
Spring循环依赖
循环依赖
循环依赖其实就是循环引用,也就是两个或者两个以上的bean互相持有对方,最终形成闭环。比如A依赖于B,B依赖于C,C又依赖于A。
注意,这里是对象的相互依赖关系。循环调用其实就是一个死循环,除非有终结条件。
Spring循环依赖场景
- 构造器的循环依赖。
- 属性的循环依赖。
其中,构造器的循环依赖问题无法解决,只能抛出BeanCurrentlyCreationException异常;解决属性循环依赖,spring采用的是提前暴露对象的方法。
检测循环依赖
检查循环依赖,Bean在创建的时候可以给Bean打标,如果递归调用回来发现正在创建中的话,即说明循环依赖了。(构造器必须是在获取引用之前)。
Spring怎么解决循环依赖
Spring的循环依赖理论基于Java的引用传递,当获得的对象引用时,对象的属性可以延后设置的。
Spring单例对象初始化主要分三步骤:
createBeanInstance实例化 -> populateBean填充属性 -> InitializeBean初始化。
createBeanInstance实例化:实例化,其实也就是调用对象的构造方法实例化对象。populateBean填充属性:填充属性,主要是多bean的依赖属性进行填充。initializeBean:调用spring xml中的init方法。
从步骤可以知道,1和2就是对应的构造器循环依赖和属性循环依赖,让类的创建和属性的填充进行了解耦。
Spring为了解决单例的循环依赖,使用了三级缓存。
singletonObjects:单例对象的cache。earlySingletonObject:提前曝光的单例对象的cache。singletonFactories:单例对象工厂的cache。
在创建bean的时候,首先从cache中判断是否有这个单例的bean,这个缓存就是singletonObjects。
如果获取不到,并且对象正在创建中,就再从earlySingletonObject中获取。
如果还是获取不到且允许从singletonFactories.getObject()获取,就从三级缓存singletonFactories获取,如果获取了,然后从singletonFactories中移除,并放入singletonObjects中,也就是从三级缓存移到一级缓存。
关键在于三级缓存。发生在createBeanInstance之后,也就是说单例对象此时已经被创建出来了(调用了构造器)。这个对象已经被生产了,虽然还不完全(还没进行初始化的第二和第三步),但已经被认出来了(根据对象引用能定位到堆中的对象),而Spring此时将这个对象提前曝光。
这样做的好处是:”A的某field或setter依赖了B的实例对象,同时B的某个field或者setter依赖了A的实例对象”。A完成了初始化第一步,并且提前曝光到singletonObjects中,此时进行初始化第二步,发现依赖B,然后尝试去get(B),发现B还没被create,然后去创建B,B在初始化第一步发现要依赖A,尝试get(A),首先尝试从singletonObjects获取,然后尝试二级缓存earlySingletonObject,最后三级缓存,因为之前A已经提前曝光了,所以可以找到,然后B拿到A之后完成初始化3阶段,完全初始化完成后,将B放入一级缓存singletonObjects,由于B拿到了A对象的引用,所以B也完成了初始化。
所以可以知道,Spring不能解决”A的构造方法中依赖了B的实例对象,同时B的构造方法中依赖了A的实例对象”这类问题。因为加入singletonFactories的前提是执行了构造器,所以构造器的循环没法解决。
基于构造器的循环依赖
Spring容器会将每一个正在创建的Bean标识符放在一个”当前创建Bean池”(singletonsCurrentlyInCreation),Bean标识符在创建过程中一直保持在这个池中,因此如果在创建Bean过程中发现自己在”当前创建Bean池”里时将抛出BeanCurrentlyCreationException异常表示循环依赖,而对于创建完毕的Bean将从”当前创建Bean池”中清除掉。
例如:Spring容器先创建单例A,A依赖B,然后将A放在”当前创建Bean池”中,此时创建B,B依赖C,然后将B放在”当前创建Bean池”中,此时创建C,C又依赖A,但是,此时A已经在池中,所以会报错,因为在池中的Bean都是未初始化完成的,所以会依赖错误。
基于setter属性的循环依赖
测试代码
public class CircleTest {
private final static Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
public static void main(String[] args) throws Exception {
System.out.println(getBean(B.class).getA());
System.out.println(getBean(A.class).getB());
}
private static <T> T getBean(Class<T> beanClass) throws Exception {
String beanName = beanClass.getSimpleName().toLowerCase();
if (singletonObjects.containsKey(beanName)) {
return (T) singletonObjects.get(beanName);
}
// 实例化对象入缓存
Object obj = beanClass.newInstance();
// 放入singletonObjects 缓冲区了,这时候已经被其它对象暴露了
singletonObjects.put(beanName, obj);
// 属性填充补全对象
Field[] fields = obj.getClass().getDeclaredFields();
for (Field field : fields) {
field.setAccessible(true);
Class<?> fieldClass = field.getType();
String fieldBeanName = fieldClass.getSimpleName().toLowerCase();
// 尝试从缓存中获取
field.set(obj, singletonObjects.containsKey(fieldBeanName) ? singletonObjects.get(fieldBeanName) : getBean(fieldClass));
field.setAccessible(false);
}
return (T) obj;
}
}
class A {
private B b;
// ...get/set
}
class B {
private A a;
// ...get/set
}
- 这段代码提供了 A、B 两个类,互相有依赖。但在两个类中的依赖关系使用的是 setter 的方式进行填充,也只有这样才能避免两个类在创建之初不非得强依赖于另外一个对象。
getBean是整个解决循环依赖的核心内容,A 创建后填充属性时依赖 B,那么就去创建 B,在创建 B 开始填充时发现依赖于 A,但此时 A 这个半成品对象已经存放在缓存到singletonObjects中了,所以 B 可以正常创建,再通过递归把 A 也创建完整了。
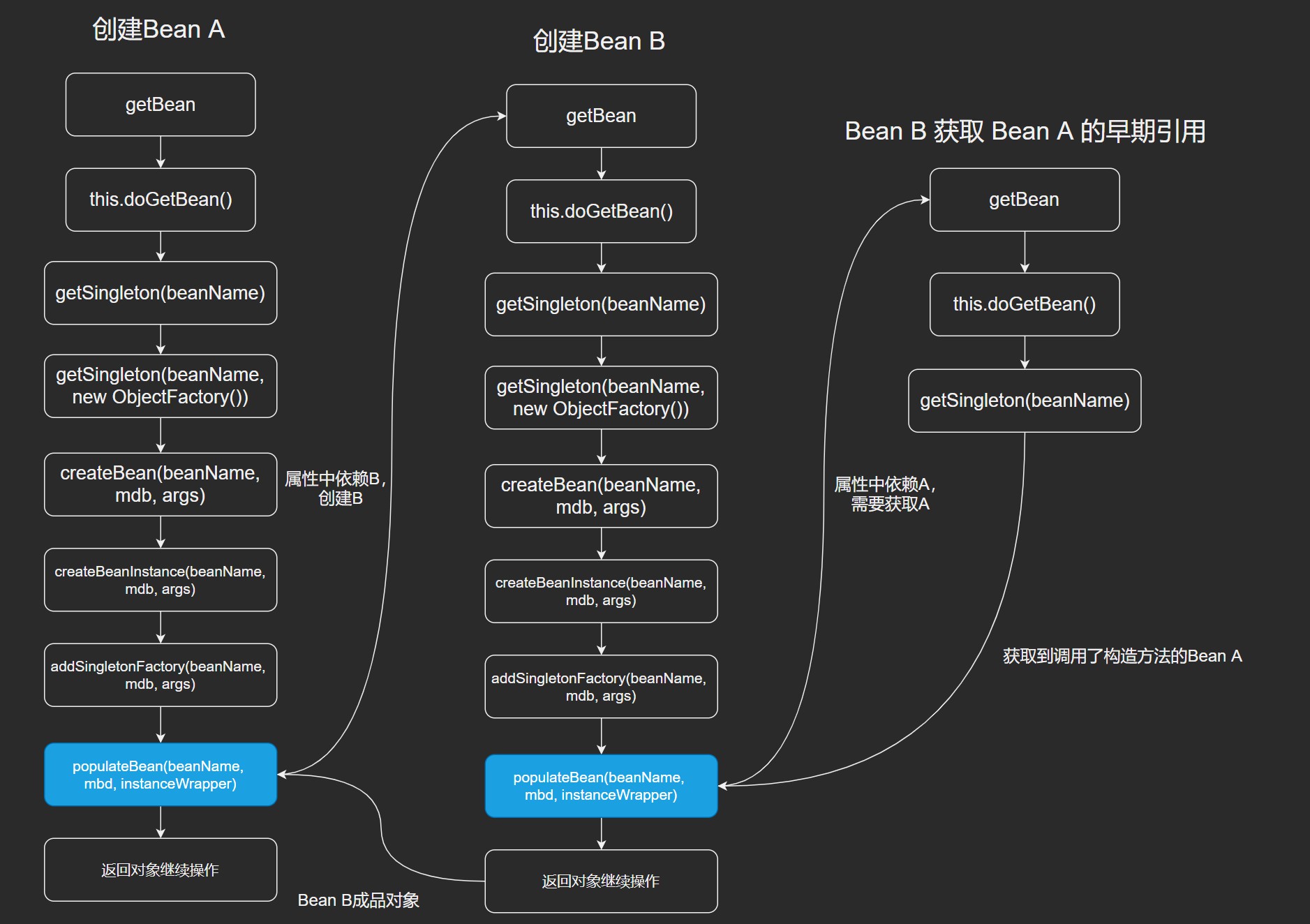
Spring中大致流程如下图
@Test
public void testLife(){
AbstractApplicationContext container = new ClassPathXmlApplicationContext("life.xml");
LifeBean life = (LifeBean) container.getBean("life_prototype");
System.out.println(life);
container.close();
}
org.springframework.beans.factory.support.AbstractBeanFactory
@Override
public <T> T getBean(String name, Class<T> requiredType) throws BeansException {
return doGetBean(name, requiredType, null, false);
}
- 从
getBean进入,之后调用doGetBean方法。 doGetBean有很多不同的重载方法。
protected <T> T doGetBean(
final String name, final Class<T> requiredType, final Object[] args, boolean typeCheckOnly)
throws BeansException {
// 从缓存中获取 bean 实例,三级缓冲策略
Object sharedInstance = getSingleton(beanName);
// mbd.isSingleton() 用于判断 bean 是否是单例模式
if (mbd.isSingleton()) {
// 获取 bean 实例
sharedInstance = getSingleton(beanName, new ObjectFactory<Object>() {
@Override
public Object getObject() throws BeansException {
try {
// 创建 bean 实例,createBean 返回 实例化好的bean
return createBean(beanName, mbd, args);
}
catch (BeansException ex) {
destroySingleton(beanName);
throw ex;
}
}
});
// 后续的处理操作
bean = getObjectForBeanInstance(sharedInstance, name, beanName, mbd);
}
// ...
// 返回 bean 实例
return (T) bean;
}
判断是单例之后,基于ObjectFactory包装的方式创建createBean(),进入后核心逻辑是执行doCreateBean()方法。
org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory的doCreateBean()方法。
protected Object doCreateBean(final String beanName, final RootBeanDefinition mbd, final Object[] args)
throws BeanCreationException {
// 第一步,创建 bean 实例,并将 bean 实例包装到 BeanWrapper 对象中返回
instanceWrapper = createBeanInstance(beanName, mbd, args);
// 添加 bean 工厂对象到 singletonFactories 三级缓存中
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
try {
// 第二步,填充属性,解析依赖关系
populateBean(beanName, mbd, instanceWrapper);
if (exposedObject != null) {
// 第三步
exposedObject = initializeBean(beanName, exposedObject, mbd);
}
}
// 返回 bean 实例
return exposedObject;
}
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (SmartInstantiationAwareBeanPostProcessor bp : getBeanPostProcessorCache().smartInstantiationAware) {
exposedObject = bp.getEarlyBeanReference(exposedObject, beanName);
}
}
return exposedObject;
}
- 在
doCreateBean方法中包括的内容较多,但核心主要是创建实例、加入缓存以及最终进行属性填充,属性填充就是把一个 bean 的各个属性字段涉及到的类填充进去。 createBeanInstance,创建 bean 实例,并将 bean 实例包装到 BeanWrapper 对象中返回。addSingletonFactory,添加 bean 工厂对象到 singletonFactories 缓存中。getEarlyBeanReference,获取原始对象的早期引用,在 getEarlyBeanReference 方法中,会执行 AOP 相关逻辑。若 bean 未被 AOP 拦截,getEarlyBeanReference 原样返回 bean。populateBean,填充属性,解析依赖关系。也就是从这开始去找寻 A 实例中属性 B,紧接着去创建 B 实例,最后在返回回来。
getSingleton的三级缓存
org.springframework.beans.factory.support.AbstractBeanFactory#doGetBean中调用org.springframework.beans.factory.support.DefaultSingletonBeanRegistry#getSingleton(java.lang.String, boolean)。
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
// 从一级缓存 singletonObjects 获取实例,singletonObject 是成品 bean
Object singletonObject = this.singletonObjects.get(beanName);
// 判断 beanName,isSingletonCurrentlyInCreation 对应的 bean 是否在创建中
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
// 尝试从二级缓存 earlySingletonObjects 中获取提前曝光未成品的 bean
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference) {
synchronized (this.singletonObjects) {
// Consistent creation of early reference within full singleton lock
singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null) {
// 三级缓存,获取相应的 bean 工厂
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
// 提前曝光 bean 实例,主要是为了解决AOP循环依赖问题
singletonObject = singletonFactory.getObject();
// 将 singletonObject 放入 earlySingletonObjects 二级缓存中,并从 singletonFactories 缓存中移除
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
}
}
}
}
}
return singletonObject;
}
singletonObjects.get(beanName),从singletonObjects中获取实例,是成品实例。isSingletonCurrentlyInCreation,判断 beanName,isSingletonCurrentlyInCreation 对应的 bean 是否在创建中。allowEarlyReference,从 earlySingletonObjects 中获取提前曝光的未成品的 bean。earlySingletonObjects.put(beanName, singletonObject),提前曝光 bean 实例,解决AOP循环依赖问题。
依赖解析
一级缓存
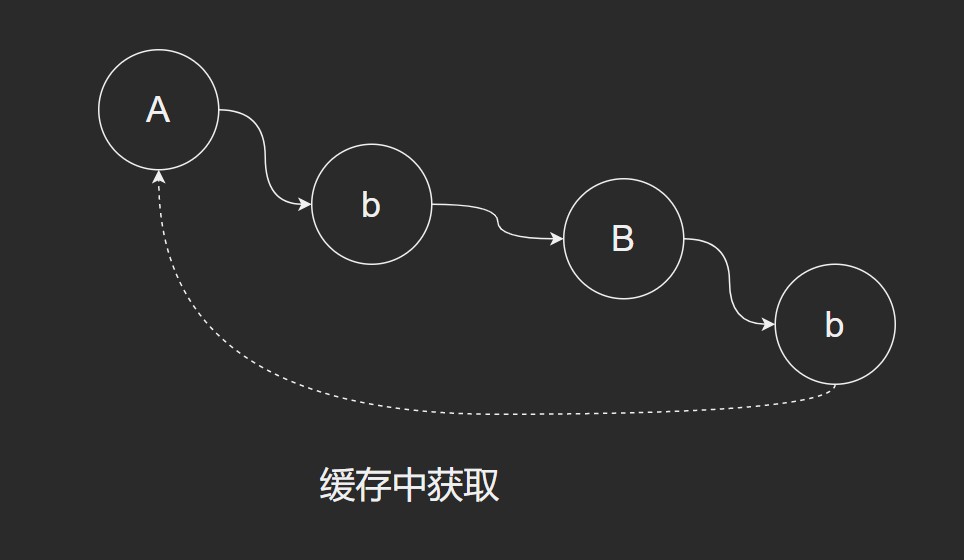
- 一级缓存并不是不能解决循环依赖问题,就像上面的例子一样。
- Spring如果像上面例子那样处理,会变得很麻烦,也可能会出现 NPE 问题。
- 如果按照上图的处理流程,不能解决循环依赖问题。因为 A 的成品需要依赖 B,B的成品创建依赖A,当需要填充B的时候,A还没创建完成,就会出现死循环。
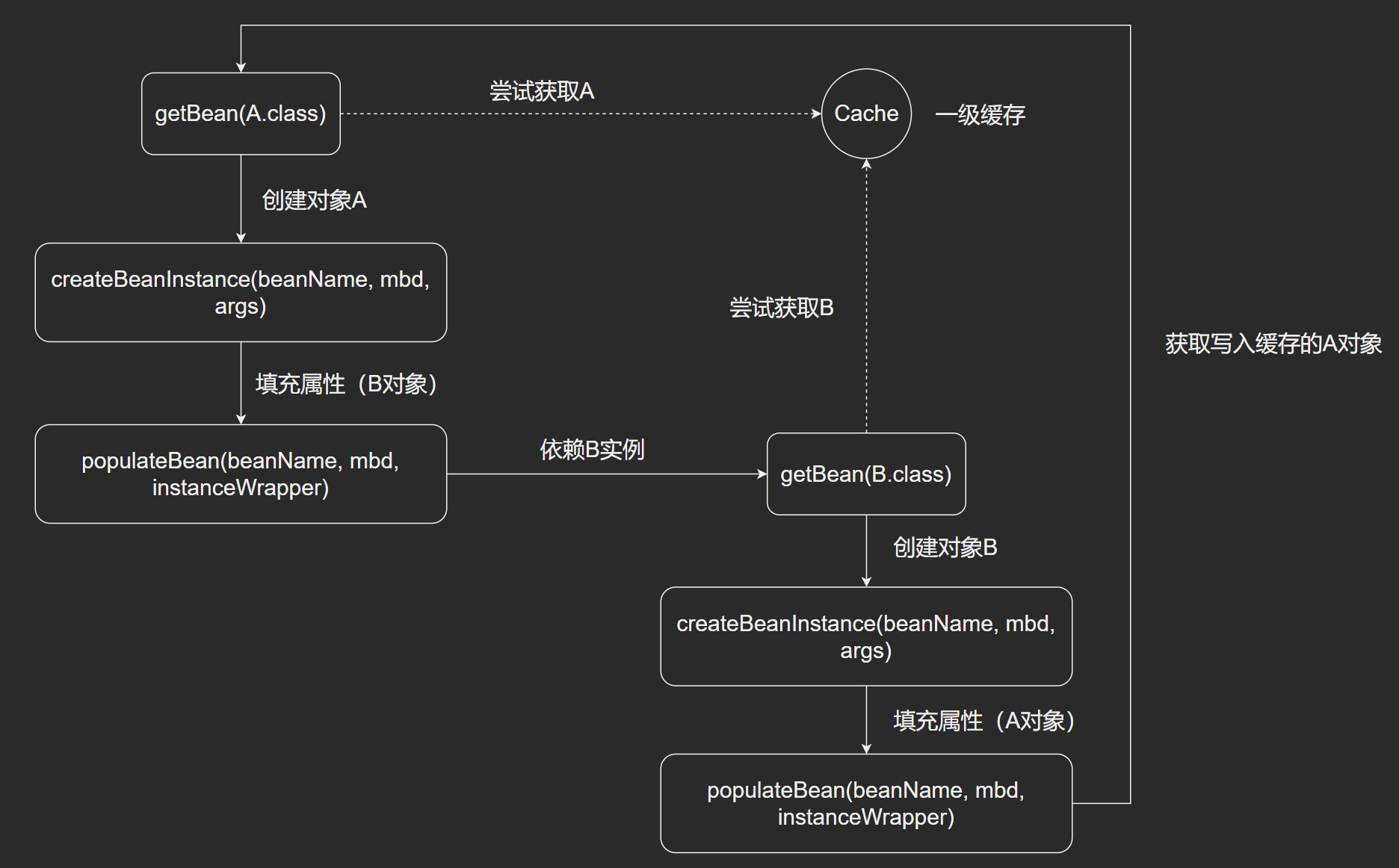
二级缓存
- 二级缓存,一个缓存成品对象,一个缓存半成品对象。
- A在创建半成品对象后放入缓存中,然后填充A对象属性中依赖B。
- 创建B对象,创建半成品放入缓存中,在填充对象的A属性时,可以从半成品缓存中获取,现在B就是一个完整对象了,而接下来就像递归一样A也是一个完整对象了。
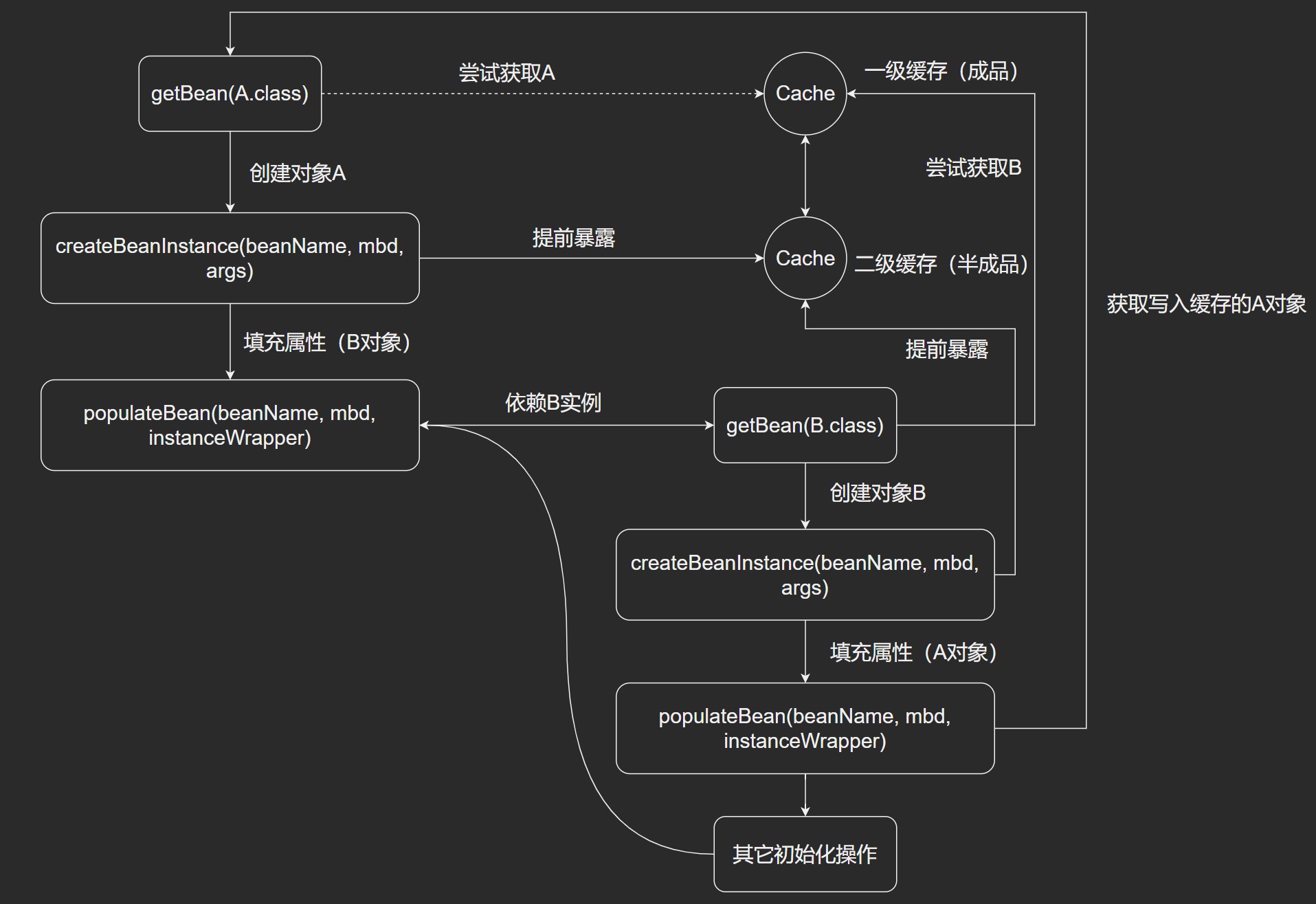
三级缓存
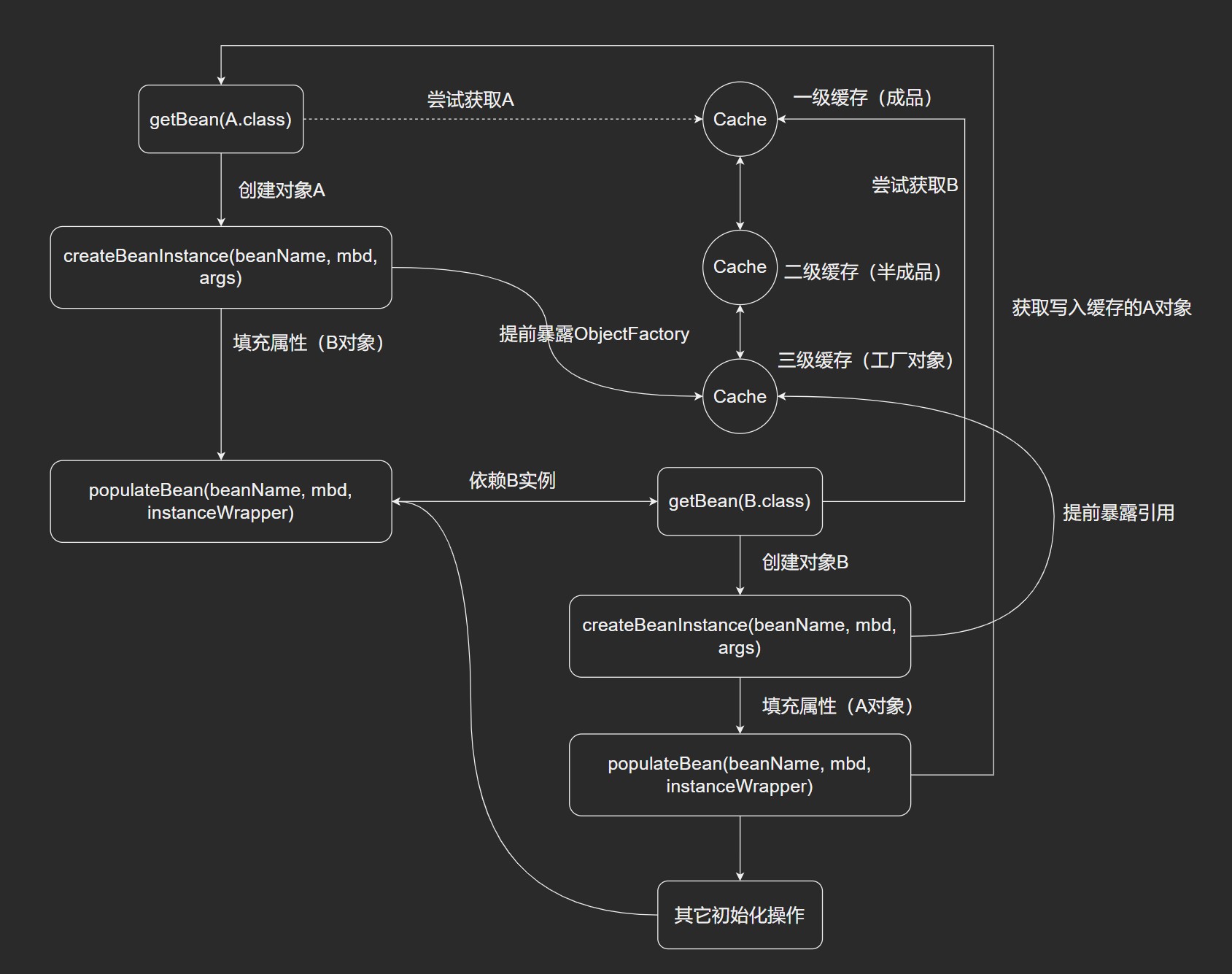
- 二级缓存解决了Spring依赖问题,而三级缓存是为了解决Spring AOP的特性的。AOP本身是对方法的增强,是
ObjectFactory<?>类型的 lambda 表达式,而Spring的原则又不希望此类类型的Bean前置创建,所以放在三级缓存中处理,延迟调用AOP逻辑。 - 三级缓存不是必须的,只不过是在满足Spring自身创建的原则下,是必须的。可以修改Spring源码,提前创建AOP对象保存在缓存中,那么二级缓存也可以解决循环依赖问题。
- 实际,解决循环依赖的核心,在于提前暴露引用对象地址。

博客内容遵循 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 协议
本文永久链接是:https://blog.lgq51233.xyz/2020/09/30/Spring%E5%BE%AA%E7%8E%AF%E4%BE%9D%E8%B5%96/