
Java的线程池
线程池
线程池目标: 复用 Worker(线程) 处理Task, 提高线程的可管理性.
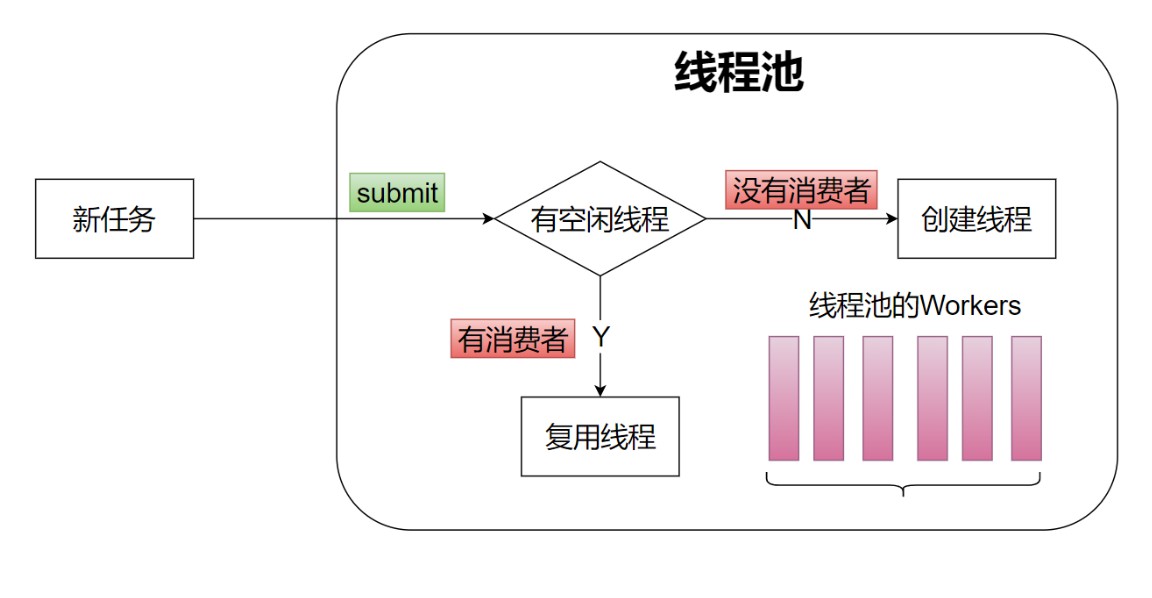
每个任务尽快交给一个线程处理。线程不够->新建线程。
线程复用–尽量减少线程的创建带来的开销。
传统模式

反向压力(BackPressure)实现. 通常用有界缓冲区实现的队列会在消费者忙不过来的时候被填满, 而生产者会一直工作到缓冲区满之后被阻塞或者拒绝, 也就是生产者在把队列填满的时候才感受到反向传来的压力, 将自己阻塞或者被拒绝.

消费者唤醒生产. 使用双向队列(Dual Queue).
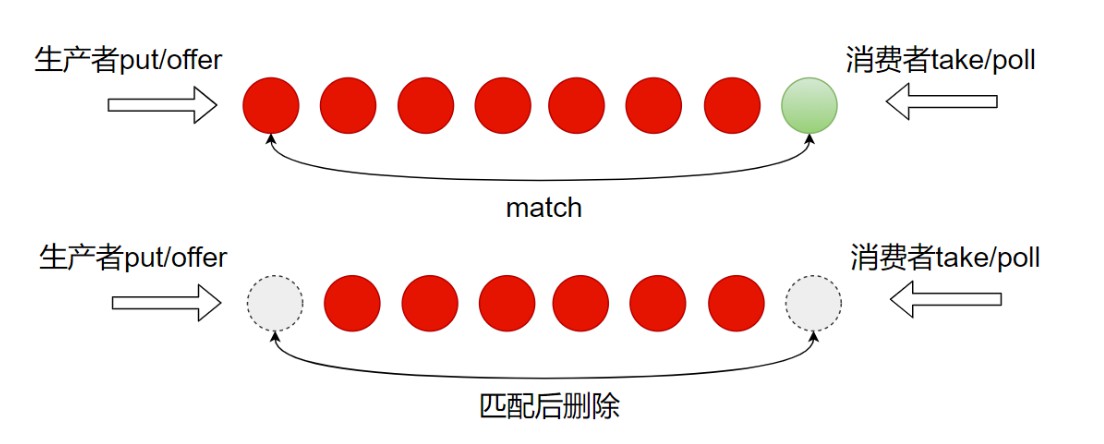
保持基于Task的接口操作. 判断是否匹配, 如果匹配就删除. 传统的模式, 要缓冲区填满才能感受到压力.
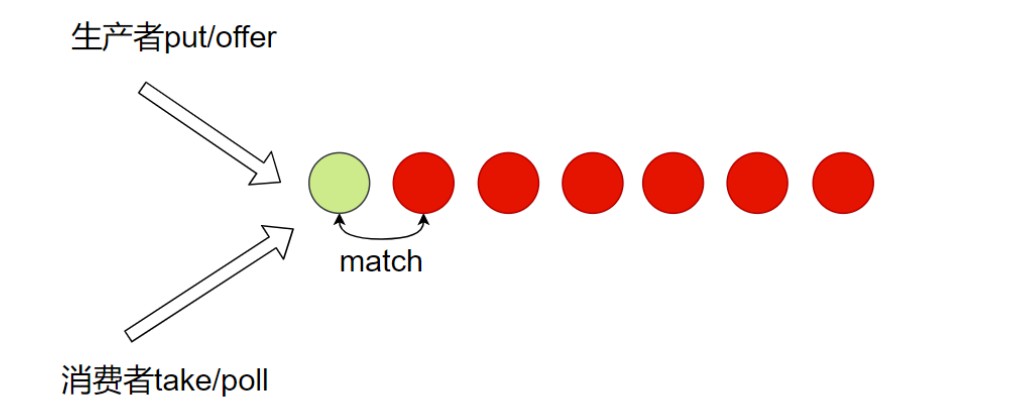
同样能力, 双向栈(Dual Stack). 生产者和消费者都在一端. 区别在于顺序, 队列是FIFO(具有公平性), 而栈是FILO(具有更好的性能).
- 生产者等待消费者足够再生产
- 消费者等待生产者足够再消费
传统目标: 生产者生产有足够空间就生产, 消费者有足够元素就消费(生产者-消费者之间没有默契)
DualQueue(FIFO): 公平; DualStack(FILO): 非公平, 但是性能更好.
Executors
利用 Executors 创建不同的线程池来满足不同场景的需求.
newFixedThreadPool(int nThreads);指定工作线程数量的线程池. Worker数目固定. 例如: nginx.newCachedThreadPool();处理大量短时间工作任务的线程池.- 试图缓存线程并重用, 当无缓存线程可用时, 就会创建新的工作线程.
- 如果线程闲置的时间超过阈值(一般60s), 则会被终止并移除缓存.
- 系统长时间闲置的时候, 不会消耗什么资源.
newSingleThreadExecutor();创建唯一的工作者线程来执行任务, 如果线程异常结束, 会有另外一个线程来取代它. 最大特定是可保证顺序执行任务.newSingleThreadScheduledExecutor();和newSingleThreadScheduledExecutor(ThreadFactory threadFactory);定时或者周期性的工作调度, 两者的区别在于单一工作线程还是多个线程。newWorkStealingPool();内部会构建 ForkJoinPool, 利用 working-stealing 算法, 并行地处理任务, 不保证处理顺序.
Fork/Join 框架
把大任务分割成若干各小任务并行执行,最终汇总每个小任务结果后得到大任务结果的框架,适合计算密集型的任务。
working-stealing 算法 : 某个线程从其它队列里窃取任务来执行.
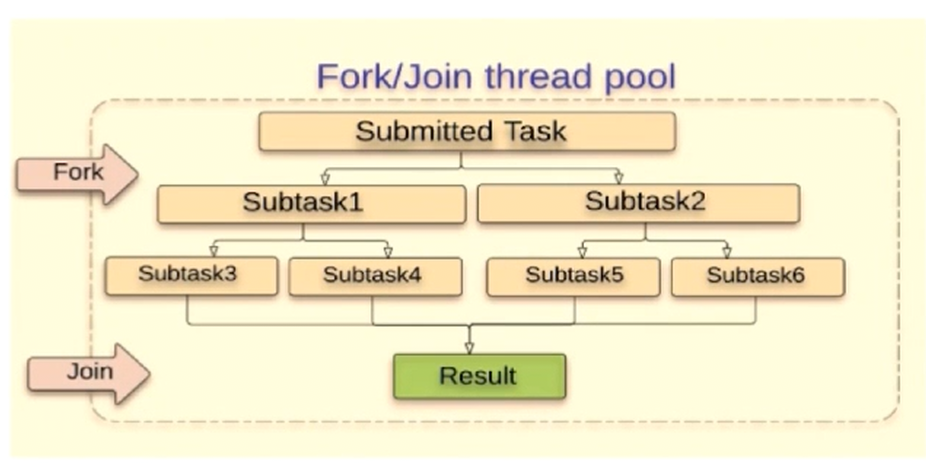
下面写个例子对比单线程,普通多线程,ForkJoin模式下的性能
private final static ThreadPoolExecutor executor = new ThreadPoolExecutor(
8, 20, 60L, TimeUnit.SECONDS, new LinkedBlockingDeque<>(5),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.AbortPolicy()
);
public static void main(String[] args) throws ExecutionException, InterruptedException {
// 构造测试数据
int length = 100_000_000;
long[] arr = new long[length];
for (int i = 0; i < length; i++) {
arr[i] = ThreadLocalRandom.current().nextInt(Integer.MAX_VALUE);
}
// 单线程
singleThreadSum(arr);
// 多线程
multiThreadSum(arr);
// ForkJoinPool线程池
forkJoinSum(arr);
// Stream并行,底层也是使用 ForkJoin
streamSum(arr);
}
单线程
/**
* 单线程
*
* @param arr
*/
private static void singleThreadSum(long[] arr) {
long start = System.currentTimeMillis();
long sum = 0;
for (int i = 0; i < arr.length; i++) {
// 模拟耗时
sum += (arr[i] / 5 * 5 / 5 * 5 / 5 * 5 / 5 * 5 / 5 * 5);
}
System.out.println("sum: " + sum);
System.out.println("single thread elapse: " + (System.currentTimeMillis() - start));
}
多线程
/**
* 普通多线程
*
* @param arr
* @throws ExecutionException
* @throws InterruptedException
*/
private static void multiThreadSum(long[] arr) throws ExecutionException, InterruptedException {
long start = System.currentTimeMillis();
int count = 8;
// ExecutorService threadPool = Executors.newFixedThreadPool(count);
ExecutorService threadPool = executor;
// 任务结果列表
List<Future<Long>> list = new ArrayList<>();
for (int i = 0; i < count; i++) {
int num = i;
// 分段提交任务
Future<Long> future = threadPool.submit(() -> {
long sum = 0;
for (int j = arr.length / count * num; j < (arr.length / count * (num + 1)); j++) {
try {
// 模拟耗时
sum += (arr[j] / 5 * 5 / 5 * 5 / 5 * 5 / 5 * 5 / 5 * 5);
} catch (Exception e) {
e.printStackTrace();
}
}
return sum;
});
list.add(future);
}
// 每个段结果相加
long sum = 0;
for (Future<Long> future : list) {
sum += future.get();
}
threadPool.shutdown();
System.out.println("sum: " + sum);
System.out.println("multi thread elapse: " + (System.currentTimeMillis() - start));
}
ForkJoin框架
/**
* Fork/join 算法(working-stealing)
*
* @param arr
* @throws ExecutionException
* @throws InterruptedException
*/
private static void forkJoinSum(long[] arr) throws ExecutionException, InterruptedException {
long start = System.currentTimeMillis();
ForkJoinPool forkJoinPool = ForkJoinPool.commonPool();
// 提交任务
ForkJoinTask<Long> forkJoinTask = forkJoinPool.submit(new SumTask(arr, 0, arr.length));
// 获取结果
Long sum = forkJoinTask.get();
forkJoinPool.shutdown();
System.out.println("sum: " + sum);
System.out.println("fork join elapse: " + (System.currentTimeMillis() - start));
}
private static class SumTask extends RecursiveTask<Long> {
private final long[] arr;
private final int from;
private final int to;
public SumTask(long[] arr, int from, int to) {
this.arr = arr;
this.from = from;
this.to = to;
}
@Override
protected Long compute() {
// 小于1000的时候直接相加,可灵活调整
if (to - from <= 1000) {
long sum = 0;
for (int i = from; i < to; i++) {
// 模拟耗时
sum += (arr[i] / 5 * 5 / 5 * 5 / 5 * 5 / 5 * 5 / 5 * 5);
}
return sum;
}
// 分成两段任务
int middle = (from + to) / 2;
SumTask left = new SumTask(arr, from, middle);
SumTask right = new SumTask(arr, middle, to);
// 提交左边的任务
left.fork();
// 右边的任务直接利用当前线程计算,节约开销
Long rightResult = right.compute();
// 等待左边计算完毕
Long leftResult = left.join();
// 返回结果
return leftResult + rightResult;
}
}
Stream并行
/**
* stream函数式实现
*
* @param arr
*/
private static void streamSum(long[] arr) {
long start = System.currentTimeMillis();
long sum = Arrays.stream(arr)
.parallel()
.reduce(0,
(left, right) -> (left / 5 * 5 / 5 * 5 / 5 * 5 / 5 * 5 / 5 * 5) + (right / 5 * 5 / 5 * 5 / 5 * 5 / 5 * 5 / 5 * 5));
System.out.println("sum: " + sum);
System.out.println("stream elapse: " + (System.currentTimeMillis() - start));
}
运行结果:
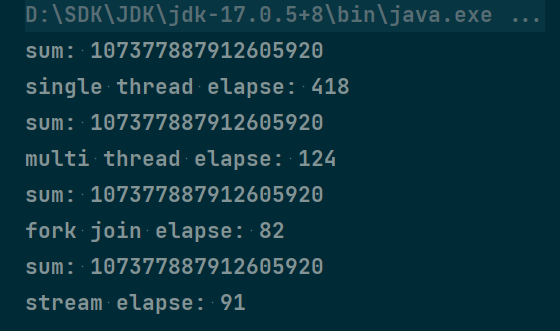
运行多次,可以看到,ForkJoin框架的速度会比普通多线程是要快的。
Executor 框架
上面5个线程池都是Executor接口的实现类.
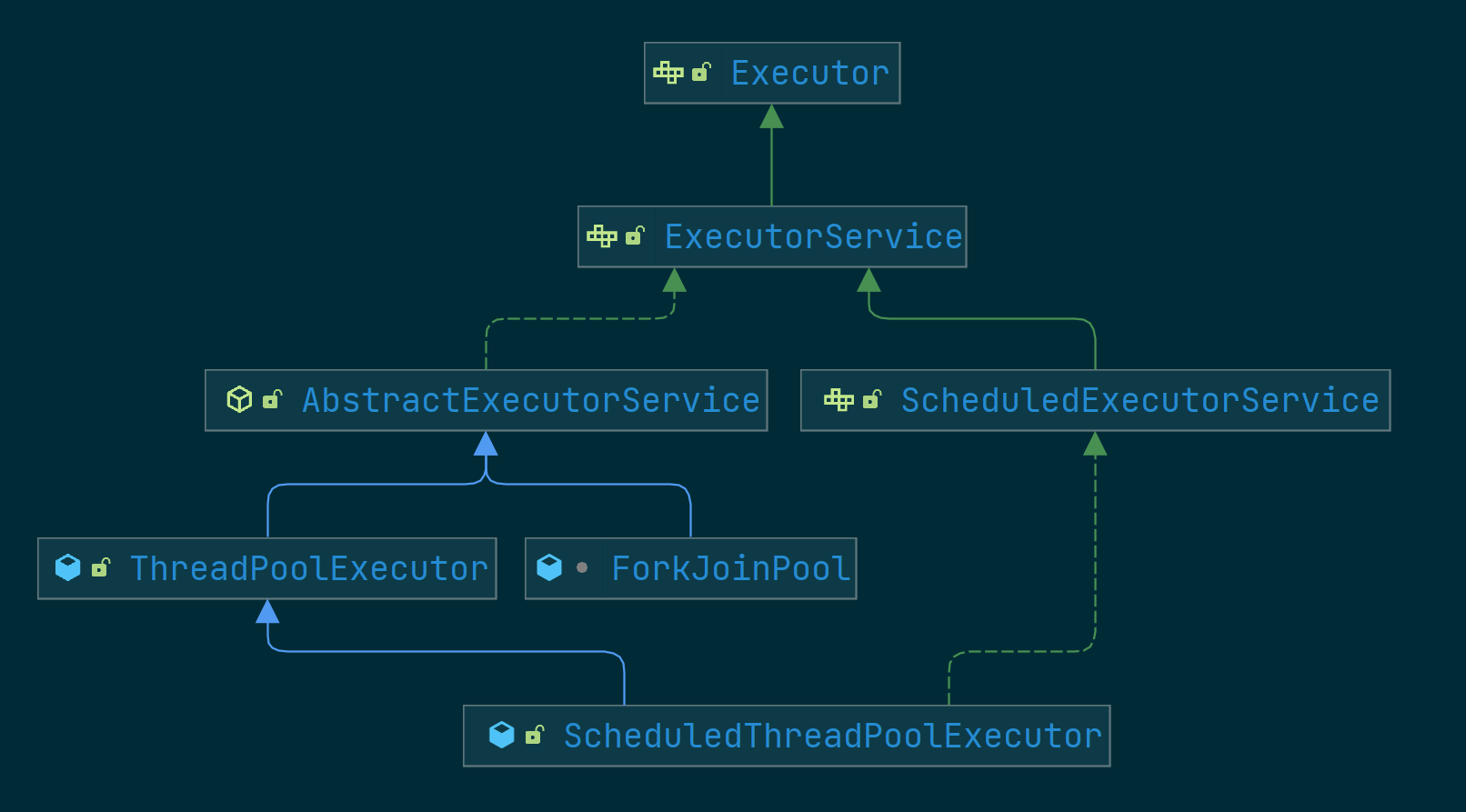
J.U.C 的三个 Executor 接口。
- Executor : 运行新任务的接口, 将任务提交和任务执行细节的解耦。
- ExecutorService : 具备管理执行器和任务生命周期的方法, 提交任务机制更完善(e.g.
shutdown(),isShutdown(),submit()…)。 - ScheduledExecutorService : 支持
Future和定期执行任务。
ThreadPoolExecutor
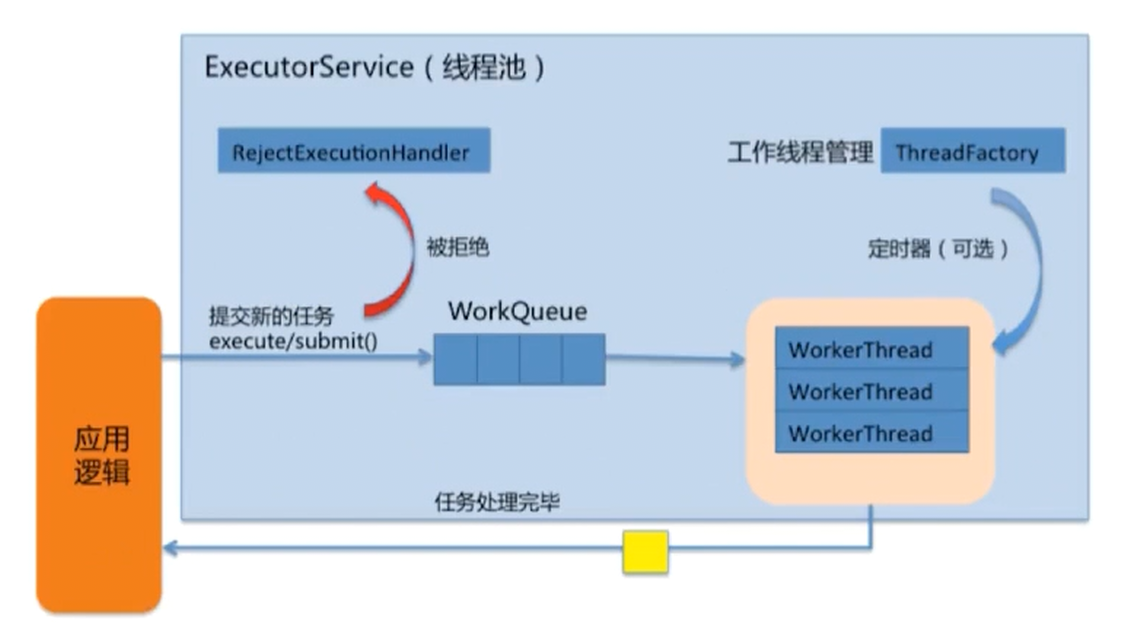
// 7个重要参数
public ThreadPoolExecutor(int corePoolSize, // 核心线程数量, 长期驻留的线程数.
int maximumPoolSize, // 线程不够用时能够创建的最大线程数
long keepAliveTime, // 抢占的顺序不一定, 存活时间所以看运气
TimeUnit unit, // 时间单位
BlockingQueue<Runnable> workQueue, // 任务等待队列
ThreadFactory threadFactory, // 创建新线程的工厂类, 默认是Executors.defaultThreadFactory()
RejectedExecutionHandler handler) // 线程池的饱和策略
{
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
RejectedExecutionHandler,任务饱和拒绝策略
AbortPolicy: 直接抛出异常, 这是默认策略。CallerRunsPoliy: 用调用者所在的线程来执行任务。DiscardOldestPolicy: 丢弃队列中最靠前的任务, 并执行当前任务。DiscardPolicy: 直接丢弃任务。- 实现
RejectedExecutionHandler接口来自定义handler。
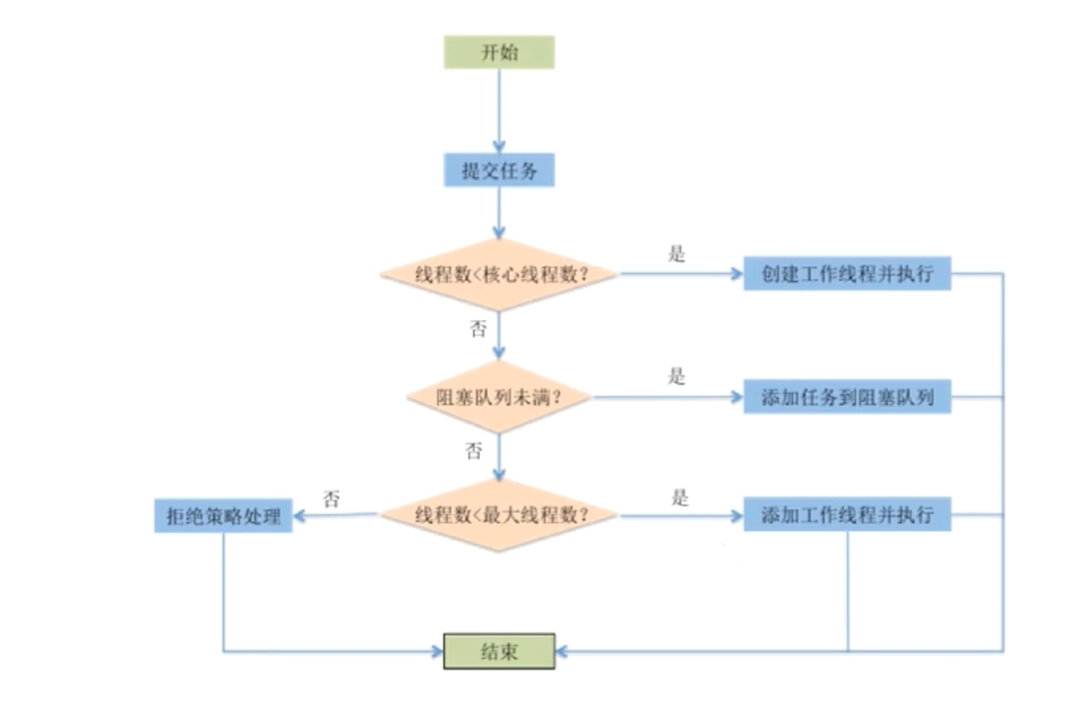
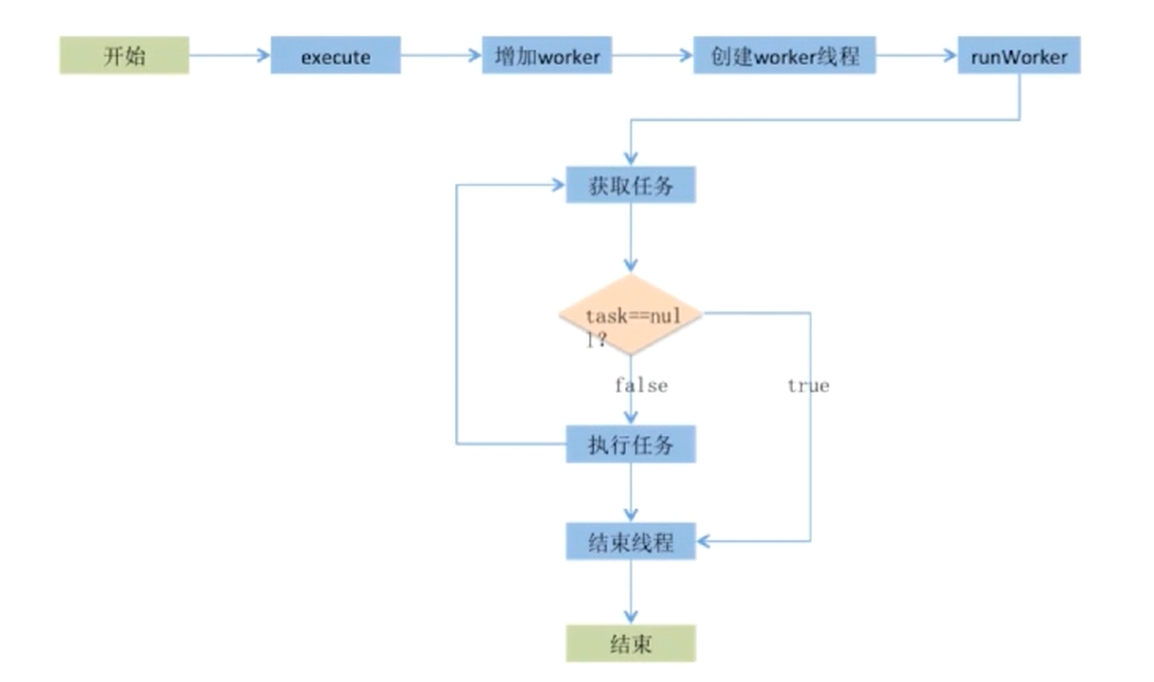
新任务提交 execute 执行后的判断步骤:
- 如果运行的线程数少于
corePoolSize, 则创建新线程来处理任务, 即使线程池的其它线程是空闲的。 - 如果线程池中的线程数量大于等于
corePoolSize且小于maximumPoolSize, 则只有当workQueue满时才会创建新线程去处理任务。 - 如果如果设置的
corePoolSize和maximumPoolSize相同, 则创建线程数的大小是固定的, 这时如果有新任务提交, 若workQueue未满, 则将请求放入workQueue中, 等待有空闲的线程去从workQueue中取任务并处理。 - 如果运行的线程数量大于等于
maximumPoolSize, 这时如果workQueue已经满了, 则通过handler所指定的策略来处理任务。
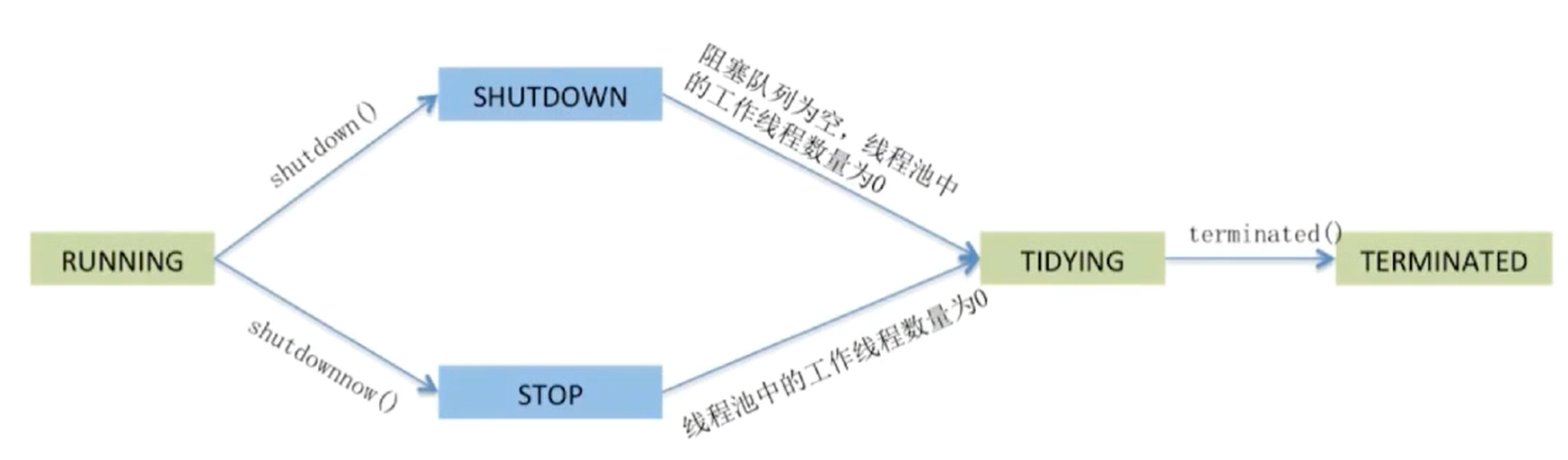
线程池的状态表征
线程池和线程一样也有生命周期。生命周期也是通过状态值来表示的, 线程池的主要作用就是来管理线程。
ThreadPoolExecutor源码中,ctl变量被赋予了双重角色,通过高低位的不同,既可以表示线程池状态,又要表示工作线程数目,这是一个典型的高效优化。
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
// Integer.SIZE = 32 减去3,本质是拿出3位来表示状态
private static final int COUNT_BITS = Integer.SIZE - 3; // 29
// 00100000000000000000000000000000 - 1
// 00011111111111111111111111111111
private static final int COUNT_MASK = (1 << COUNT_BITS) - 1;
// runState is stored in the high-order bits
private static final int RUNNING = -1 << COUNT_BITS;
private static final int SHUTDOWN = 0 << COUNT_BITS;
private static final int STOP = 1 << COUNT_BITS;
private static final int TIDYING = 2 << COUNT_BITS;
private static final int TERMINATED = 3 << COUNT_BITS;
// Packing and unpacking ctl
// 线程状态
private static int runStateOf(int c) { return c & ~COUNT_MASK; }
// 获取活动线程数
private static int workerCountOf(int c) { return c & COUNT_MASK; }
// 获取两者
private static int ctlOf(int rs, int wc) { return rs | wc; }
线程池的五种状态
- RUNNING :能接受新提交的任务, 并且也能够处理阻塞队列中的任务。
- SHUTDOWN :不再接受新提交的任务, 但可以处理存量任务。
- STOP :不再接受新提交的任务, 也不处理存量任务。
- TIDYING :所有的任务都已终止(整理)。
- TERMINATED :
terminated()方法执行后进入该状态。
线程池的大小如何选定
CPU 密集型: 线程数 = 按照核数或者核数+1设定I/O 密集型: 线程数 = CPU核数 * ( 1 + 平均等待时间/平均工作时间 )

博客内容遵循 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 协议
本文永久链接是:https://blog.lgq51233.xyz/2020/09/28/Java%E7%9A%84%E7%BA%BF%E7%A8%8B%E6%B1%A0/