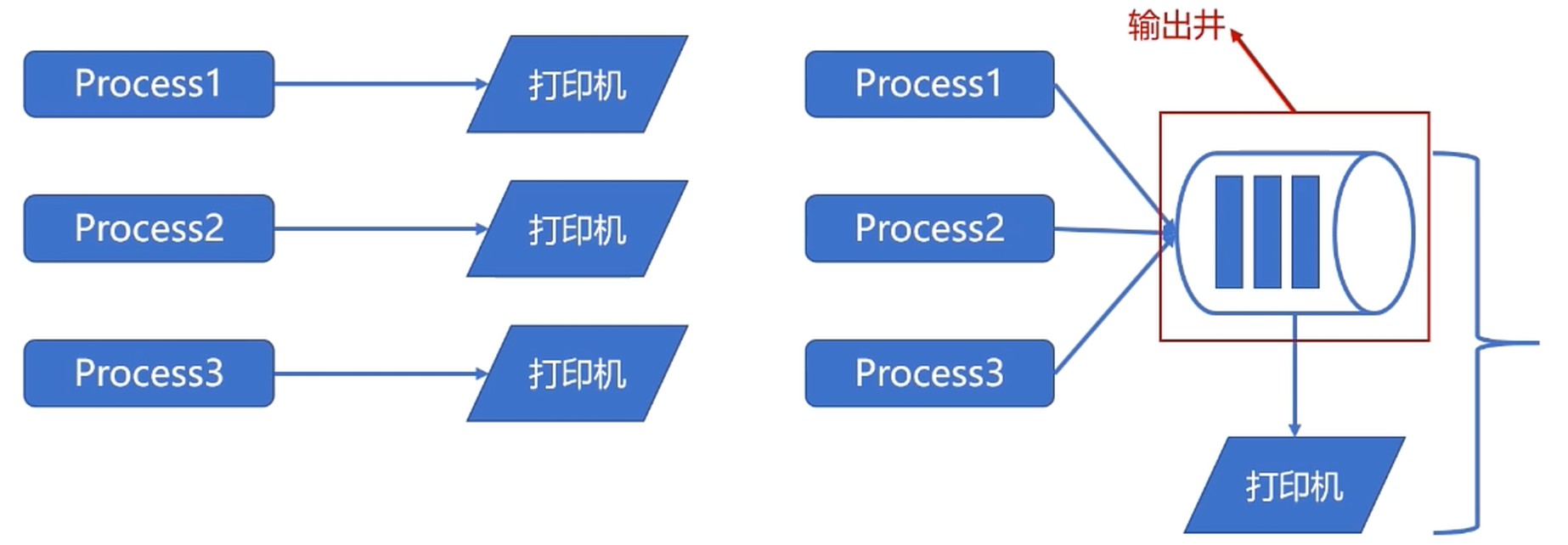
总结: SPOOLing技术把同步调用低速设备改为异步调用.
- 在输入, 输出之间增加了排队转储环节(输入井, 输出井)
- SPOOLing负责输入(出)井与低速设备之间的调度
- 逻辑上, 进程是直接与高度设备进行交互的, 减少了进程的等待时间.
线程同步
竞争条件和临界区
临界区: 访问共享资源的程序片段, 而这些资源又不能同时被多个线程访问.
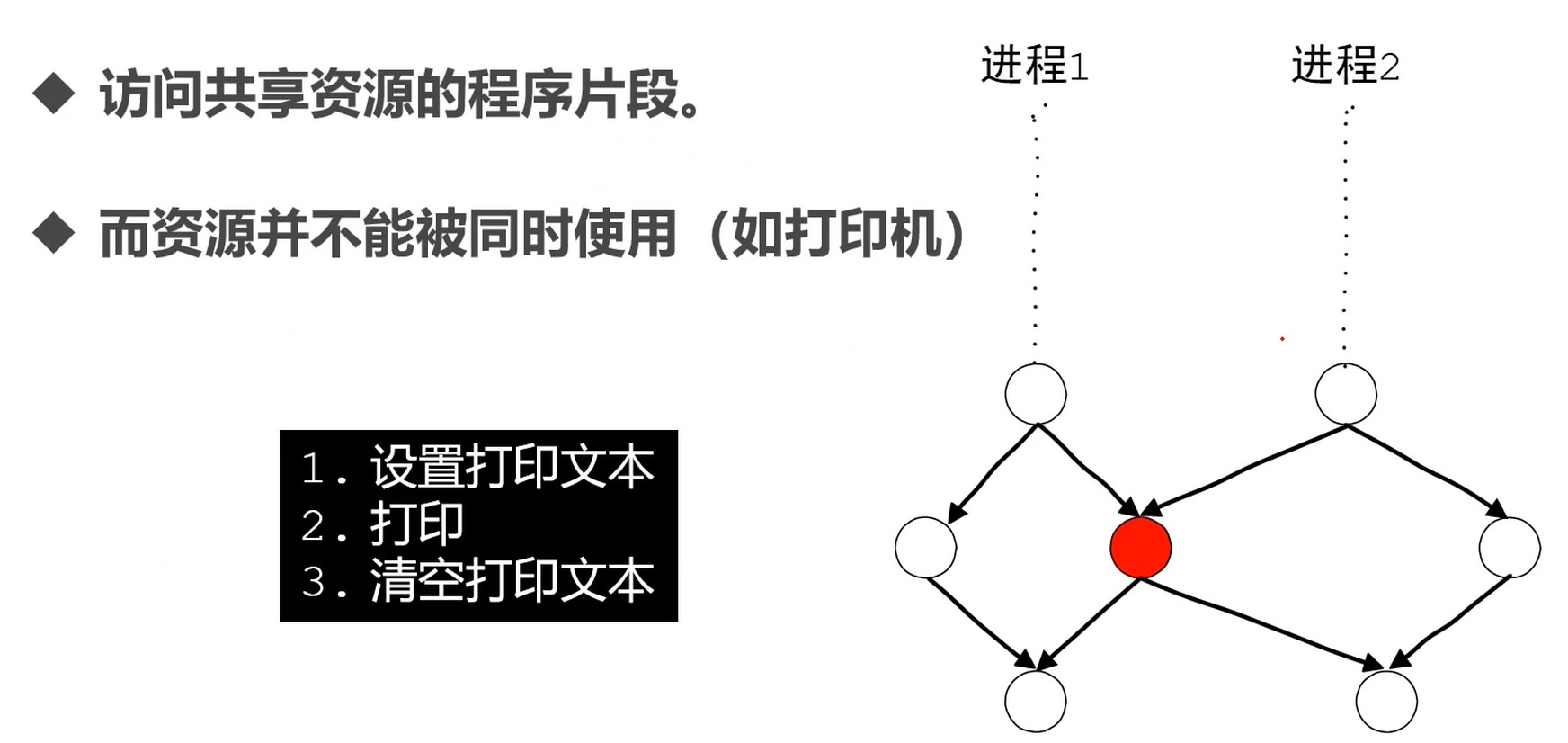
竞争条件

解决方案: 互斥, 例如: 给临界区上锁.
- 最简单的解决方案就是让临界区互斥(mutual exclusion), 就是同时不会有两段程序在临界区. 严格来说, 应该满足四个条件
- 任何两个进程不同时在临界区
- 不对CPU数量和速度做任何假设
- 临界区外运行的进程不得阻塞其他进程
- 不得使进程过长等待临界区
互斥–屏蔽中断
进程的切换依赖中断, 所以屏蔽中断可以阻止进程切换. 将屏蔽中断的能力下放给用户进行临界区管理.

这样做会有问题, 屏蔽的是一个核的, 中断是跟着CPU核走的, 多核还是会有问题; 如果临界区出现异常了, 没办法处理.
锁的硬件基础
TSL 和 XCHG
基于硬件指令一般是基于冲突检测的乐观并发策略: 先进行操作, 如果没有其他线程争用共享数据, 操作就成功了, 如果产生了冲突, 就进行补偿, 不断重试.
乐观并发策略需要硬件指令集的发展才能进行, 需要硬件指令实现: 操作+冲突检测的原子性.
TSL : Test and Set Lock, 测试并设置锁.
TSL RX, LOCK
作用是将一个内存字lock读到寄存器RX, 然后将lock设置为一个非0值.
执行原理:执行TSL指令的CPU会锁住内存总线, 禁止其他CPU在这个指令结束之前访问内存.
为了使用TSL指令, 需要使用一个共享变量lock来协调多内存的访问. lock=0时, 任何进程都可以使用TSL指令将其设置为非0值, 并读写共享内存; 而当操作结束时, 进程要使用move指令将lock的值重新设置为0.
enter_region:
TSL REGISTER,LOCK # 复制锁到寄存器并将锁设为1
CMP REGISTER,#0 # 锁是0吗?
JNE enter_region # 若不是0,说明锁已被设置,所以循环
RET # 返回调用者,进入临界区
leave_region:
MOVE LOCK,#0 # 在锁中存入 0
RET # 返回调用者
如果TSL原子操作没有成功, 则重新跳转到enter_region方法循环执行. 这个跟Peterson算法有点类似, 不过TSL可以支持任意多个线程的并发执行.
还有一个可以替换 TSL 的指令是 XCHG, 它原子性的交换了两个位置的内容, 例如: 一个寄存器与一个内存字.
enter_region:
MOVE REGISTER,#1 # 把 1 放在寄存器中
XCHG REGISTER,LOCK # 交换寄存器和锁变量的内容
CMP REGISTER,#0 # 锁是 0 吗?
JNE enter_region # 若不是 0 ,锁已被设置,进行循环
RET # 返回调用者,进入临界区
leave_region:
MOVE LOCK,#0 # 在锁中存入 0
RET # 返回调用者
XCHG 的本质上与 TSL 的解决办法一样. 所有的 Intel x86 CPU 在底层同步中使用 XCHG 指令.
解决竞争条件
严格轮换法

根据 turn 的值判断是否能够访问临界区. 进程1访问完就修改 turn 的值, 进程2才能进入临界区.
假设进程2的非临界区运算很慢, 会导致进程1卡住. 也就是说, 一个进程非临界区的执行会导致另一个进程临界区的执行.


如何让非临界区不影响其它进程临界区的执行?
- 每个线程进入临界区之前都标记自己对临界区资源感兴趣.
- 进程执行完临界区后, 不应该主动交出控制权, 而是观察其它进程对临界区是否感兴趣.
Peterson算法

turn == pid 的判断防止两个感兴趣的进程同时进入临界区. interested 数组判断其它进程是否对临界区感兴趣.
信号量
- 是一个控制同时访问一个资源的线程(进程)数量的抽象数据类型(不同语言对于信号量的实现可能会有差异).
- Semaphore 内部封装一个整数(p)和一个睡眠线程队列(s), 并提供两个原子操作.
- up()
- p=p+1
- 如果s.size()>0, 从s中选择一个唤醒并执行
- down()
- if(p==0){sleep(&semaphore)}
- p–
- up()
信号量解决有界缓冲区问题: 生产者/消费者


empty: 有多少个空位. 生产者每生产一个就减一. 等于0的时候说明满了. 消费者相反.
full: 消费了多少个. 生产者每生产完一个就加一. 消费者相反.
mutex: 可以同时进入的线程数, 保护临界区. down和up操作都是原子操作, 不会出现竞争问题.
不保护临界区, 会导致数据的统计取决于精确的执行时序了.
上面的程序, 只用mutex实现也可以, 但是需要加判断, 而我们是希望程序是可读的, 信号量可以给程序提供足够的抽象.
多信号量造成的死锁

解决: 调换顺序.
互斥量
- 问题: 两个线程的指令交叉执行
- 互斥量保证先后执行
- 初始值为1的semaphore, 是信号量的特殊情况
原子性: 一系列操作不可被中断的特性.
互斥量是线程同步最简单的方法.
互斥量也叫做互斥锁, 处于两态之一的变量: 解锁和加锁.
两个状态就保证了资源访问的串行.
操作系统直接提供了互斥量的API
demo文件: mutex_lock_demo.cpp
自旋锁
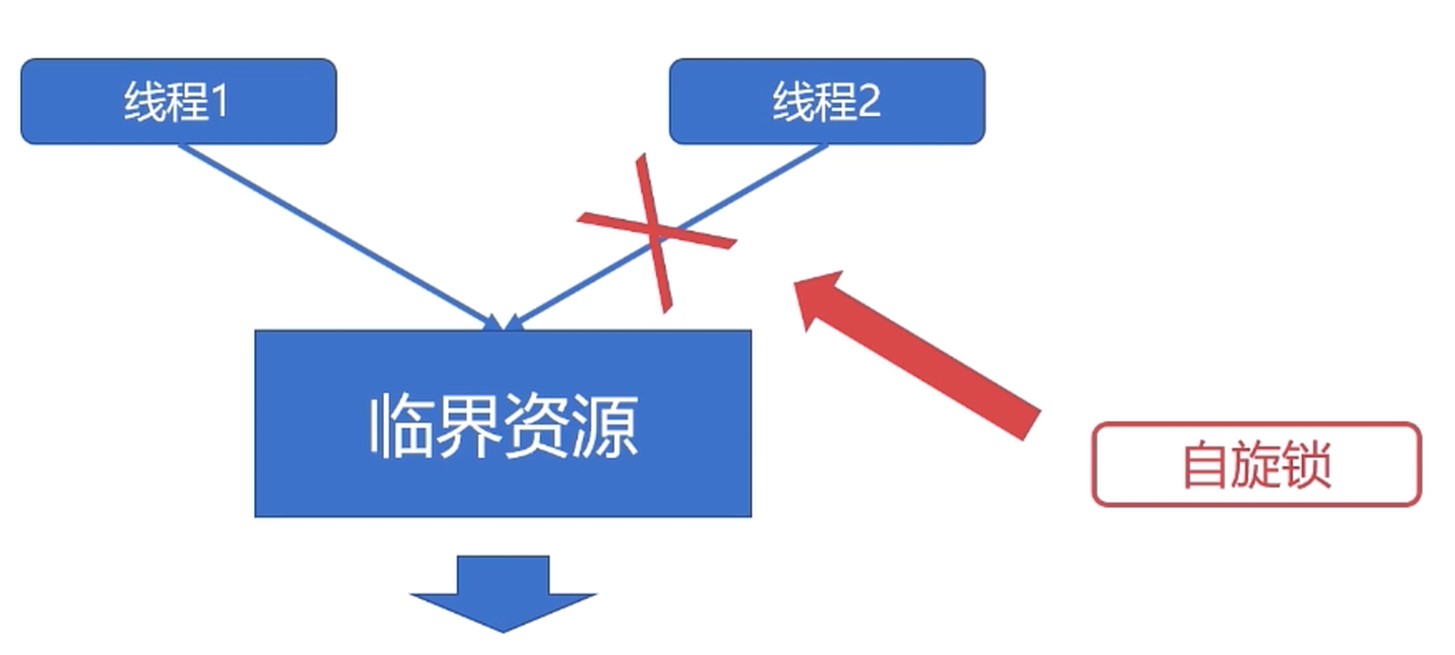
- 自旋锁也是一种多线程同步的变量
- 使用自旋锁的线程会反复检查锁变量是否可用
- 自旋锁不会让出 CPU, 是一种忙等待的状态
死循环等待锁被释放.
- 自旋锁避免了进程或线程上下文切换的开销.
- 操作系统内部很多地方使用的是自旋锁.
- 自旋锁不适合在 单核CPU 使用.
demo文件: spin_lock_demo.cpp
读写锁
从临界资源的角度思考. 是一种特殊的 自旋锁.
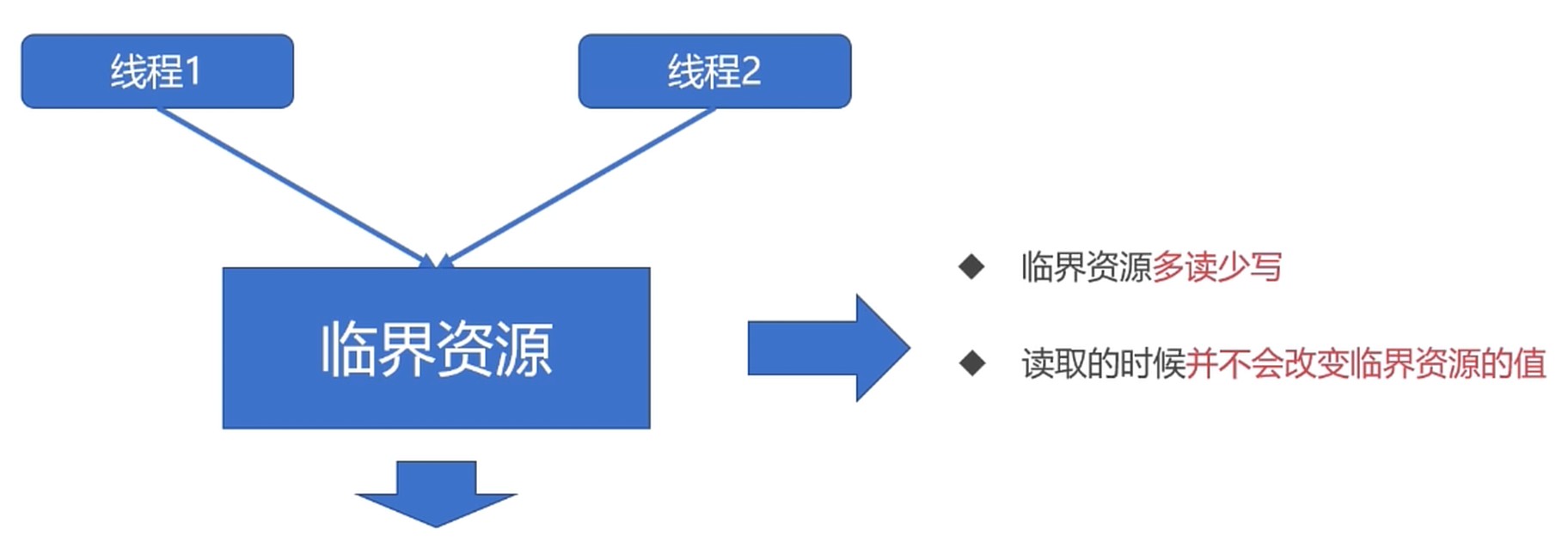
- 允许多个读者同时访问资源以提高读性能.
- 对于写操作是互斥的.
demo文件: rwlock_demo.cpp
条件变量
- 一种相对复杂的线程同步方法, 但是有更灵活的使用场景
- 条件变量允许线程睡眠, 直到满足某种条件
- 当满足条件时, 可以向该线程发送信号, 通知唤醒
生产者与消费者问题
- 缓冲区小于等于0时, 不允许消费者消费, 消费者必须等待
- 缓冲区满时, 不允许生产者往缓冲区生产, 生产者必须等待
- 生产者生产一个产品时, 唤醒可能等待的消费者
- 消费者消费一个产品时, 唤醒可能等待的生产者
需要配置互斥量来使用.
demo文件: condition_demo.cpp
线程总结
- TSL/XCHG是基础能力(否则就得用忙等待算法)
- Semaphore是一种基于TSL成立的算法和数据结构(解决方案)
- Mutex是Semaphore的一种特殊产出
- 算法数据结构无穷无尽, 例如: AQS(Abstract Queued Synchronization)
CAS : Compare and Swap. 比较是否有冲突, 有就先同步再更新, 有点像git. 被叫做乐观锁
- 读不需要同步
- 写需要同步
- 适合写操作少, 读操作较多的场景
- 注意: 临界区的操作依然需要加锁
AQS
- 一种Java的数据结构, 用于实现多数场景的并发同步模型
- 可以用来实现
Semaphore/Mutex等 - 可以用来实现更多的并发控制场景
- 可以用来实现
进程同步
fork系统调用创建进程
- fork 创建的进程初始状态与父进程一样
- 系统会为 fork 的进程分配新的资源
- fork 调用无参数
- fork 会返回两次, 分别返回子进程id和0(子进程id是父进程返回, 0是子进程返回)
demo文件: fork_demo.cpp
共享内存
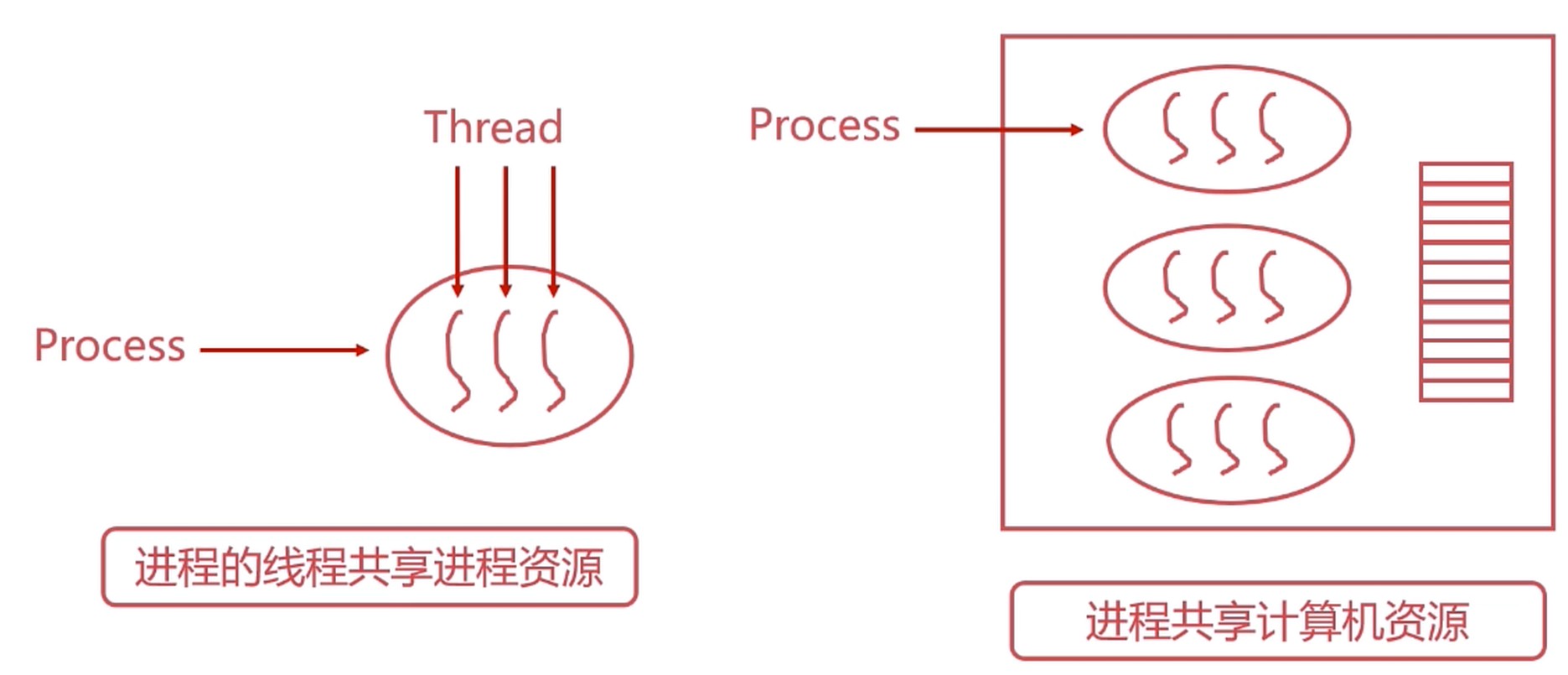
- 在某种程度上, 多进程是共同使用物理内存的.
- 但是由于操作系统的进程管理, 进程间的内存空间是独立的.
- 进程默认是不能访问进程之外的内存空间的.
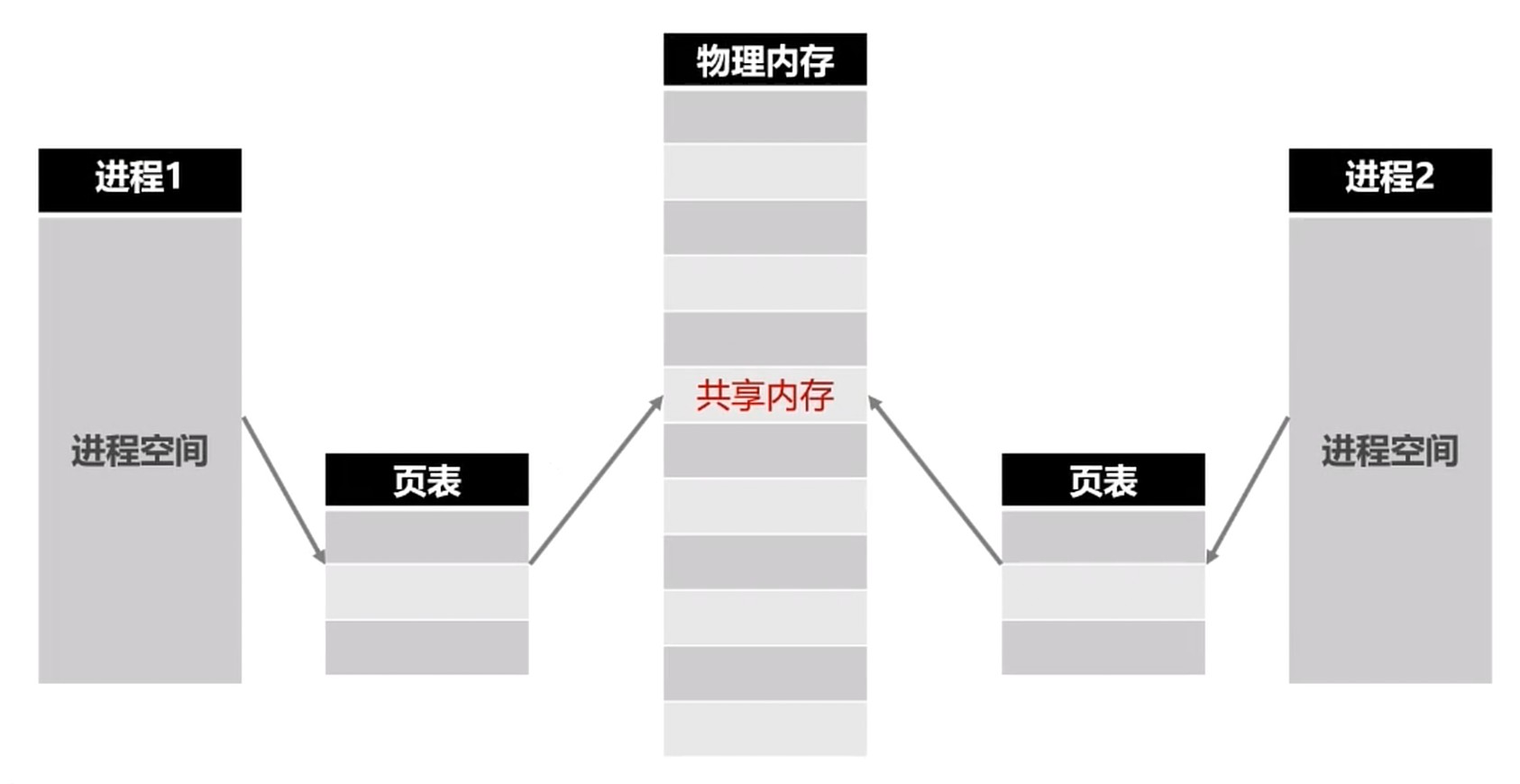
- 共享内存允许不相关的进程访问同一片物理内存.
- 共享内存是两个进程之间共享和传递数据的最快的方式.
- 共享内存未提供同步机制, 需要借助其他机制管理访问.
- 申请共享内存
- 连接到进程空间
- 使用共享内存
- 脱离进程空间&删除
demo文件: shm文件夹.
共享内存是高性能后台开发中最常用的进程同步方式.
Unix 域套接字
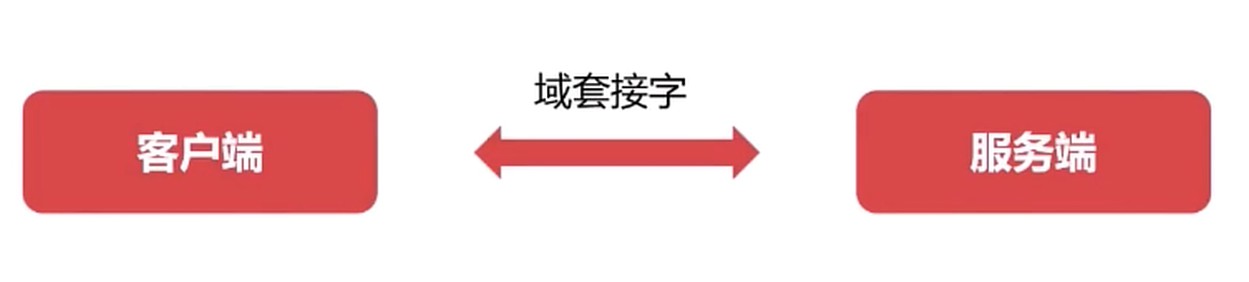
域套接字是一种高级的进程间通信的方法
Unix域套接字可以用于同一机器进程间通信
套接字(Socket)原是网络通信中使用的术语
Unix系统提供的域套接字提供了网络套接字类似的功能
Nginx, uWSGI 都使用了这个技术
服务端
- 创建套接字
- 绑定(bind)套接字
- 监听(listen)套接字
- 接收&处理信息
客户端
- 创建套接字
- 连接套接字
- 发送信息
demo文件: socket文件夹.
会在指定路径创建一个s(套接字)类型的文件.
- 提供了单机可靠的进程通信同步服务
- 只能在单机使用, 不能跨机器使用


博客内容遵循 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 协议
本文永久链接是:https://blog.lgq51233.xyz/2019/09/27/%E6%93%8D%E4%BD%9C%E7%B3%BB%E7%BB%9F/