
Kafka日志收集实战
日志收集设计
- 日志输出(日志组件输出log4j2)
- 日志收集(FileBeat)
- 日志过滤(logstash)
- 日志持久化(elasticsearch)
- 日志可视化(kibana)
- 分布式日志收集、链路跟踪、监控告警平台架构
Kafka 特点
Kafka是分布式发布-订阅消息系统. 它最初由LinkedIn公司开发,之后成为Apache项目的一部分. Kafka是一个分布式的,可划分的,冗余备份的持久性的日志服 用于处理活跃的流式数据.
Kafka是Linkedln开源的分布式消息系统.
Kafka主要特点是基于Pull模式来处理消息消费,追求高吞吐量,一开始的目的就是用来日志收集和传输的.
0.8版本开始支持复制, 不支持事务, 对消息的重复、丟失、错误没有严格要求适合产生大量数据的互联网服务的数据收集业务. 也可以实现消息不丢失,但是会影响性能.
特点:
分布式. 支持消息分区.
跨平台. 对于一些异构的系统就很友好了.
实时性. 上亿级的堆积能力,离线处理.
伸缩性. 支持水平扩展.
同时为发布和订阅提供高吞吐量. 据了解,Kafka每秒可以生产约25万消息(50 MB),每秒处理55万消息(110 MB).
可进行持久化操作. 将消息持久化到磁盘,因此可用于批量消费,例如ETL,以及实时应用程序. 通过将数据持久化到硬盘以及 replicas 防止数据丢失.
分布式系统,易于向外扩展. 所有的producer、broker和consumer都会有多个,均为分布式的. 无需停机即可扩展机器.
消息被处理的状态是在consumer端维护,而不是由server端维护. 当失败时能自动平衡.
支持online和offline的场景.
Kafka 架构
基本概念
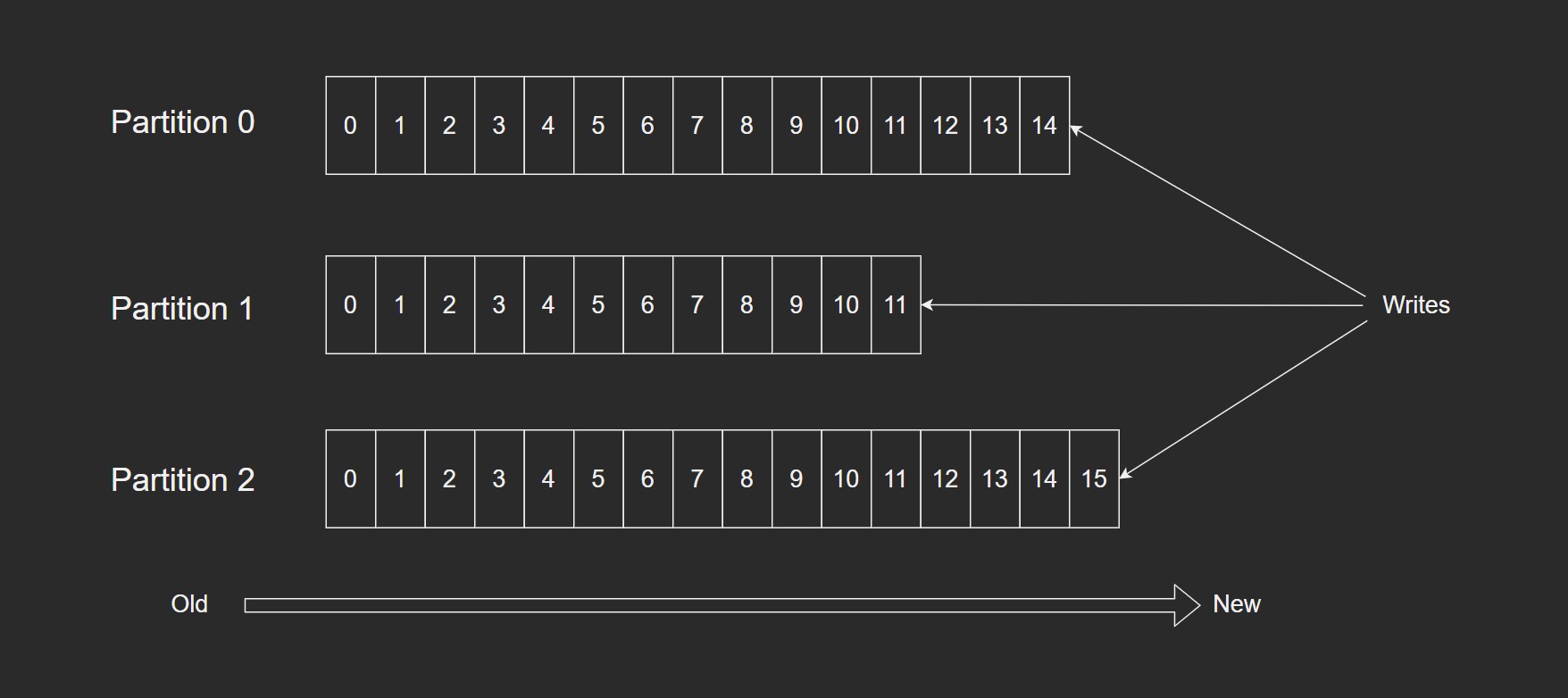
Topic: 特指Kafka处理的消息源(feeds of messages)的不同分类.Partition: Topic 物理上的分组,一个Topic可以分为多个Partition,每个Partition是一个有序的队列. Partition中的每条消息都会被分配一个有序的id(offset).Message: 消息,是通信的基本单位,每个producer可以向一个topic(主题)发布一些消息.Producers: 消息和数据生产者,向Kafka的一个topic发布消息的过程叫做producers.Consumers: 消息和数据消费者,订阅topics并处理其发布的消息的过程叫做consumers.Broker: 缓存代理,Kafka集群中的一台或多台服务器统称为broker.
发送消息的流程
- Producer根据指定的partition方法(round-robin、hash等),将消息发布到指定topic的partition里面.
- kafka集群接收到Producer发过来的消息后,将其持久化到硬盘,并保留消息指定时长(可配置),而不关注消息是否被消费.
- Consumer从kafka集群pull数据,并控制获取消息的offset
Kafka 优秀的设计
- 顺序写. Page cache,空中接力,高效读写.
- 顺序写盘. 可以提高磁盘的利用率. 比如顺序消费数据,而不删除已经消费的数据,避免了磁盘随机写,删除的话会导致 offset 发生变化. 一般MQ都是不允许删除消息的.
- Page cache.
- 高性能,高吞吐.
- 后台异步,主动flush.
- zero-copy,减少IO操作步骤. 采用 linux Zero-Copy 提高发送性能. 传统数据发送需要发送4次上下文的切换,次啊用sendfile系统调用之后,数据直接在内核内存,系统上下文切换减少为2次.
Page cache: 是由操作系统实现的磁盘缓存. CUP如果要访问磁盘的文件,首先要把文件拷贝到内存中,但是由于硬件的限制,从磁盘到内存的速度是很慢的,如果物理内存有剩余,可以使用物理内存来缓存这些磁盘的内容,而这部分被用作缓存磁盘文件的内存就叫做 page cache. 其实就是把磁盘的内容缓存到内存,把对磁盘的访问转为对内存的访问,空间换时间.
用户进程启动read()系统调用后,内核会首先查看page cache里有没有用户要读取的文件内容,如果有(cache hit),那就直接读取,没有的话(cache miss)再启动 I/O操作 从磁盘上读取,然后放到page cache中,下次再访问这部分内容的时候,就可以cache hit.
通过网络发送到消费者的进程. kafka肯定有多个订阅者,生产者生产消息肯定被多个订阅者消费.
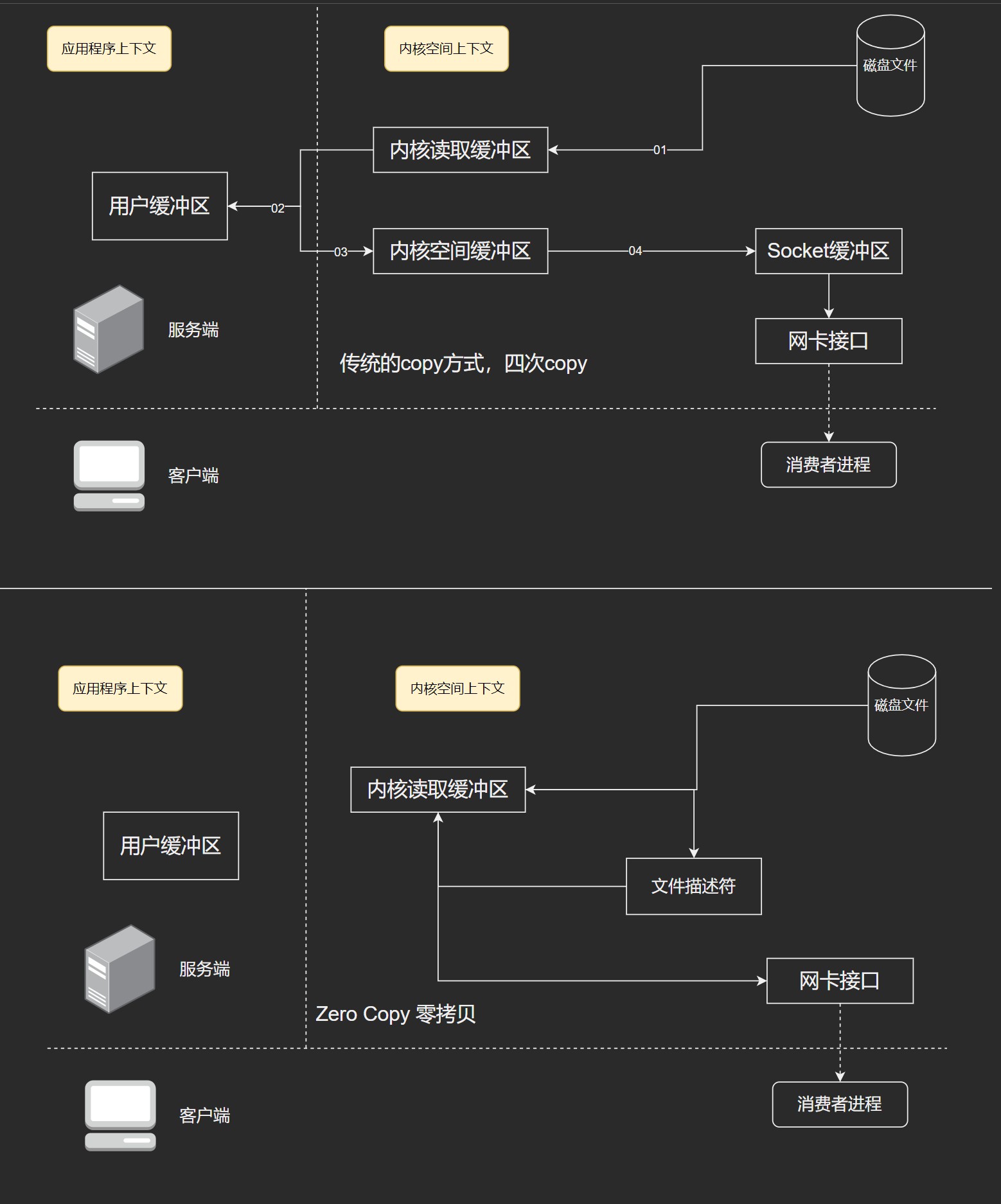
zero copy 只是将磁盘数据复制到页面缓存一次,然后将页面缓存直接发送给消费者进程. 例如: 如果有10个请求,如果使用传统的方式,需要 copy 40次,但是如果使用zero copy,只需要11次即可.
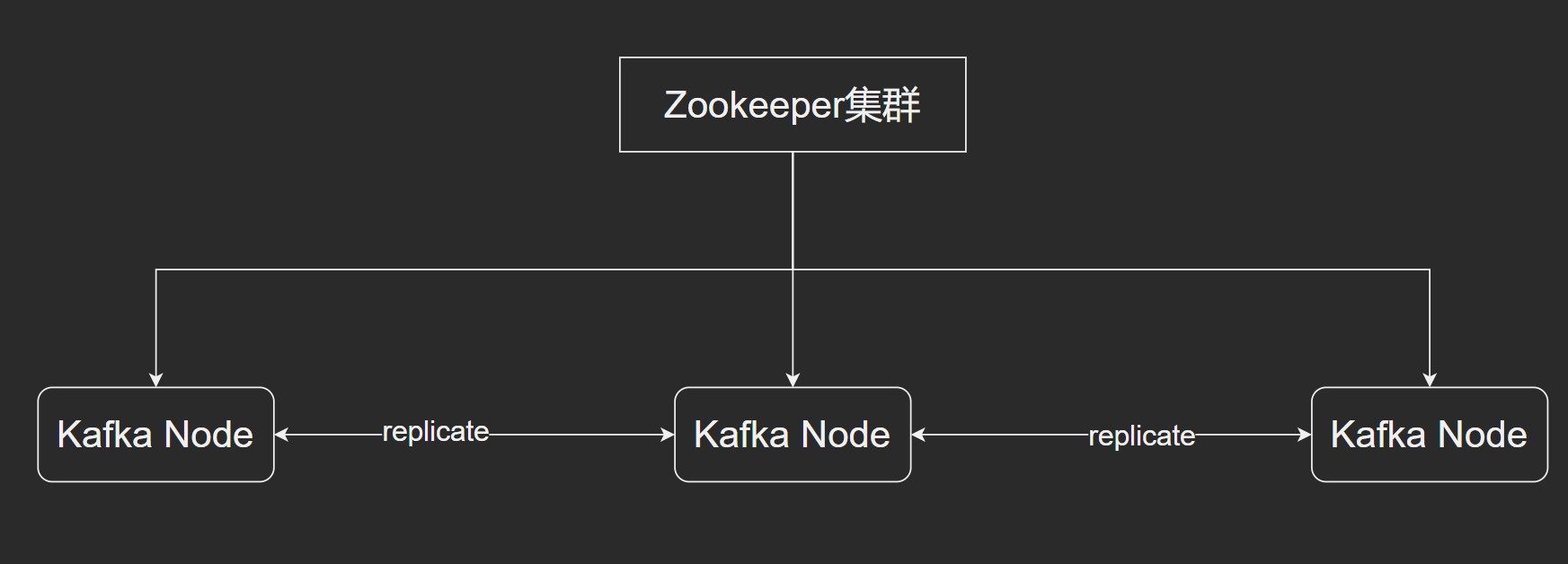
Kafka 集群模式
使用 Zookeeper 实现. Kafka 的 replicate 大部分时间都是内存级别的.
Kafka 安装
下载地址: http://kafka.apache.org/downloads.html
在 192.168.123.197 部署
# 注意需要依赖zookeeper环境 zookeeper 在 192.168.123.26
wget https://mirror.bit.edu.cn/apache/kafka/2.6.0/kafka_2.13-2.6.0.tgz
tar -zxvf kafka_2.13-2.6.0.tgz -C /usr/local/
cd /usr/local
mv kafka_2.13-2.6.0/ kafka_2.6.0/
# 修改配置文件
vim /usr/local/kafka_2.6.0/config/server.properties
# 创建日志文件夹
mkdir /usr/local/kafka_2.6.0/kafka-logs -p
# 启动
/usr/local/kafka_2.6.0/bin/kafka-server-start.sh /usr/local/kafka_2.6.0/config/server.properties &
修改配置
broker.id=0
advertised.listeners=192.168.123.197:9092
log.dirs=/usr/local/kafka_2.6.0/kafka-logs
num.partitions=2
zookeeper.connect=192.168.123.26:2181
进入 zookeeper 查看连接情况
# 进入客户端
./zkCli.sh -server 192.168.123.26:2181
# 查看目录
ls /
# 查看节点
ls /brokers/ids
Kafka 常用指令
# 创建 topic 主题
# --zookeeper zk服务列表
# --create 指令后面 --topic 为创建topic并指定 topic name
# --partitions 为指定分区数量
# --replication-factor 为指定副本集数量
./kafka-topics.sh --zookeeper 192.168.123.26:2181 --create --topic topic02 --partitions 1 --replication-factor 1
# 查看 topic 列表指令
./kafka-topics.sh --zookeeper 192.168.123.26:2181 --list
# 查看 topic 状态
./kafka-topics.sh --zookeeper 192.168.123.26:2181 --topic topic1 --describe
# 发送数据指令 之后就可以输入要发送的数据 ctrl+c 停止输入
./kafka-console-producer.sh --broker-list 192.168.123.197:9092 --topic topic1
# 接收数据指令
./kafka-console-consumer.sh --bootstrap-server 192.168.123.197:9092 --topic topic1 --from-beginning
# 删除 topic 指令
./kafka-topics.sh --zookeeper 192.168.123.26:2181 --delete --topic topic1
# 查看所有组 console-consumer-77292
./kafka-consumer-groups.sh --bootstrap-server 192.168.123.197:9092 --list
# 查看消费进度
./kafka-consumer-groups.sh --bootstrap-server 192.168.123.197:9092 --describe --group group02

Kafka 与 SpringBoot 整合
生成者
spring:
kafka:
bootstrap-servers: 192.168.123.197:9092
producer:
retries: 0 # 消息发送失败时重试次数
batch-size: 16384 # 批量发送消息 16384 redis slot 数量
buffer-memory: 33554432 # 生产者内存缓存区的大小(32M)
# 消息序列化
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
# 核心配置
# 0 : 生产者在消息成功写入消息之前不会再等待任何来自服务器的响应
# 1 : 只要集群的首领节点收到消息,生产者就会收到一个来自服务器成功响应
# -1 : 表示分区leader必须等待消息被成功写入到所有的ISR副本(同步副本)中才认为produce请求成功. 这种方案提供了最高的消息持久性保证,当理论上吞吐率是最差的.
acks: 1
package org.lgq.producer;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.SendResult;
import org.springframework.stereotype.Component;
import org.springframework.util.concurrent.ListenableFuture;
import org.springframework.util.concurrent.ListenableFutureCallback;
/**
* @author DevLGQ
* @version 1.0
*/
@Component
public class KafkaProducerService {
private static final Logger log = LoggerFactory.getLogger(KafkaProducerService.class);
@Autowired
private KafkaTemplate<String, Object> kafkaTemplate;
public void sendMessage(String topic, Object object) {
ListenableFuture<SendResult<String, Object>> future = this.kafkaTemplate.send(topic, object);
future.addCallback(new ListenableFutureCallback<>() {
@Override
public void onFailure(Throwable ex) {
log.error("发送消息失败: {}", ex.toString());
}
@Override
public void onSuccess(SendResult<String, Object> result) {
log.info("发送消息成功:{}", result.toString());
}
});
}
}
消费者
spring:
kafka:
bootstrap-servers: 192.168.123.197:9092
# consumer 消息的签收机制: 手工签收
consumer:
enable-auto-commit: false
# 该属性指定了消费者在读取一个没有偏移量的分区或者偏移量无效的情况下该作何处理
# earliest: 在偏移量无效的情况下,消费者将从起始位置读取分区的记录
# latest: 默认值. 在偏移量无效的情况下,消费者将从最新的记录开始读取数据(消费者启动之后的记录)
auto-offset-reset: earliest
# 消息反序列化
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
listener:
ack-mode: manual
concurrency: 5
package org.lgq.consumer;
import org.apache.kafka.clients.consumer.Consumer;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.support.Acknowledgment;
import org.springframework.stereotype.Component;
/**
* @author DevLGQ
* @version 1.0
*/
@Component
public class KafkaConsumerService {
private static final Logger log = LoggerFactory.getLogger(KafkaConsumerService.class);
@KafkaListener(groupId = "group02", topics = "topic02")
public void onMessage(ConsumerRecord<String, Object> record, Acknowledgment acknowledgment, Consumer<?, ?> consumer) {
log.info("消费端接收消息: {}", record.value());
// 手工签收
acknowledgment.acknowledge();
}
}
海量日志设计
核心是 Kafka 中间件的缓冲,Beats 是生产者,Logstash 是消费者.
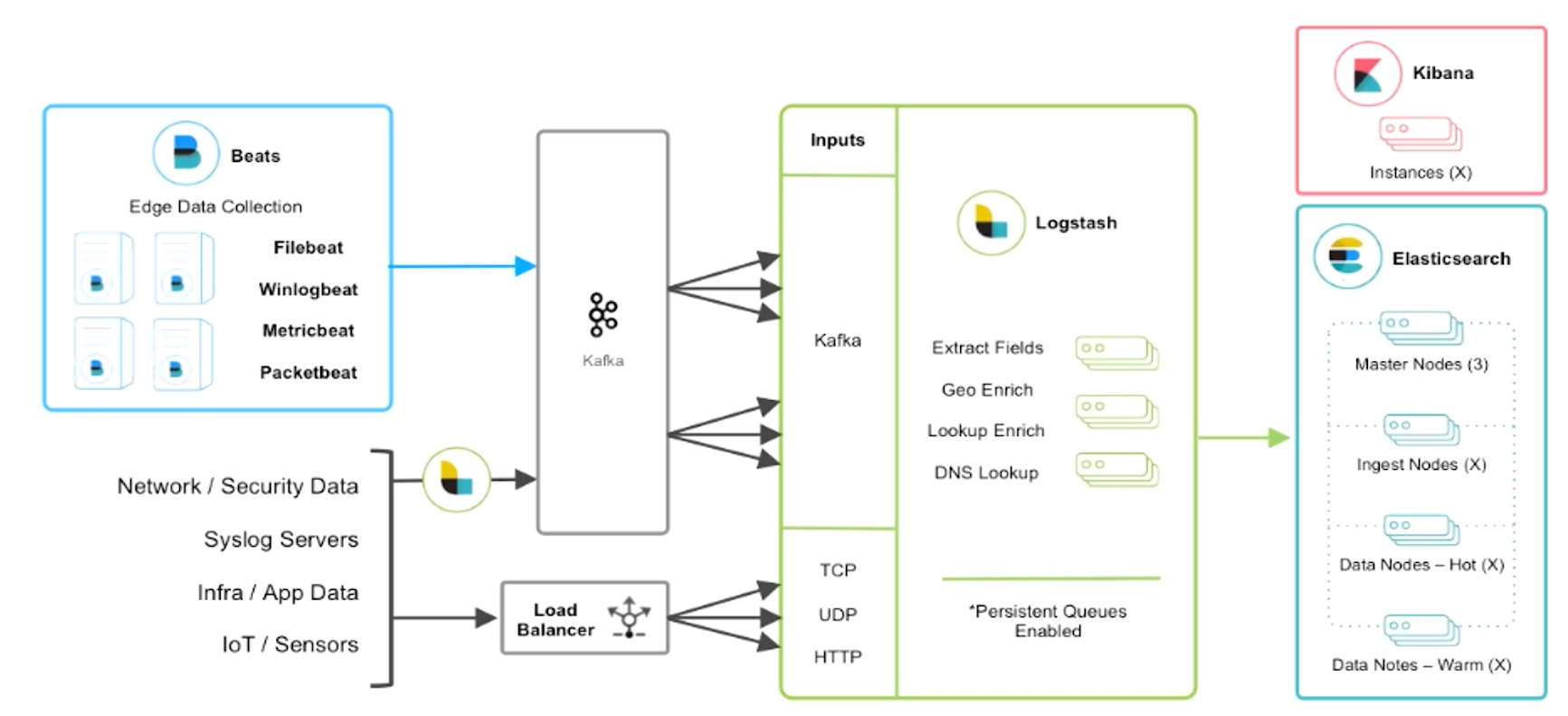
日志框架使用 log4j2,性能比Spring默认的 logback 好,底层是基于无锁并行框架 Disruptor 的.
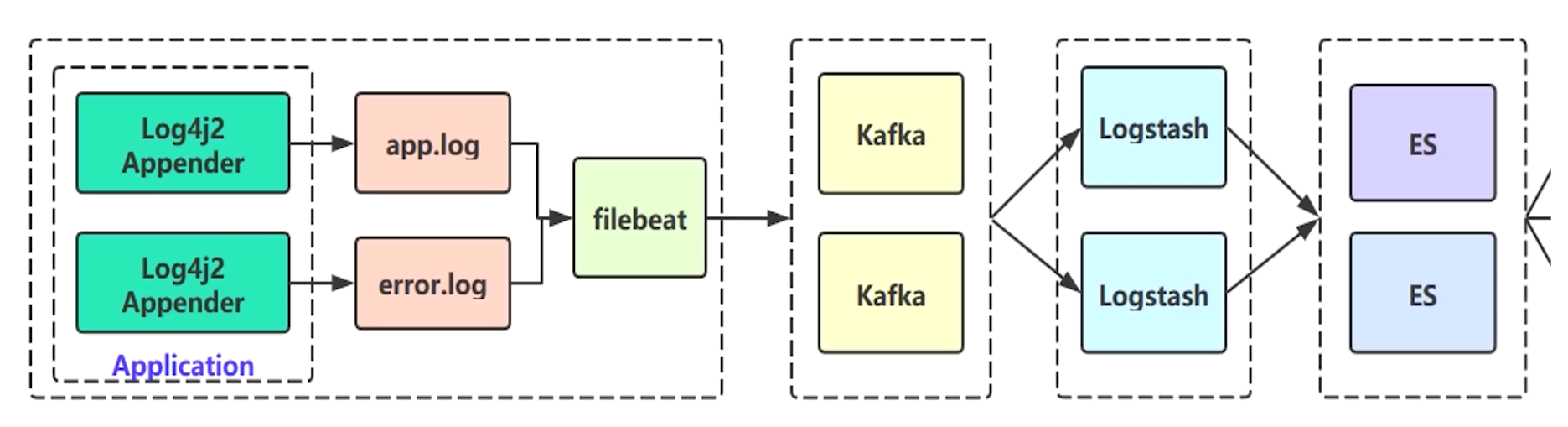
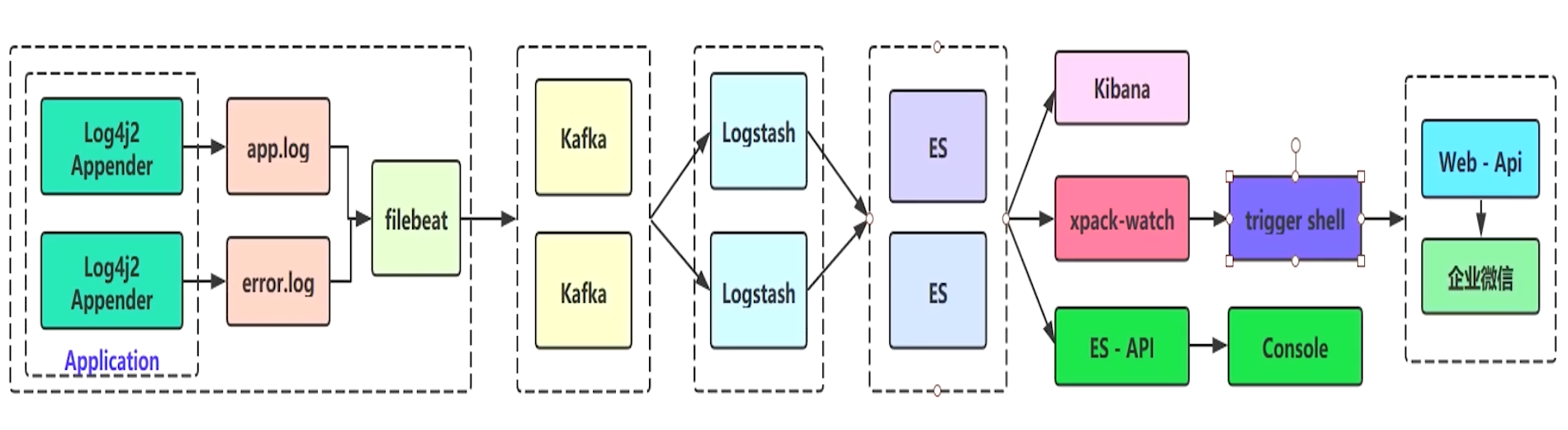
application -> filebeat -> kafka -> logstash -> elasticsearch -> kibana
日志输出
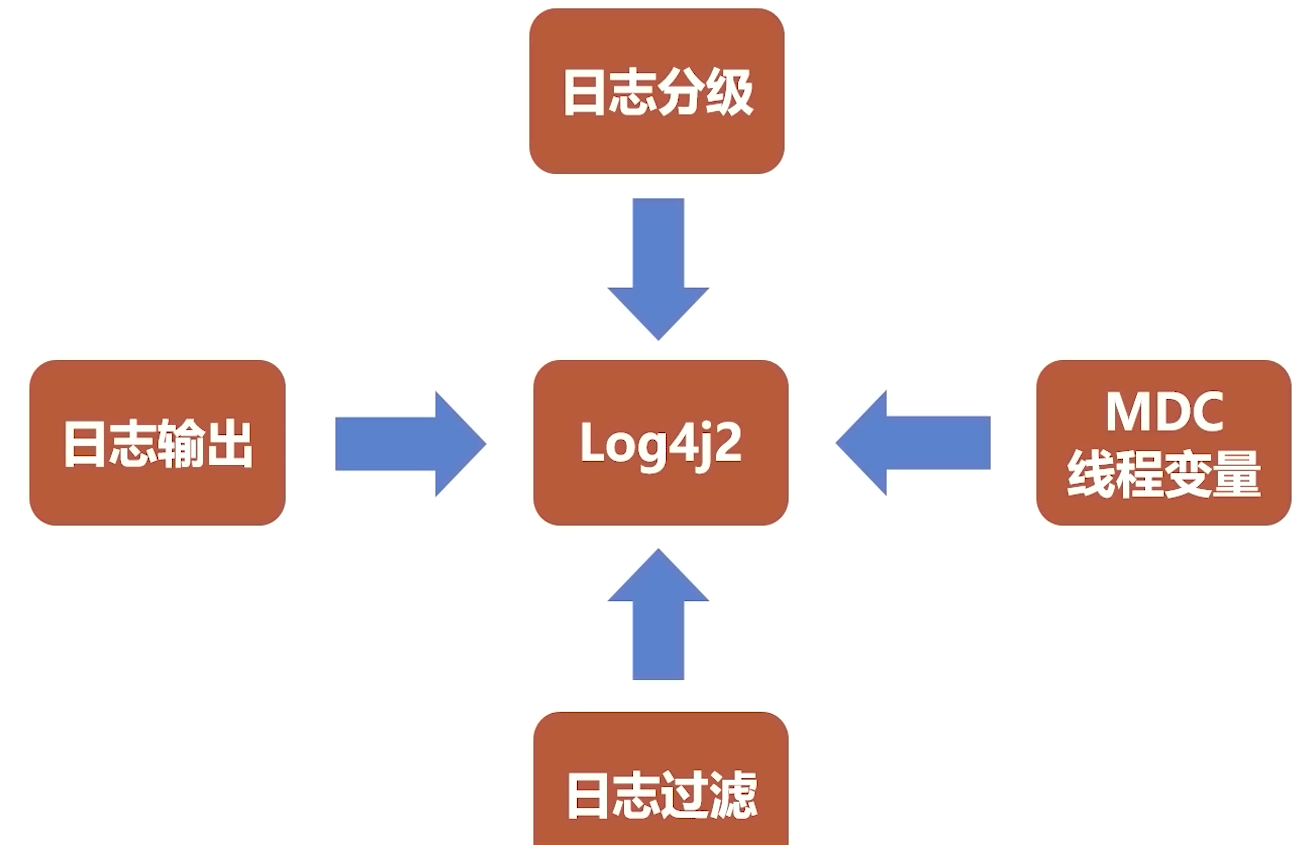
FileBeat 安装
下载地址: https://www.elastic.co/cn/downloads/beats/filebeat
tar -zxvf filebeat-7.10.0-linux-x86_64.tar.gz -C /usr/local
cd /usr/local/filebeat-7.10.0-linux-x86_64
# 创建配置文件 filebeat.yml
# 检查配置文件
./filebeat test config -c filebeat.yml
# 指定配置文件启动
./filebeat run -c filebeat.yml
# 查看
ps -ef | grep filebeat
FileBeat 日志输出
打包工程
<build>
<finalName>collector</finalName>
<!-- 打包时包含 yml -->
<resources>
<resource>
<directory>src/main/java</directory>
<includes>
<include>**/*.yml</include>
<include>**/*.xml</include>
</includes>
<!-- 是否替换资源中的属性-->
<filtering>true</filtering>
</resource>
<resource>
<directory>src/main/resources</directory>
</resource>
</resources>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<mainClass>org.lgq.CollectorApplication</mainClass>
</configuration>
</plugin>
</plugins>
</build>
上传jar到 /usr/local 后启动 java -jar collector.jar
启动 Kafka 后创建相应的 topic
# 启动
./kafka-server-start.sh config/server.properties &
# 创建相应的 topic
./kafka-topics.sh --zookeeper 192.168.123.26:2181 --create --topic app-log-collector --partitions 1 --replication-factor 1
./kafka-topics.sh --zookeeper 192.168.123.26:2181 --create --topic error-log-collector --partitions 1 --replication-factor 1
# 查看 topic
./kafka-topics.sh --zookeeper 192.168.123.26:2181 --list
启动 filebeat
./filebeat
查看 Kafka 有没有数据
./kafka-topics.sh --zookeeper 192.168.123.26:2181 --topic app-log-collector --describe
# 进入 kafka 的安装目录,查看 /kafka-logs 目录
Logstash 配置
在日志架构里面,相当于 kafka 的消费者.
# conf下配置文件说明:
# logstash配置文件: /config/logstash.yml
# JVM参数文件: /config/jvm.options
# 日志格式配置文件: /config/log4j2.properties
# 制作Linux服务参数: /config/startup.options
vim /usr/local/logstash-7.10.0/config/logstash.yml
# 增加workers工作线程数 可以有效的提升logstash性能
pipeline.workers: 16
mkdir script
vim script/logstash-script.conf
# 启动
./logstash -f ../script/logstash-script.conf
# 后台启动
nohup ./logstash -f ../script/logstash-script.conf 2>&1 &
# 指令参数说明
# --path.config 或 –f: logstash启动时使用的配置文件.
# --configtest 或 –t: 测试Logstash读取到的配置文件语法是否能正常解析.
# --log 或 -l: 日志输出存储位置.
# --pipeline.workers 或 –w: 运行filter和output的pipeline线程数量. 默认是CPU核数.
# --pipeline.batch.size 或 –b: 每个Logstashpipeline线程,在执行具体的filter和output函数之前,最多能累积的.
# --pipeline.batch.delay 或 –u: 每个Logstashpipeline线程,在打包批量日志的时候,最多等待几毫秒.
# --verbose: 输出调试日志.
# --debug: 输出更多的调试日志.
# 数据目录在安装目录的 data 下面
# logstash 插件
# https://github.com/logstash-plugins
# 在安装目录的 vendor/bundle/jruby/{version}/gems 下面
# 查看插件列表
./logstash-plugin list
# 更新插件
./logstash-plugin update plugin-name
# 安装插件
./logstash-plugin install plugin-name
Kibana 安装
下载地址: https://www.elastic.co/cn/downloads/kibana
部署在 192.168.123.128
# 注意,依赖 node 环境
tar -zxvf kibana-7.10.0-linux-aarch64.tar.gz -C /usr/local
cd /usr/local
mv kibana-7.10.0-linux-aarch64/ kibana-7.10.0
# 修改配置文件
vim config/kibana.yml
# 对外暴露服务的地址
server.host: "192.168.123.128"
# 配置Elasticsearch
elasticsearch.hosts: ["http://192.168.123.26:9200"]
# 启动
./bin/kibana
# 通过浏览器进行访问 http://192.168.123.128:5601/app/kibana
Kibana 使用
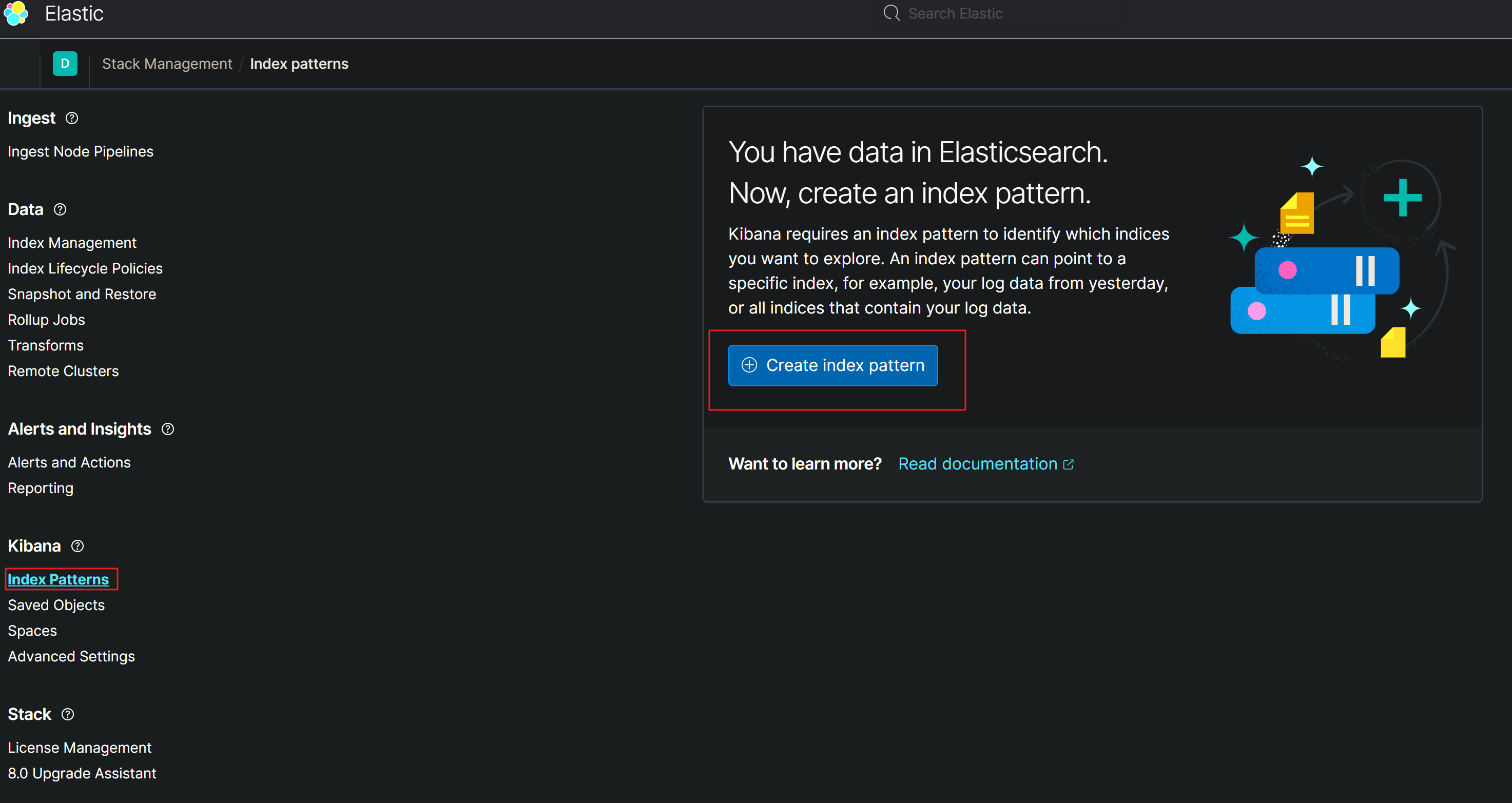
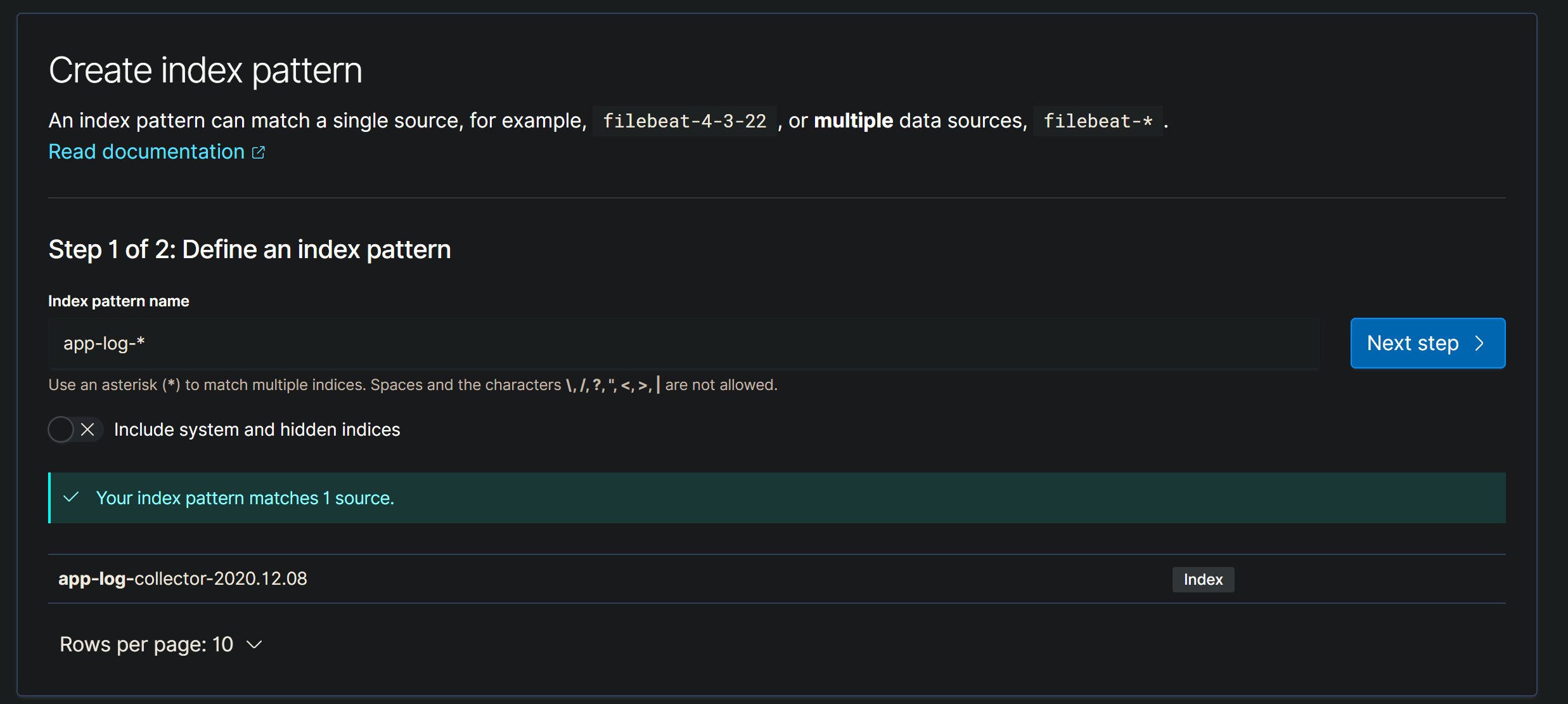
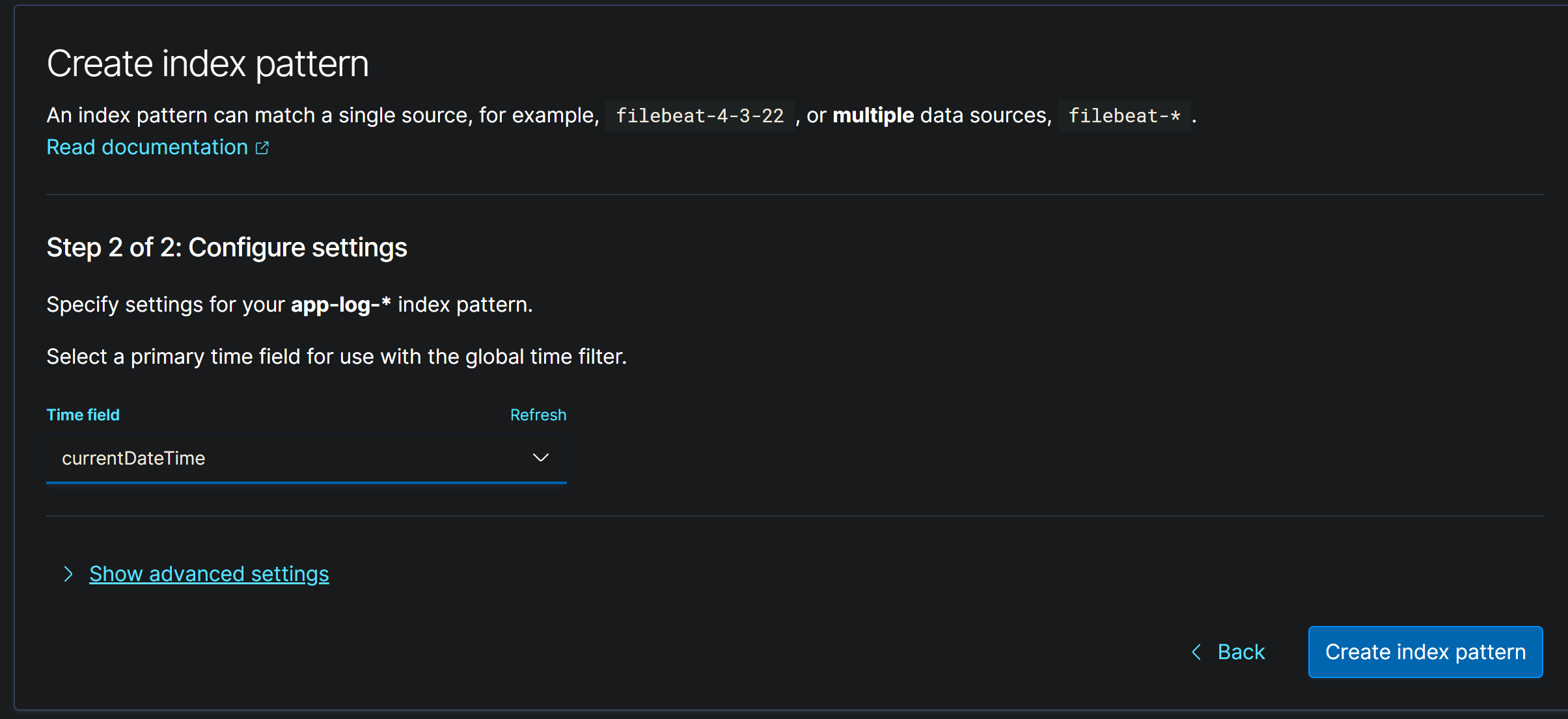
设置完成之后,查看信息
找到Discover后打开
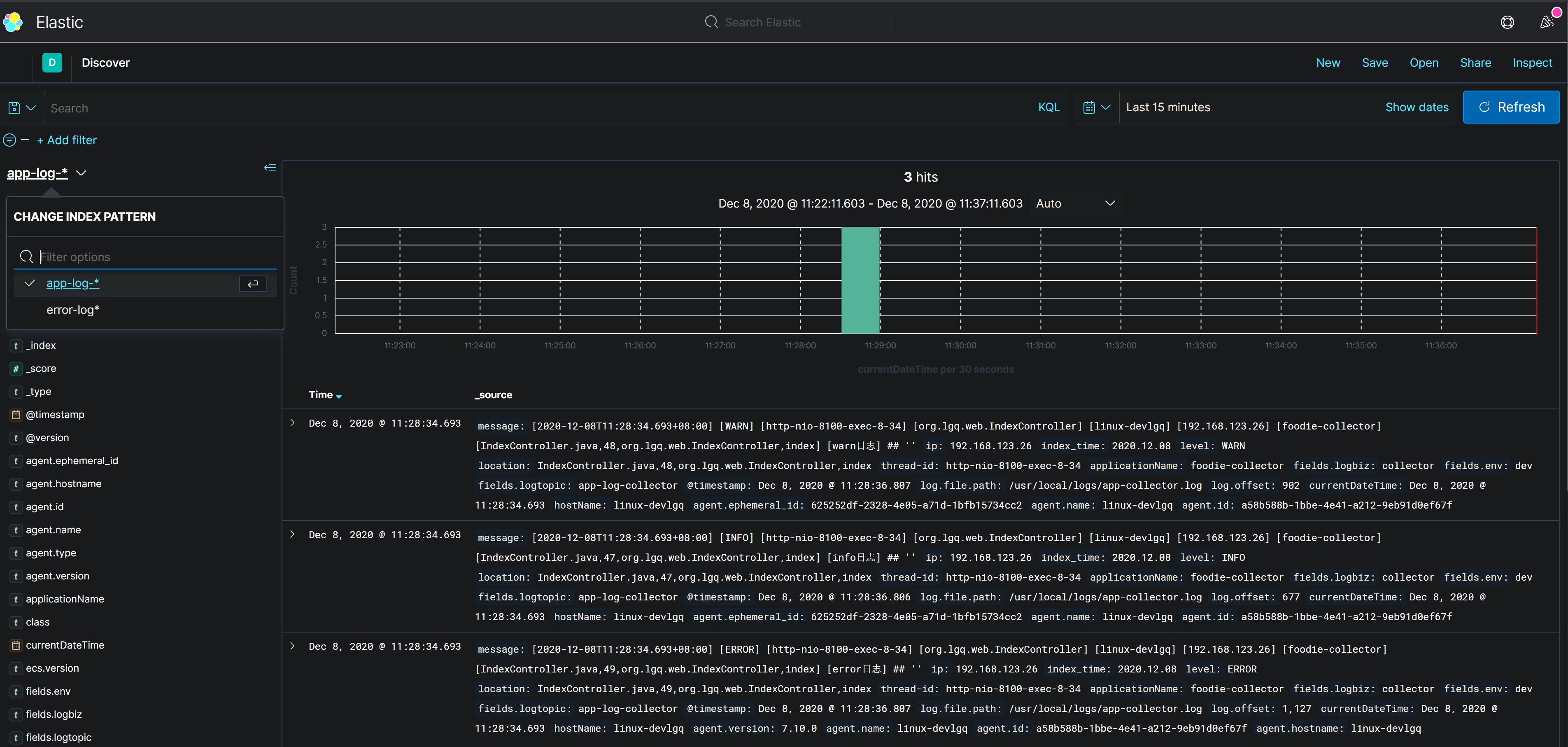
日志持久化、可视化
ElasticSearch 索引创建周期,命名规范.
Kibana 控制台应用,可视化日志.
日志监控告警
使用 ES 的 watch,这个功能是试用功能,需要开启才行.
详细查看 watch_api.http 文件.

博客内容遵循 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 协议
本文永久链接是:https://blog.lgq51233.xyz/2020/06/13/Kafka%E6%97%A5%E5%BF%97%E5%AE%9E%E6%88%98/