
Redis基础
分布式设计原则
- 异步解耦(消息队列)
- 幂等一致性(用户请求经过多个子系统, 数据的一致性要得到保证, 就是说要保证用户的同一个操作发起的一次或多次请求, 他们的最终结果是一致的. 主要针对修改和增加.)
- 拆分原则(业务, 功能)
- 融合分布式中间件
- 容错高可用
NoSQL
- Not Only SQL
- 传统项目使用纯数据库
- 为互联网和大数据而生
- 水平(横向)扩展方便
- 高性能读取
- 高可用
- 存数据, 做缓存
分类
- 键值对数据库 Redis Memcache
- 列存储数据库 Hbase Cassandra
- 文档型数据库 MongoDB CouchDB
- 图形数据库 Neo4j FlockDB
分布式缓存
- 提高读数据性能
- 分布式计算领域
- 为数据库降低查询压力
- 跨服务缓存
- 内存式缓存
分布式缓存技术选型
Redis VS Memcache VS Ehcache
Ehcache
NyBatis有使用
优点
- 基于java开发
- 基于JVM缓存
- 简单, 轻巧, 轻便
缺点
- 集群不支持
- 分布式不支持
Memcache
优点
- 简单的
key-value存储 - 内存使用率比较高
- 多核处理, 多线程(redis是单线程的)
缺点
- 无法容灾
- 无法持久化
Redis
- 丰富的数据结构
- 持久化
- 主从同步, 故障转移
- 内存数据库
缺点
- 单线程
- 单核
Redis快的原因
100_000+QPS(Query Per Second, 每秒内查询次数).
- 完全基于内存, 绝大部分请求是存粹的内存操作, 读写不受硬盘I/O的限制, 执行效率高.
- 不需要各种锁的性能消耗。redis的一些数据结构,不是简单的
key-value结构,还有list,hash等结构,如果对这些结构进行细粒度的操作,可能需要加很多锁导致同步开销大大增加。 - 采用单线程模型, 单线程也能处理并发请求, 如果多核也可以启动多实例. 所有操作是原子性的, 不需要考虑并发问题。
- 单线程指主线程是单线程的, 主线程指包括
I/O事件的处理以及I/O对应的相关请求的业务处理, 还负责过期键的处理, 协调集群等等. 这些会被封装成周期性任务, 由主线程处理, 而一个Redis运行时肯定不止一个线程的。例如, 在持久化的时候, 会以子进程或子线程的方式执行. - 正因为采用单线程的设计, 对于客户端的所有读写请求都有一个串行的处理, 因此多个客户端同时对一个键进行写操作时, 也不会有并发问题, 避免的频繁的上下文切换和锁的竞争. 注意: 并发并不是并行!! 并行意味着计算机可以同时执行多个任务, 具备多个计算单元. 而并发IO流, 意味着能够让一个计算单元来处理来自多个客户端流请求. Redis使用单线程配合IO多路复用, 能大幅度地提升性能. 很多时候, CPU不是Redis的瓶颈, 一般都是网络等原因导致。
- 使用I/O多路复用模型, 非阻塞IO。epoll+简单的事件框架。使用单线程来文件轮询描述符,将开,关,读,写都转换成了事件。
- 单线程,多进程集群方案。
采用I/O多路复用函数: epoll/kqueue/evport/select.
Redis单线程优劣势
- 代码更清晰,处理逻辑简单
- 不用考虑锁的问题。不存在加锁和释放锁的操作,也没有死锁导致性能的消耗
- 不存在进程或多线程切换而消耗CPU
Redis对于I/O多路复用算法
- 因地制宜. 需要在多个平台上运行, 同时为了最大化提高执行效率和性能, 会根据编译平台的不同, 选择不同的
I/O多路复用函数作为子模块, 提供给上层统一的接口。 - 优先选择时间复杂度为
O(1)的I/O多路复用函数作为底层实现。 - 以时间复杂度为
O(n)的select作为保底. 因为select会扫描所有FD, 所以时间复杂度比较差。 - 基于React设计模式监听
I/O事件. 当accept,read,write,poll文件事件产生时, 事件监听器就会回调FD绑定的事件处理器。
Redis安装与配置
原生安装方式
# https://redis.io/download
wget https://download.redis.io/releases/redis-6.2.1.tar.gz
tar -zxvf redis-6.2.1.tar.gz
yum install gcc-c++
make && make install
# 在源码包下进入 utils 包找 redis_init_script 脚本
cd utils
# CentOS 设置开机启动
cp redis_init_script /etc/init.d/
# 修改下名字,方便指令启动
mv redis_init_script redis
# 设置开机启动
# redis_init_script 脚本中添加以下内容
# chkconfig: 22345 10 90
# description: Start and Stop redis
chkconfig redis on
# 或者这样
chkconfig --add redis
# 查看是否开机启动
chkconfig --list
# 启动服务
service redis start
# Debian开机启动 使用 systemctl 方式
# 在 /etc/systemd/system 下 新建一个 redis.service , 然后添加以下内容
[Unit]
Description=Redis
After=network.target
[Service]
Type=forking
ExecStart=/usr/local/redis/bin/redis-server /usr/local/redis/redis.conf
ExecReload=/usr/local/redis/bin/redis-server -s reload
ExecStop=/usr/local/redis/bin/redis-server -s stop
PrivateTmp=true
[Install]
WantedBy=multi-user.target
# 重新加载脚本
systemctl daemon-reload
# 设置开机启动
systemctl enable redis.service
# 启动/停止 redis
systemctl start redis.service
systemctl stop redis.service
# Debian开机启动 使用 rc.d 的方式
# 将 redis_init_script 复制到 /etc/init.d 目录下,并改名为 redis_16388
update-rc.d redis_16388 defaults
# 修改配置文件
mkdir /usr/local/redis -p
# 持久化保存的位置
mkdir /usr/local/redis/working -p
cp ../redis.conf /usr/local/redis
cd /usr/local/redis
vim redis.conf
# 修改启动脚本,修改启动指定的配置文件位置
vim redis_init_script
# 启动
redis_init_script start
Docker方式安装
# 查找要拉取的镜像
docker search redis
# 拉取镜像
docker pull redis:7.0.2
# 创建容器
# 把 配置文件 和 持久化目录 挂载出来
# --restart=always 是否开机启动
# --log-opt 日志操作
# -d 后台方式启动redis
# --appendonly 使用 AOF 持久化
# 注意:配置文件的文件夹先配置好; 还有配置文件 daemonize 的后台运行配置要设置为 no 或者注释掉,要不会启动完,docker就关闭了
docker run --log-opt max-size=100m --log-opt max-file=2 -p 6379:6379 --name redis7.0.2 \
-v /mnt/f/WorkSpace/ServerSoft/redis/redis.conf:/etc/redis/redis.conf \
-v /mnt/f/WorkSpace/ServerSoft/redis/data:/data -d redis:7.0.2 \
redis-server /etc/redis/redis.conf \
--appendonly yes --requirepass lgq51233
# 进入容器内
docker exec -it contianerId /bin/bash
Redis的基本配置
# 绑定的ip,默认是 127.0.0.1,只能本机访问,要想外网访问,使用 0.0.0.0
bind 0.0.0.0
# 绑定的端口号
port 6379
# 密码设置
requirepass lgq2020
# 客户端连接超时时间,0表示关闭
timeout 0
# 开启密码保护
protected-mode yes
# 是否后台运行(守护进程),默认是no
daemonize yes
# 守护进程PID文件,默认路径是 /var/run/redis.pid
pidfile /var/run/redis_6379.pid
# 日志级别
# debug (a lot of information, useful for development/testing)
# verbose (many rarely useful info, but not a mess like the debug level)
# notice (moderately verbose, what you want in production probably)
# warning (only very important / critical messages are logged)
loglevel notice
# 日志文件路径,默认 "" ,表示日志不输出到文件
logfile ""
# redis 数据库个数,默认16个
databases 16
# 是否压缩rdb,一般关闭,降低cpu占用
rdbcompression yes
# 如果想关闭rdb快照注释 save 行就可以了
# 如果想删除之前配置的save点,可以这样写
save ""
# 至少一个key发生改变,才触发快照
# save <seconds> <changes>
# 在 900s 以内, 有一条key改变就触发快照
save 900 1
# 在 300s 以内, 有10条写入就会产生快照
save 300 10
# 在 60s 以内 10000 条写入就进行备份
save 60 10000
# RDB文件名称
dbfilename dump.rdb
# 是否开启 AOF 开启
appendonly yes
# aof 持久化文件名
appendfilename "appendonly.aof"
# aof 同步策略
appendfsync everysec
# 工作目录 持久化保存的位置(包括aof)
dir /usr/local/redis/working
Redis客户端使用
路径/usr/local/bin/redis-cli
# redis-cli
reids-cli -h 127.0.0.1 -p 6377
[linux-devlgq bin]
127.0.0.1:6379> set name lgq
(error) NOAUTH Authentication required.
127.0.0.1:6379> auth password
OK
127.0.0.1:6379>
# 查看当前redis是否还活着
redis-cli -a password ping
# 停止
redis_init_script stop
redis-cli -a password shutdown
Redis的数据类型
String
最基本的数据类型, 二进制安全, 可以包含任何数据, 比如: jpg图片, 序列化的对象. 最大能存储512mb. 底层是动态字符串sdshdr。
keys *
# 匹配列举
keys l*
keys *q
set name lgq
get name
del name
type name
# 如果不存在就创建, 存在的话就不进行操作
setnx sex man
# 查看存活时间 -1 无限大
ttl name
# 设置过期时间
expire name 30
# 或者用set
set age 18 ex 20
# 追加 会返回长度
append name 233
# 查看长度
strlen name
# 累加 步长为1
incr age
# 累减 -1
decr age
# 累加指定数值
incrby age 10
# 累减指定数值
decrby age 10
# 截取 下标从0开始, -1表示截取到最后
getrange name 1 -1
# 替换 从下标1开始替换
setrange name 1 abc
# 多个设值
mset k1 v1 k2 v2
# 存在的话就不进行更改
msetns k1 v1 k2 v2
# 多个获取
mget k1 k2 name
# 切换数据库(数据是独立的, 不共享)
select 1
# 清空当前数据库数据
flushdb
# 清空所有
flushall
Hash
基于哈希表实现,稀疏,无序的。
hset user name lgq
hget user name
# 设置多个
hmset user age 18 sex man
# 指定key获取
hmget user name age sex
# 获取所有
hgetall user
# 包含多少个属性
hlen user
# 列举属性
hkeys user
# 列举所有值
hvals user
hincrby user age 10
hincrbyfloat user age 0.2
# 判断某个属性是否存在
hexists user age
# 删除 注意要列举要删除的属性
hdel user name
List
顺序看插入的方向和顺序。
- 结构:
LinkedList,双向链表 lpush/rpush/lpop/rpoplrange(时间复杂度,O(S+N))lindex(first/last, 随机获取)
# 是可以放重复数据的
# 创建列表 left 从左边将数据放入 pig是最先放进去的, 下标是最大
# [duck, chicken, sheep, cow, pig]
lpush list1 pig cow sheep chicken duck
# 查看列表
lrange list1 0 -1
# right 从右边将数据放入
# [pig, cow, cheep, chicken, duck]
rpsuh list2 pig cow sheep chicken duck
lrange list2 0 -1
# 取值 取出来就没有了 左侧弹出 duck
lpop list1
# 右侧弹出 pig
rpop list1
# 长度
llen list1
# 根据下标获取值 下标从0开始
lindex list1 0
# 设值 list index value
lset list1 1 duck
# 在前面插入数据
linsert list1 before cow cheep
# 在后面插入数据
linsert list1 after cow pig
# 移除元素 个数
lrem list1 1 pig
# 截取 start stop 包头包尾 会替换原有的
ltrim list1 1 3
Set
无序,不允许重复元素。
# 没有重复的数据 重复的数据会剔除 去重
sadd animal duck pig sheep dog sheep pig
smembers animal
# 查看集合的长度
scard animal
# 判断值是否存在
ismember animal pig
# 移除元素
srem animal dog
# 出栈 count 弹出个数
spop set 1
# 随机获取内容 count 个数
srandmember animal 2
# 移动 source destination member
smove animal animal2 10
# 差集 set1中的内容, 在set2没有的内容
sdiff set1 set2
# 交集 两者都有的内容
sinter set1 set2
# 并集
sunion set1 set2
Zset
实现: 跳表. 链表, 有序的, 插上之后看概率是否向上放. 时间复杂度都是O(logn), 和二叉搜索树是一样的. 写操作少(最多2次), 都是比较, 所以是单向链表, 适合在高并发下工作的数据结构。
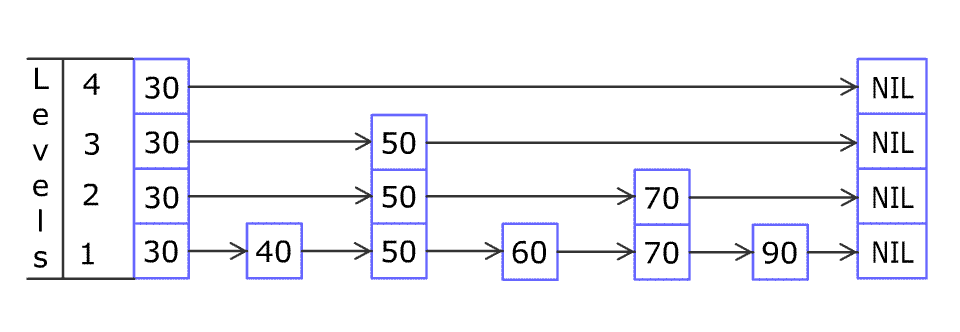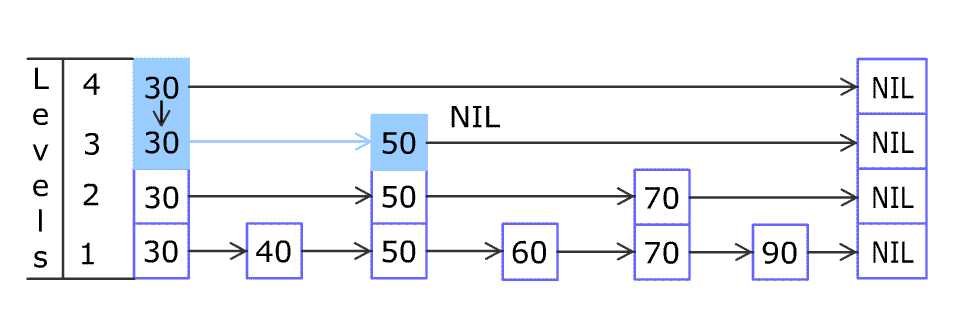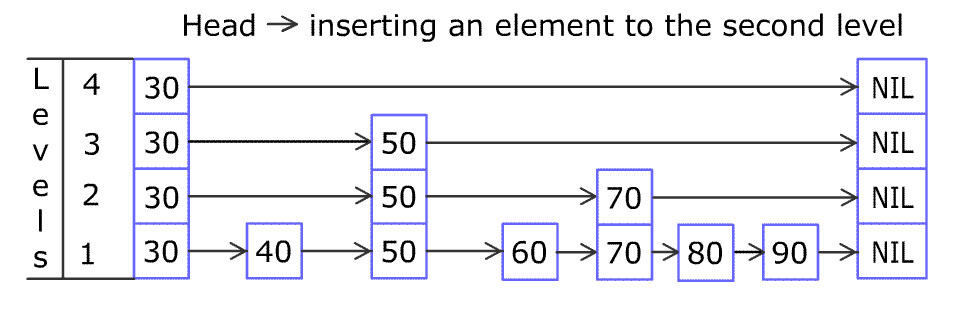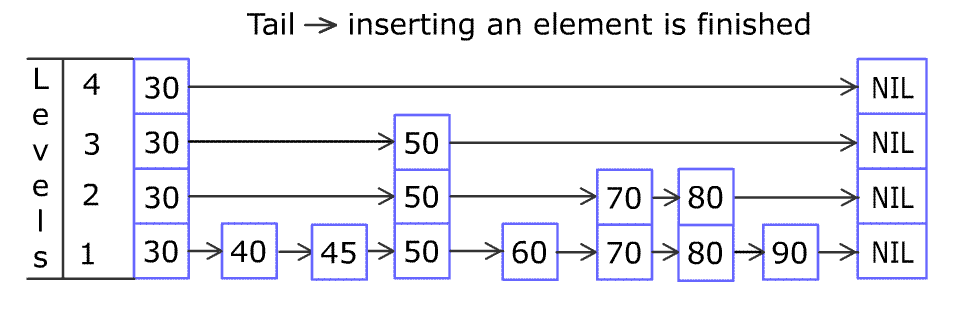
# 有序的set sorted set
# zset 每个member都有一个score
# 创建
zdd zset 10 duck 20 pig 30 chicken 40 sheep 50 beff
# 查看
zrange zset 0 -1
zrange zset 0 -1 withscores
# 添加新数据后会根据score排序
zadd zset 25 dog 35 cow
# 获取beff的下标位置
zrank zset beff
# 获取beff的分数
zscore zset beff
# 获取元素个数
zcard zset
# 在分数范围计算元素个数 min max 大于等于 小于等于
zcount zset 10 20
# 列举分数范围计算元素
zrangebyscore zset 20 40
zrangebyscore zset 20 40 withscores
# 小于40 (表示不包括
zrangebyscore zset 20 (40
# 限定范围后再限定结果集
zrangebyscore zset 20 (40 limit 1 2
# 移除
zrem zset pig beff
其它类型
HyperLogLog: 用于计数的.GEO(Group on Earth Observations) : 用于支持存储地理位置信息的.
多路复用器, 阻塞与非阻塞
伪异步线程模型
多路复用, 同步的, 非阻塞模式
Redis线程模型
类比
Redis的单线程
如果从网络模型角度看,在Redis6.0之前,就是单线程的;如果从整个Redis来看,否定的,在Redis4.0之后引入多线程了。
所以讨论这个问题,要划分两个重要节点
- Redis v4.0:引入多线程处理异步任务
- Redis v6.0:在网络模型实现IO多线程
单线程事件循环
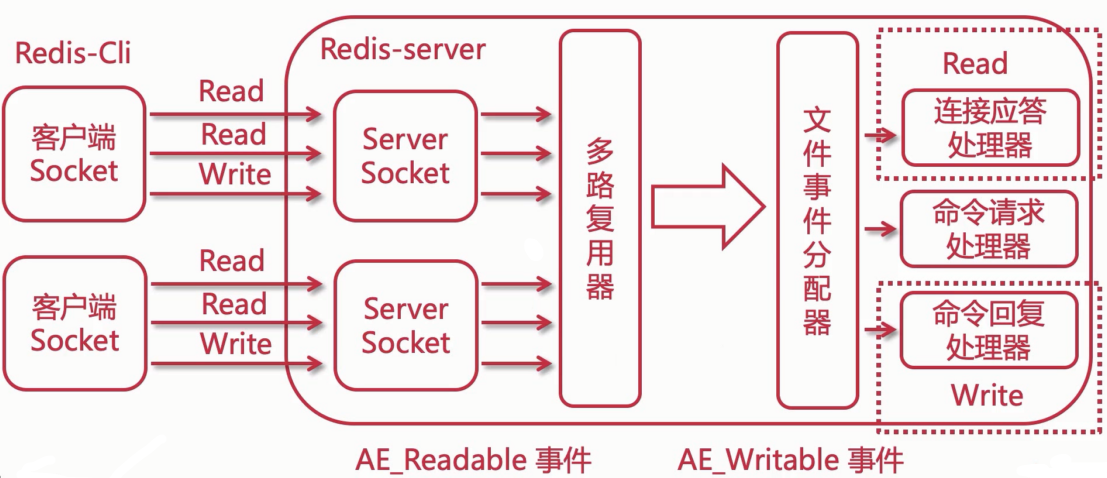
在Redis6.0之前,Redis核心模型一直都是典型的 Reactor模型:利用epoll/kqueue/evport/select等多路复用技术,在单线程的事件循环中不断处理事件(客户端请求),最后回写响应数据给客户端。
client:客户端对象。Redis是经典的CS架构,客户端通过socket与服务端建立网络通道然后发送命令,服务端执行命令并回复。使用结构体client存储客户端的所有相关信息,包含封装的套接字连接--*conn,当前选择的数据库指针--*db,读入缓冲区--querybuf,写出缓冲区--buf,写出数据链表--reply。aeApiPoll:IO多路复用API,基于epoll_wait/select/kevent等系统调用的封装,监听等待读写事件触发,然后处理,是事件循环(Event Loop)的核心函数。acceptTcpHandler:连接应答处理器。底层使用系统调用accept接受来自客户端的新连接,并为新连接注册绑定命令读取处理器,以备后续处理新的客户端TCP连接。readQueryFromClient:命令读取处理器。解析并执行客户端的请求命令。beforeSleep:事件循环进入aeApiPoll等待事件到了之前执行的函数,其中包含一欸写日常的任务,比如把client#buff或者client#rely中的响应写回到客户端,持久化AOF缓冲区的数据到磁盘,相应的还有一个afterSleep函数,在aeApiPoll之后执行。sendReplyToClient:命令回复处理器。当一次事件循环之后写出缓冲区中还有数据残留,这个处理器会被注册绑定到相应的连接上,等连接触发写就绪事件时,它会写出缓冲区剩余的数据回写到客户端。
AE是Redis内部实现的高性能事件库。
客户端与Redis工作原理
- Redis服务器启动,开启主线程事件循环(Event Loop)。注册
acceptTcpHandler连接应答器到用户配置监听端口的对应文件描述符,等待新连接到来。 - 客户端和服务器建立网络连接。
acceptTcpHandler被调用,主线程使用AE的API将readQueryFromClient命令读取处理器绑定到新连接对应的文件描述符上,并初始化一个client绑定这个客户端连接。- 客户端发送请求命令,触发读就绪事件(AE_READABLE),主线程调用
readQueryFromClient通过socket读取客户端发送过来的命令存入client#querybuf读入缓冲区。 - 接着调用
processInputBuffer,再使用processInlineBuffer或者processMultibulkBuffer根据Redis协议解析命令,最后调用processCommand执行命令。 - 根据请求命令类型(set,get,del,exec等),分配相应的命令请求处理器去执行,最后调用
addReply函数族的一系列函数将响应数据写到对应client的写出缓冲区,client#buf或者client#reply,client#buf是首选的写出缓冲区,固定大小16kb,一般来说足够了,但是如果客户端在时间窗口内需要响应的数据非常大,则会自动切换到client#reply链表上,使用链表理论上能够保存无限大的数据(受限于机器的物理内存),最后把client添加进一个LIFO队列clients_pending_write。 - 在事件循环中,主线程执行
beforeSleep–>handleClientsWithPendingWrites,遍历clients_pending_write队列,调用writeToClient把client把client的写出缓冲区里的数据回写到客户端,如果缓冲区还有遗留数据,则注册sendReplyToClient命令回复处理器到该连接的写就绪事件(AE_WRITABLE),等待客户端可写时在事件循环中再继续回写残余的响应数据。
发布与订阅
基于消息做的发布与订阅,实现异步队列。
发送者(pub)发送消息,订阅者(sub)接收消息。- 订阅者可以订阅任意数量的频道。
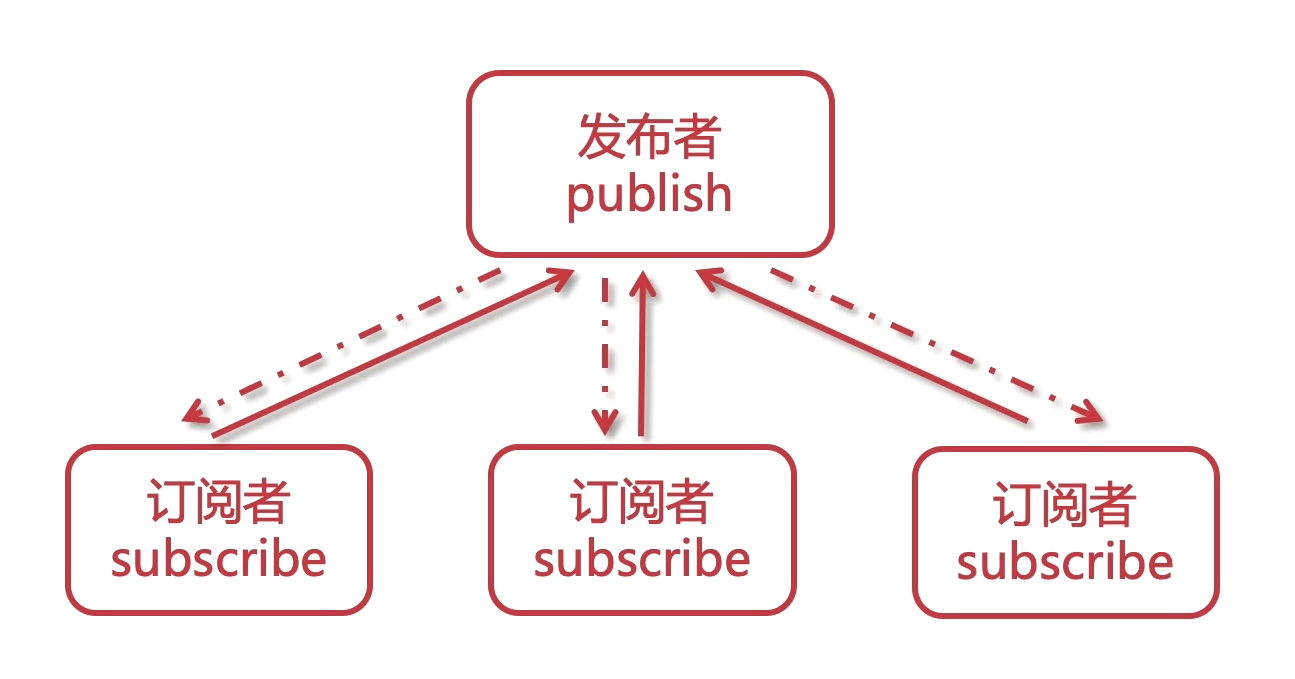
# 订阅
subscribe food lgq-bigdata lgq-frontend lgq-backend
# 发布
publish food duck
# 批量订阅
psubscribe lgq-*
缺点 : 消息的发布是无状态的, 无法保证可达.
生产者与消费者
生产者/消费者模型实现异步队列,使用 List 作为队列,RPUSH 生产消息,LOOP 消费消息。
# 生产
rpush testlist aaa
rpush testlist bbb
rpush testlist ccc
# 消费
lpop testlist
缺点 : 没有等待队列里是否有元素就直接消费, match。生产者和消费者并没有协作。
弥补 : 可以通过在应用层引入 Sleep 机制去调用 LPOP 重试。
BLPOP key [key...] timeout : 阻塞直到队列有消息或者超时.
缺点 : 只能供一个消费者消费。
Redis持久化
如果服务器开启了AOF持久化功能,服务器会优先使用AOF文件还原数据。只有关闭了AOF持久化功能,服务器才会使用RDB文件还原数据。
RDB
persistence performs point-in-time snapshots of your dataset at specified intervals. 每隔一段时间, 把内存中的数据写入磁盘的临时文件, 作为快照, 恢复的时候把快照文件读进内存.如果宕机重启, 那么内存里的数据肯定会没有的, 那重启redis后, 则会恢复,属于冷备份。
优势:
- 每隔一段时间备份, 全量备份.
- 灾备简单, 可以远程传输.
- 子进程备份的时候, 主进程不会有任何io操作(不会有写入修改或删除), 保证备份数据的完整性.
- 相对于AOF来说, 当有更大的文件的时候可以快速重启恢复
劣势:
- 发生故障后, 有可能会丢失最后一次备份的数据
- 子进程所占用的内存比会和父进程的一模一样, 会造成cpu负担
- 由于定时全量备份是重量级操作, 所以对于实时备份, 就无法处理了
相关配置
# 在 900s 以内, 有一条key改变就触发快照
save 900 1
# 在 300s 以内, 有10条写入就会产生快照
save 300 10
# 在 60s 以内 10000 条写入就进行备份
save 60 10000
# 空字符串 禁用 rdb 配置
# 或者 注释掉也会禁用 rdb 配置
save ""
# 保存的时候发生错误就停止写入操作, 如果no可能会造成数据的不一致
stop-writes-on-bgsave-error yes
# 压缩模式 建议设置为 no, redis本身就是 cpu 密集型服务器, 再开启压缩会带来cpu额外的消耗, cpu比硬盘更值钱
rdbcompression yes
# 校验规则
rdbchecksum yes
# RDB持久化文件名
dbfilename dump.rdb
# 持久化文件存储目录
dir ./usr/local/redis/
相关指令
#### Redis CLI 操作 RDB
# 获取 redis 的工作目录
config get dir
# 备份
save
# 后台备份
bgsave
# 查看最后一次备份时间
lastsave
# 基于某个时间点的全量备份
mv dump.rdb dumpxxxx.rdb
# 直接在cli客户端修改
config set appendonly yes
RDB文件格式
是一个经过压缩的二进制文件,默认文件名是:dump.rdb,由多个部分组成。
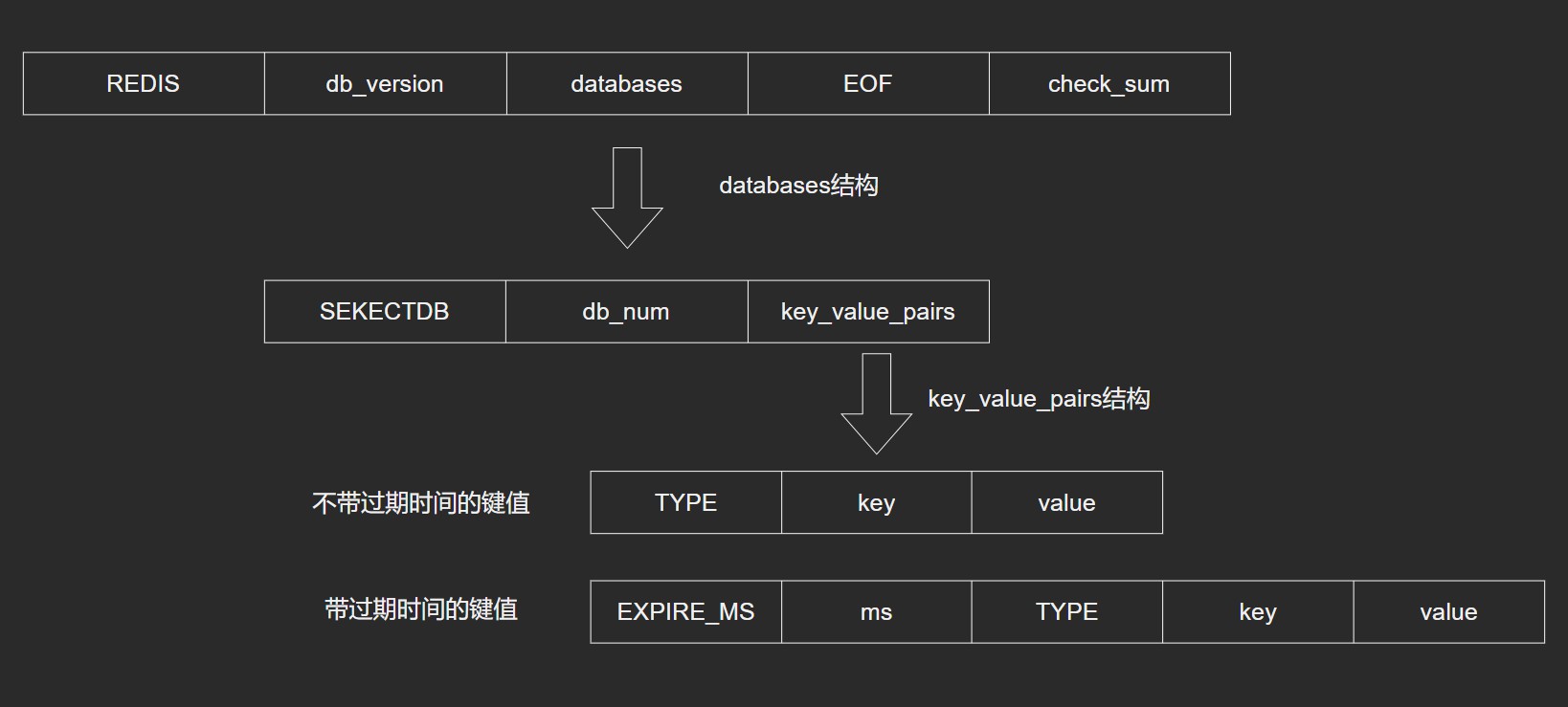
触发RDB持久化的方式
- 自动创建,根据
redis.conf配置里的SAVE m n定时触发(用的是BGSAVE) - 主从复制时, 主节点自动触发
- 执行
debug reload - 执行
shutdown且没有开启AOP持久化 - 执行
save指令,会阻塞请求 - 执行
bgsave指令,不会阻塞请求
BGSAVE 原理
- 检查
AOF/RDB子进程是否存在, 如果存在就返回错误. - 触发持久化, 调用
rdbSaveBackground. fork()创建子进程.
系统调用 fork() : 创建进程(创建一个基本和原进程一样的进程), 实现 Copy-on-Write . 子父进程共享相同的物理页面.
Copy-on-Write 如果多个调用者同时要求相同资源(如内存或磁盘上的数据存储), 他们会共同获取相同的指针指向相同的资源, 直到某个调用者试图修改资源的内容时, 系统才会真正复制一份专用副本给调用者, 而其他调用者所看到的最初资源仍然保存不变.
AOF
属于热备份。
- 以日志的形式记录用户请求的写操作。读操作不会记录,因为写操作才会存数据.
- 文件以追加的形式名,而不是修改的形式。
- redis的AOF恢复其实就是把追加的文件从开始到结尾读取执行写操作。
优势
- AOF更加耐用,可以以秒级别为单位备份, 如果发生问题,也只会丢失最后一秒的数据,大大增加了可靠性和数据完整性。
- 以log日志形式追加,如果磁盘满了,会执行
redis-check-aof工具。 - 当数据太大的时候,redis可以后台自动重写AOF。当redis继续把日志追加到老的文件去时,重写也是非常安全的,不会影响客户端操作。
- AOF日志包含所有写操作,会更加便于redis的解析恢复。
劣势
- 相同的数据, 同一份数据, AOF比RDB大
- 针对不同的同步机制, AOF会比RDB慢, 因为AOF每秒都会做写操作, 这样相对RDB来说就略低.每备份fsync没什么问题, 但是每次写入就做一次备份sync的话, 那么redis的性能就会下降.
- AOF发生过bug, 就是数据恢复的时候数据不完整, 这样显得AOF会比较脆弱, 容易出bug, 因为AOF没有RDB那么简单, 但是为了防止这样情况发生, AOF就不会根据旧的指令去重构, 而是根据当时缓存中存在的指令去做重构, 这样就更加健壮和可靠了.
相关配置
# AOF 开启
appendonly yes
# 配置写入方式
# appendfsync always 一旦发生变化就写入(fsync)
appendfsync everysec # 每隔 1 秒就写入
# appendfsync no # 由操作系统来决定, 等缓冲区(aof_buf)填满再写入
# AOF持久化文件名
appendfilename "appendonly.aof"
# 是否在执行重写时不同步数据到AOF文件
no-appendfsync-on-rewrite no
# 触发AOF文件执行重写的增长率
auto-aof-rewrite-percentage 100
# 触发AOF文件执行重写的最小size
auto-aof-rewrite-min-size 64mb
# redis在恢复时,会忽略最后一条可能存在问题的指令
aof-load-truncated yes
# 是否打开混合持久化
aof-use-rdb-preamble yes
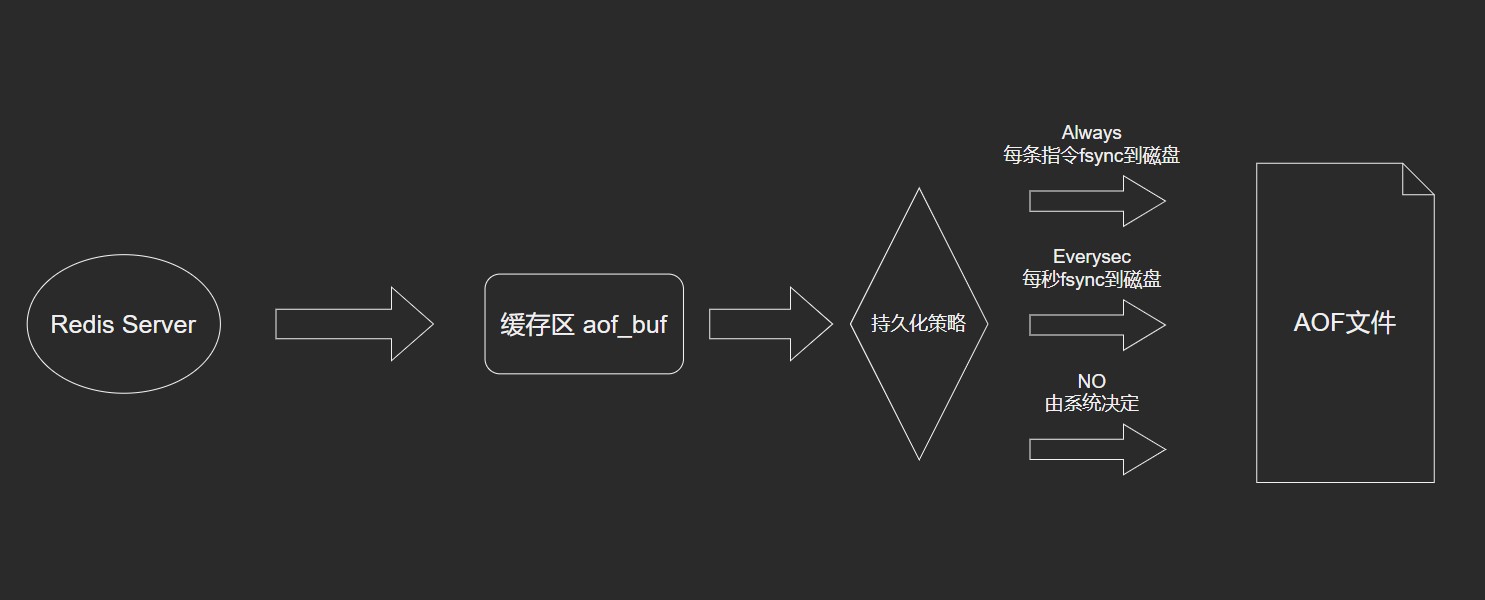
AOF实现
append命令追加:当AOF持久化功能处于打开状态时,服务器执行完一个写命令,被执行的命令会被追加到aof_buf缓冲区的末尾。- 文件写入和
sync:Redis的服务器进程是一个事件循环,事件处理器负责接收客户端的命令请求以及向客户端发送命令回复。当执行了append命令追加后,服务器会调用flushAppendOnlyFile函数判断是否需要将AOF缓冲区的内容写入和保存到AOF文件。
AOF重写
日志重写可以有效缓解AOF文件大小不断增大的问题, 可以使用 bgrewrite 触发。生成一个不保存任何浪费空间的冗余命令新的AOF文件,且新AOF保存数据库状态一样。
新的AOF文件是通过读取数据库中的键值对来实现的,程序无须对现有的AOF文件进行读入,分析,或者写入操作。
Redis 2.4 可以通过配置自动触发 AOF 重写,触发参数 auto-aof-rewrite-percentage (触发AOF文件执行重写的增长率) 以及auto-aof-rewrite-min-size (触发AOF文件执行重写的最小尺寸)。
- 调用
fork(), 创建一个子进程来进行AOF重写。
- 子进程进行AOF重写期间,服务器进程可以继续处理命令请求。
- 子进程带有服务器进程的数据副本,保证了数据的安全性。
2.子进程把新的AOF写到一个临时文件里, 依赖数据库中的键值,不依赖原来的AOF文件。
3. 主进程持续将新的变动同时写到AOF重写缓存区和旧的AOF文件里。
4. 主进程获取子进程重写AOF的完成信号, 往新AOF同步增量变动。
5. 使用新的AOF文件替换掉旧的AOF文件。
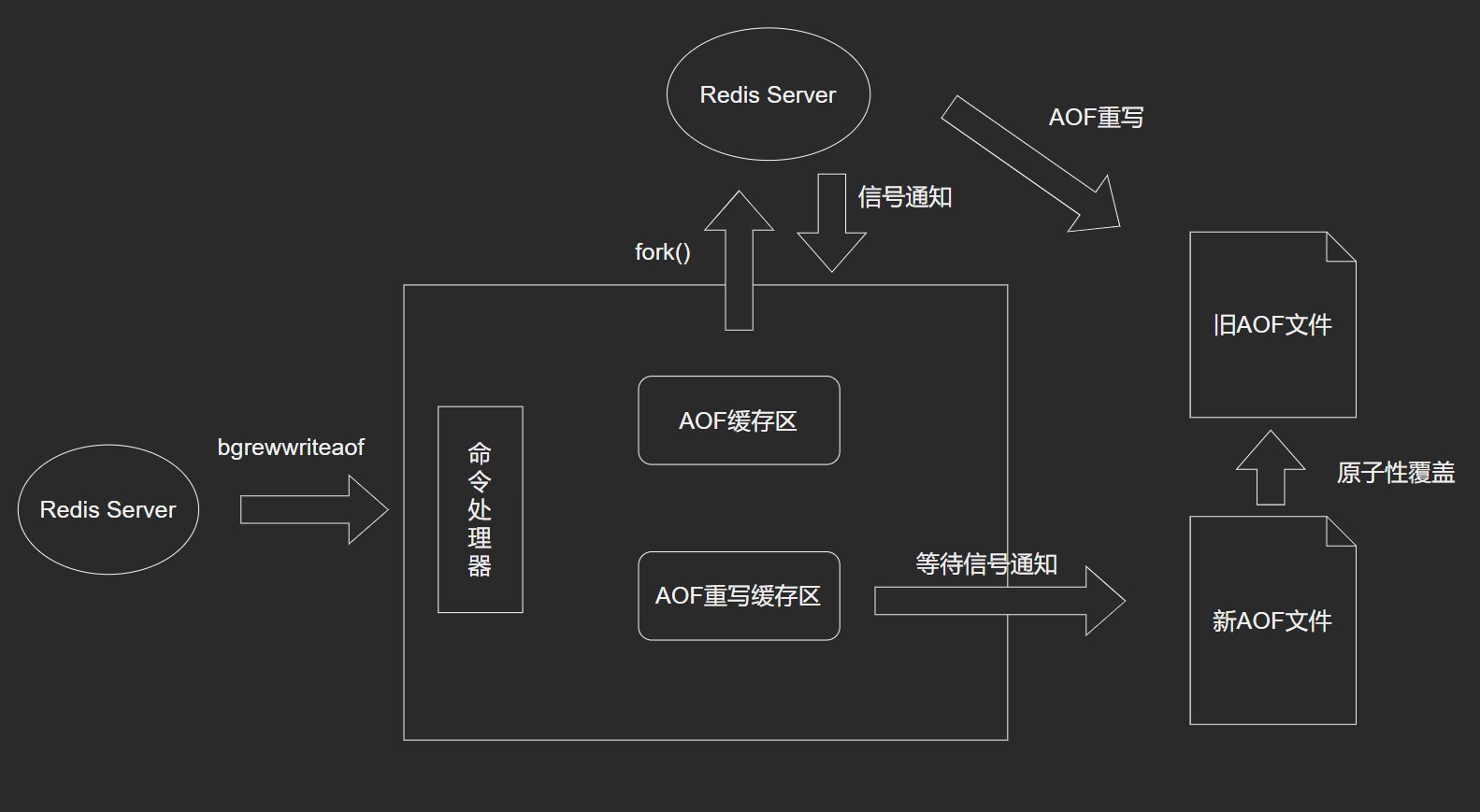
AOF重写作用
- 减少磁盘占用量
- 加速数据恢复
Redis主从架构
Redis为了解决单点数据库问题,会把数据复制多个副本部署到其他节点上,通过复制,实现Redis的高可用性,实现对数据的冗余备份,保证数据和服务的高度可靠性。水平(横向)扩展, 也叫做读写分离架构.
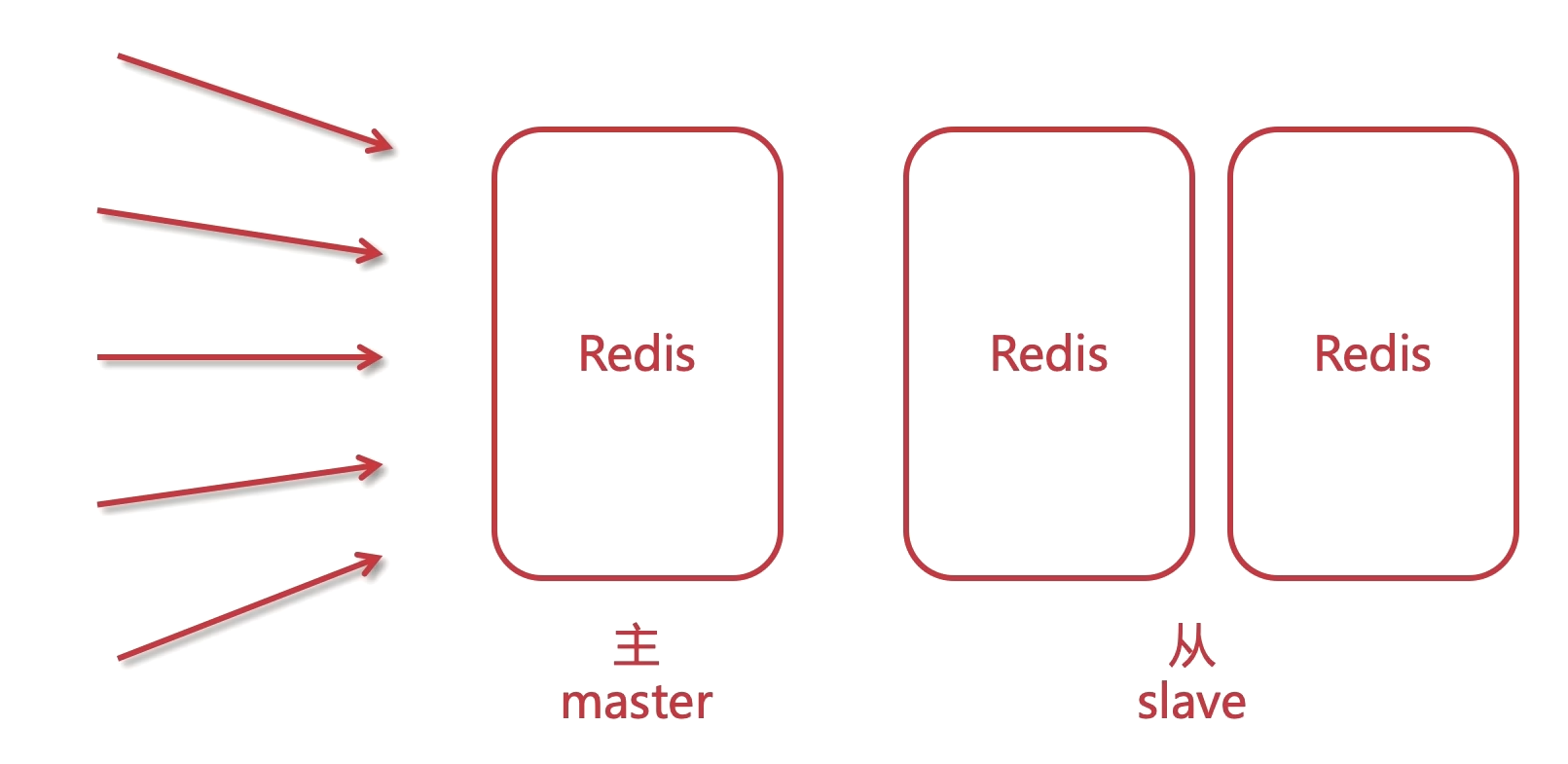
主从原理
初始化(全量的同步)->有写的请求会同步(增量同步), 如果Slave途中宕机了, Master会有记录, 一旦Slave恢复了, 也会把缺失的信息同步过去
注意:Master必须开启持久化.
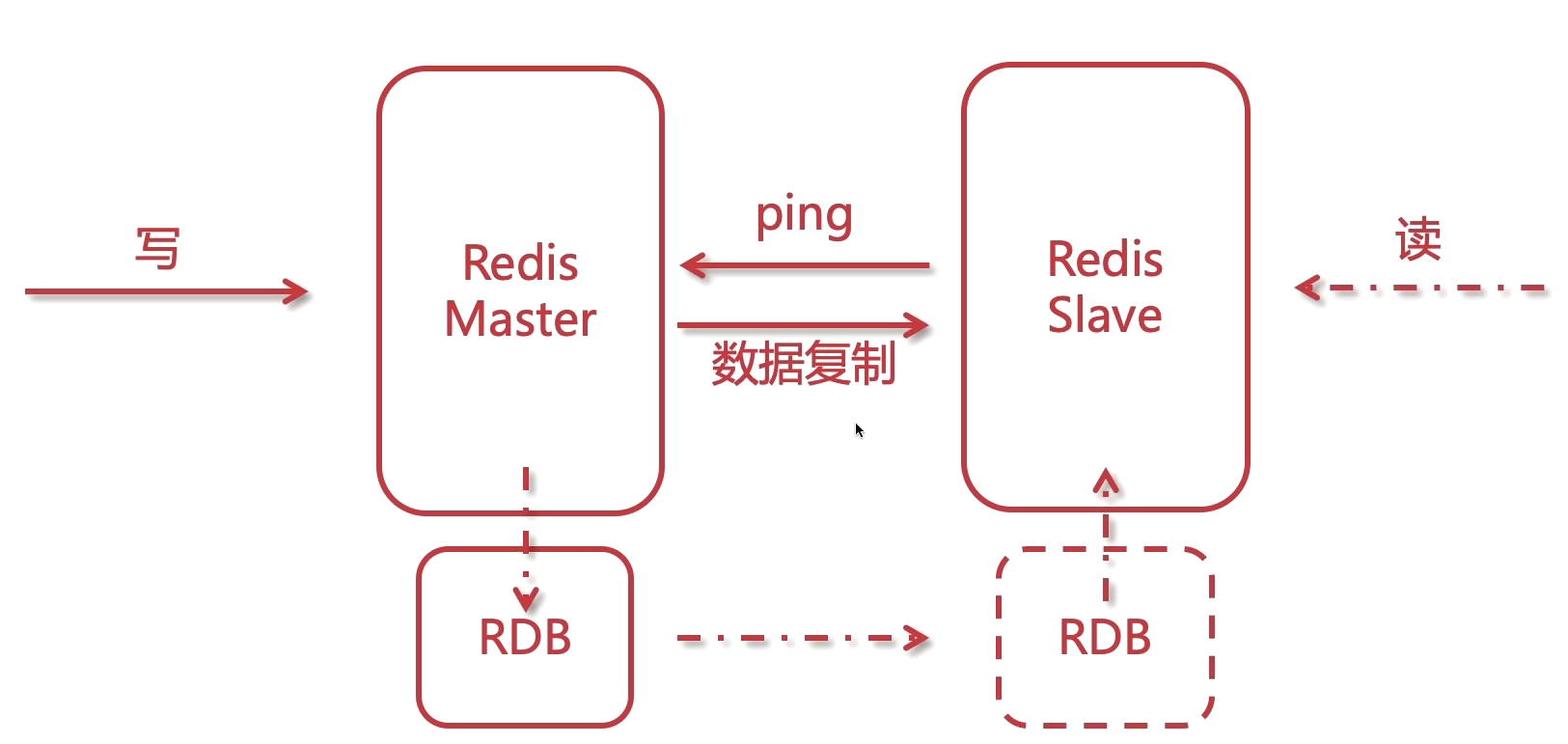
数据复制原理(全量同步)
- slave向master发送sync命令(数据同步)
- master接受到同步命令后,会保存快照,创建一个RDB文件
- 当master执行完保存快照后,会向slave发送RDB文件(无磁盘复制),而slave接收并载入RDB文件
- master将缓冲区的所有增量写命令发送给slave执行
- 以上处理完之后,之后master每执行一个写命令,都会将执行的写命令同步给slave
在Redis 2.8之后,主从断开会根据之前最新的命令偏移量进行增量复制。
- 主从断开重连,slave发送sync,带上ID
- master记录的ID和slave发送的ID一样的话,从偏移量开始发送命令
- 如果ID不一样,进行复制初始化
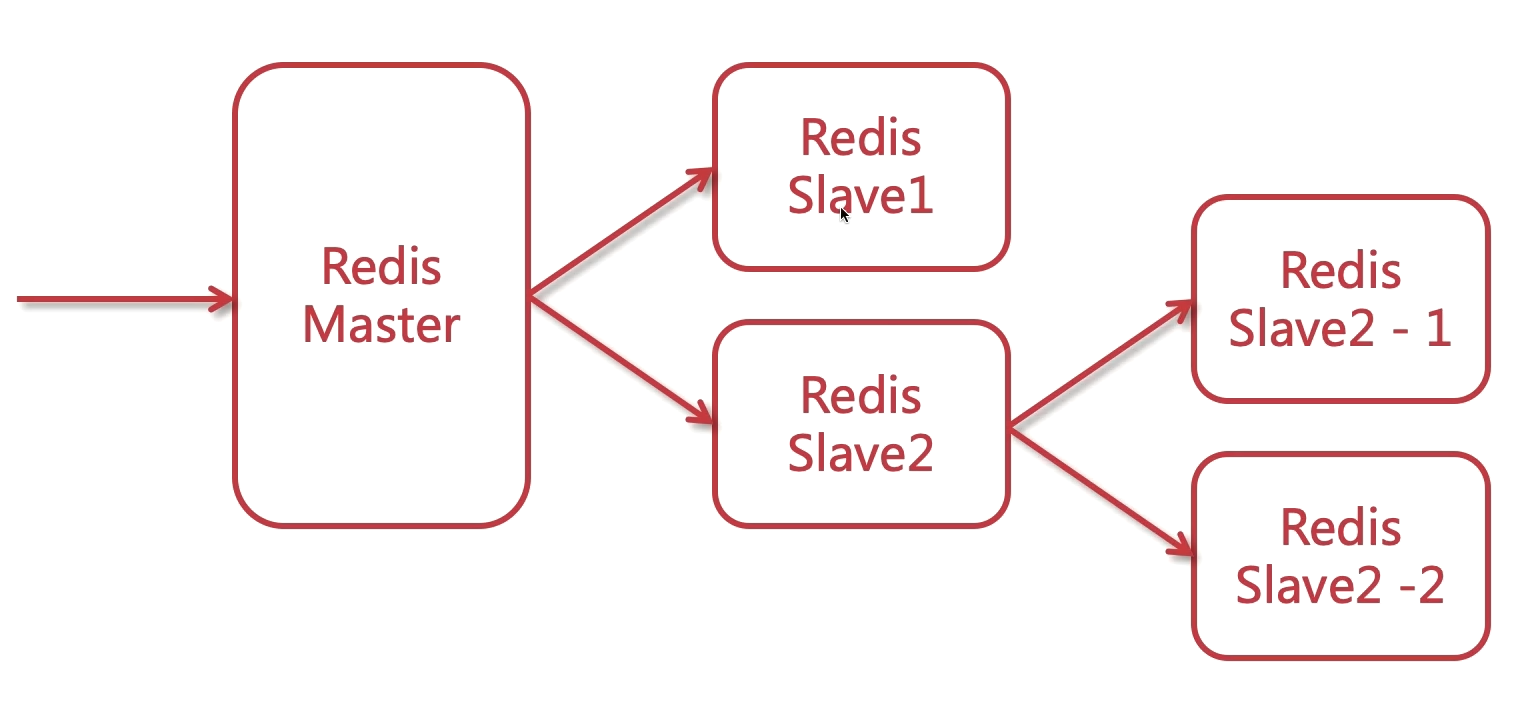
主从模式
一般使用一主二从。
虚拟机克隆
ip addr
# 记录下 link/ether 00:0c:29:0a:67:29 这个值
# 编辑.把里面 mac地址 和上面的替换掉
vim /etc/udev/rulels.d/*.rules
# 修改ip地址和mac地址
vim /etc/sysconfig/network-scripts/ifcfg-ens33
# 重启网卡
service network restart
搭建Redis主从复制(读写分离)
# redis-cli进入客户端
info replication
# 修改配置文件 从节点
replicaof 192.168.123.26 6379
# 主节点的密码
masterauth password
# 子节点只读
replica-read-only yes
主从直接通过ping来检测, 心跳检测.
注意:master挂掉之后, slave是不会成为master的.
无磁盘化复制
不再触碰硬盘进行复制,通过socket的方式进行传输。
# 无磁盘复制
repl-diskless-sync no
# 等待子节点可以连接之后再进行传输
repl-diskless-sync-delay 5
缓存过期机制
- (主动)定期删除。定时随机检查过期的key,如果过期则清理。
- (被动)惰性删除。当客户端请求一个已经过期的key的时候,那么redis会检查这个key是否过期,如果过期,则删除,然后返回一个nil。这种策略不太友好,虽然不会有太多的损耗, 但是内存的占用会比较高.
所以,虽然key过期了,但是只要没有被清除,那么内存还是占用着的。
# 默认是1秒钟10次, 扫描过期的数据
hz 10
内存淘汰管理机制
- maxmemory-policy
内存清理策略 - maxmemory
最大内存,单位字节
内存清理策略
- noeviction: 旧缓存永不过期, 新缓存设置不了, 返回错误
- allkeys-lru/lfu: 清除最近被/最少使用的旧缓存, 然后保存新的缓存
- allkeys-random: 在所有的缓存中随机删除
- volatile-lru/lfu: 在那些设置了expire过期时间的缓存中, 清除最近被/最少使用的旧缓存, 然后保存新的缓存
- volatile-random: 在那些设置了expire过期时间的缓存中, 随机删除缓存
- volatiel-ttl: 在那些设置了expire过期时间的缓存中, 删除即将过期的(ttl,time to live)
Redis哨兵模式
弥补主从架构模式的不足!故障转移(failover), 把从节点变成master
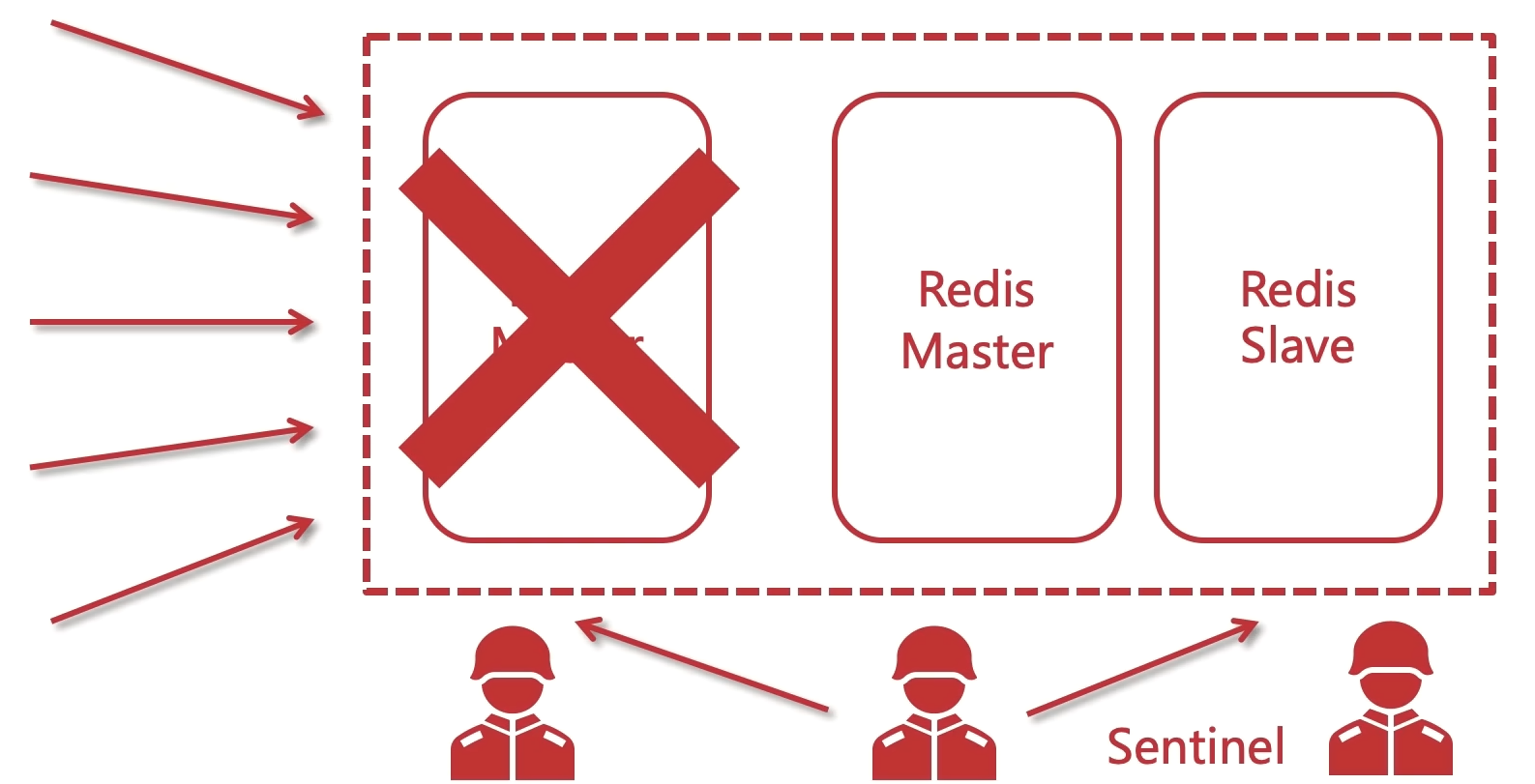
哨兵
- 集群监控:监控Redis master和slave进程是否正常工作
- 消息通知:如果某个Redis有故障,那么哨兵负责发送消息作为报警通知给管理员
- 故障转移:如果master node挂掉了,会自动转移到slave node上
- 配置中心:如果故障转移发生了,通知client客户端新的master地址
当主节点出现故障时,由Redis Sentinel自动完成故障发现和转移,并通知应用方,实现高可用性。
- 哨兵机制建立了多个哨兵节点(进程),共同监控数据节点的运行状况。
- 同时哨兵节点之间也互相通信,交换对主从节点的监控状况。
- 每隔1秒每个哨兵会向整个集群:Master主服务器+Slave从服务器+其他Sentinel(哨兵)进程,发送一次ping命令做一次心跳检测。
判断是否正常的依据
- 主观下线:一个哨兵节点判断主节点down掉了
- 客观下线:只有半数哨兵节点都主观判断主节点down了,此时多个哨兵节点交换主观判断结果,才会判断是主节点客观下线
- 原理:基本上哪个哨兵节点最先判断出这个主节点客观下线,就会在各个哨兵节点中发起投票机制
Raft算法(选举算法),最终被投为领导者的哨兵节点完成主从自动化切换的过程。
哨兵配置文件
# 编辑配置文件
vim sentinel.conf
mkdir /usr/local/redis/sentinel/ -p
# 启动
redis-sentinel sentinel.conf
sentinel.conf
# 关闭保护模式 允许外网访问
protected-mode no
port 26379
# 后台运行
daemonize yes
pidfile /var/run/redis-sentinel.pid
# 日志位置
logfile /usr/local/redis/sentinel/redis-sentinel.log
# 工作目录
dir /usr/local/redis/sentinel
# 核心配置 监控的主节点 昵称 主节点IP 端口 哨兵的数量
sentinel monitor foodie-master 192.168.123.26 6379 2
# 密码
sentinel auth-pass foodie-master lgq2020
# master被认为宕机(失效)的间隔时间, 以毫秒为单位
sentinel down-after-milliseconds foodie-master 10000
# 选举出新的master之后的, 剩余的slaves进行同步时的并行数量
sentinel parallel-syncs foodie-master 1
# 主备切换的操作时间.哨兵要做故障转移, 这个时候, 哨兵也是一个进程, 如果没有去执行, 超过这个时间, 就由其他哨兵来进行操作
sentinel failover-timeout foodie-master 180000
主节点宕机之后又恢复回来是否还会成为master?在keepalived是恢复回master的。
不会, 会变成slave.
解决原Master恢复之后不同步的问题
这是因为只设置了128和129的 masterauth , 这是用于同步master的数据, 但是26一开始是master是不受影响的, 当master转变为slave后, 由于他没有设置masterauth, 所以他不能从新的master同步数据, 随之导致info replication的时候, 同步状态为down, 所以只需要修改redis.conf中的 masterauth。一般遇到这种情况, 无法同步个slave的方案检查如下:
- 网络通信问题, 要保证互相ping通, 内网互通.
- 关闭防火墙, 对应的端口开发(虚拟机中建议永久关闭防火墙, 云服务器的话需要保证内网互通).
- 统一所有的密码, 不要漏了某个节点没有设置.
哨兵信息检查
# 进入redis客户端 注意端口号
redis-cli -p 26379
# 查看所有master节点信息
sentinel masters
# 查看foodie-master下的master节点信息
sentinel master foodie-master
# 查看foodie-master下的slaves节点信息
sentinel slaves foodie-master
# 查看foodie-master下的哨兵节点信息
sentinel sentinels foodie-master
SpringBoot集成Redis哨兵
spring:
redis:
database: 1
password: lgq2020
sentinel:
master: foodie-master
# 让哨兵进行托管
nodes: 192.168.123.128:26379,192.168.123.129:26379,192.168.123.26:26379
Redis集群
主从复制以及哨兵, 他们可以提高读的并发, 但是单个master容量有限, 数据达到一定程度会有瓶颈, 这个时候可以通过水平扩展为多master集群,将数据按照一定的规则分配到多台机器,这样内存/QPS不受限于单机。
Redis-cluster他可以支撑多个master-slave, 支持海量数据, 实现高可用与高并发。
哨兵模式其实也是一种集群, 他能够提高读请求的并发, 但是容错方面可能会有一些问题, 比如master同步数据给slave的时候, 这其实是异步复制, 如果这个时候master挂掉了, 那么slave上的数据就没有master新, 数据同步需要时间的, 1-2秒的数据就会丢失。master恢复并转换成slave后, 新数据则丢失.
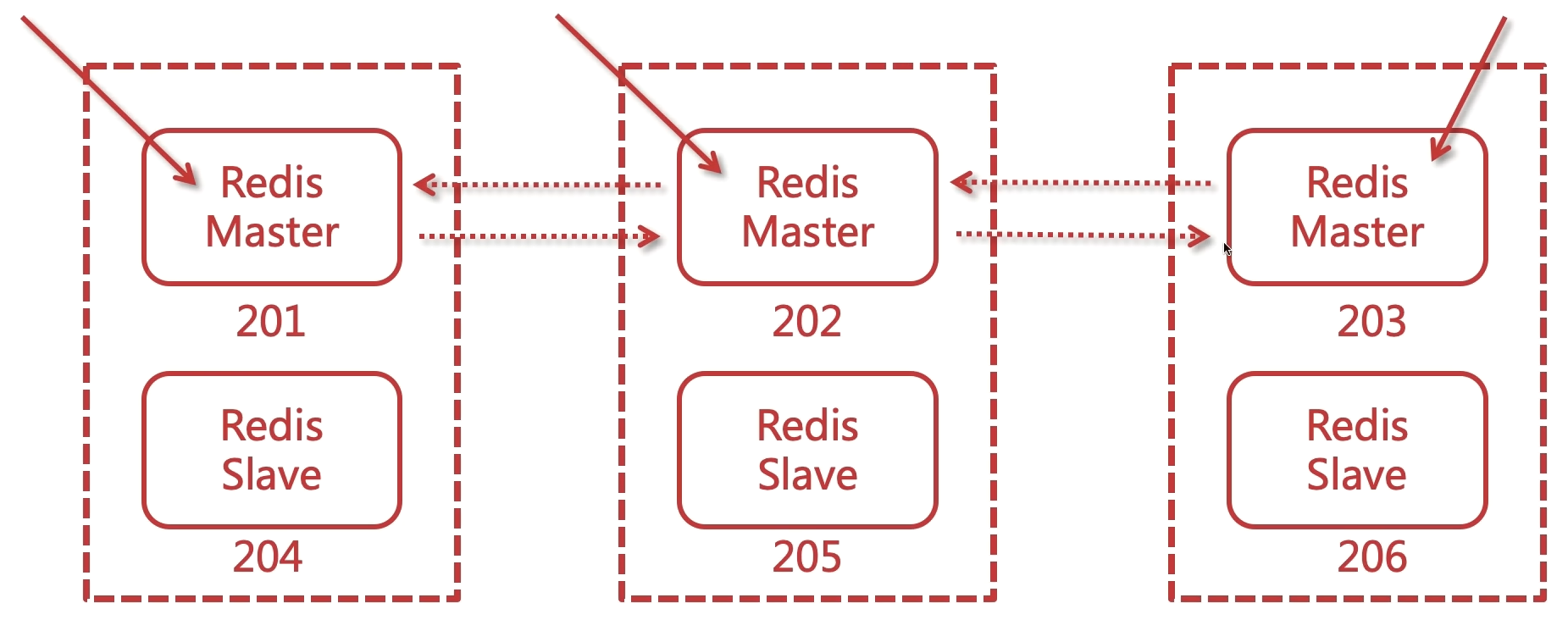
- 每个节点知道彼此之间的关系, 也会知道自己的角色, 当然他们也会知道自己存在于一个集群环境中, 他们彼此之间可以交互和通信, 他们彼此之间可以交互和通信(使用gossip,流言算法)。这些关系都会保存到某个配置文件中, 每个节点都有, 这个在搭建的时候会做配置的.
- 客户端要和集群建立连接的话, 只需要和其中一个建立关系就行.
- 某个节点挂了, 也是通过超过半数的节点来进行的检测, 客观下线后主从切换, 和之前在哨兵模式中提到的是一个道理.
- Redis中存在很多的插槽, 又可以称之为槽节点, 用于存储数据, 这个先不管, 后面再说.
如果某一节点宕机了, 其他节点会进行投票.
三主三从,6个节点,容错性更好。在同一台机器也可以搭建, 被称为伪集群。
开启配置文件中相关的集群配置
# 开启集群
cluster-enabled yes
# 开启即可, 由redis来管理
cluster-config-file nodes-6379.conf
# 超时时间
cluster-node-timeout 5000
老版本的集群构建需要用到ruby环境。
搭建集群
# 查看帮助
redis-cli --cluster help
# 创建 三主三从 主节点和从节点的比例为1, 1~3为主, 4-6为从, 1和4, 2和5, 3和6分别对应主从关系
redis-cli -a password --cluster create 192.168.123.128:6379 192.168.123.129:6379 192.168.123.26:6379 --cluster-replicas 1
# 检查
redis-cli -a password --cluster check 192.168.123.128:6379
Slot槽节点
有固定的 16384 个 slot 对每个 key 计算 CRC16 值然后对 16384 取模可以获取 key 对应的 hash slot。
每个master都会持有部分 slot。比如有3个 master 那么可能每个master持有5000多个 hash slot。
hash slot 让 node 的增加和移除很简单。增加一个 master 就将其他 master 的 slot 移动部分过去,减少一个 master 就将它的 slot 移动到其他 master 上去,移动 slot 的成本是非常低的。
客户端的api可以对指定的数据让他们走同一个 slot,通过 hash tag 来实现。
slot是分配给master的,slave是没有的!!数据的写入,是分配到slot的。
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
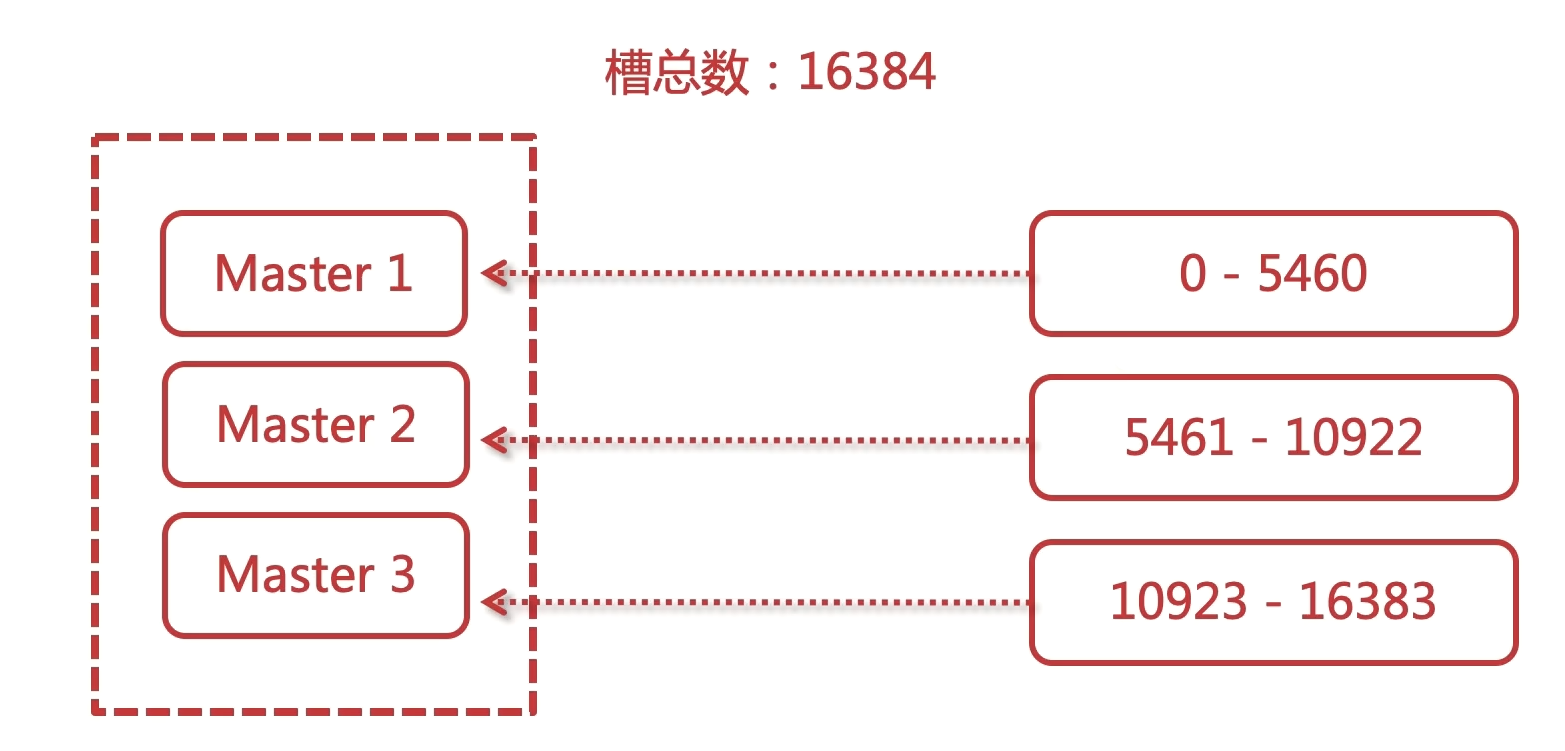
槽节点是跟着master的, 数据是放在那个槽里面去, 就相当于数据放在某一个master上面去.
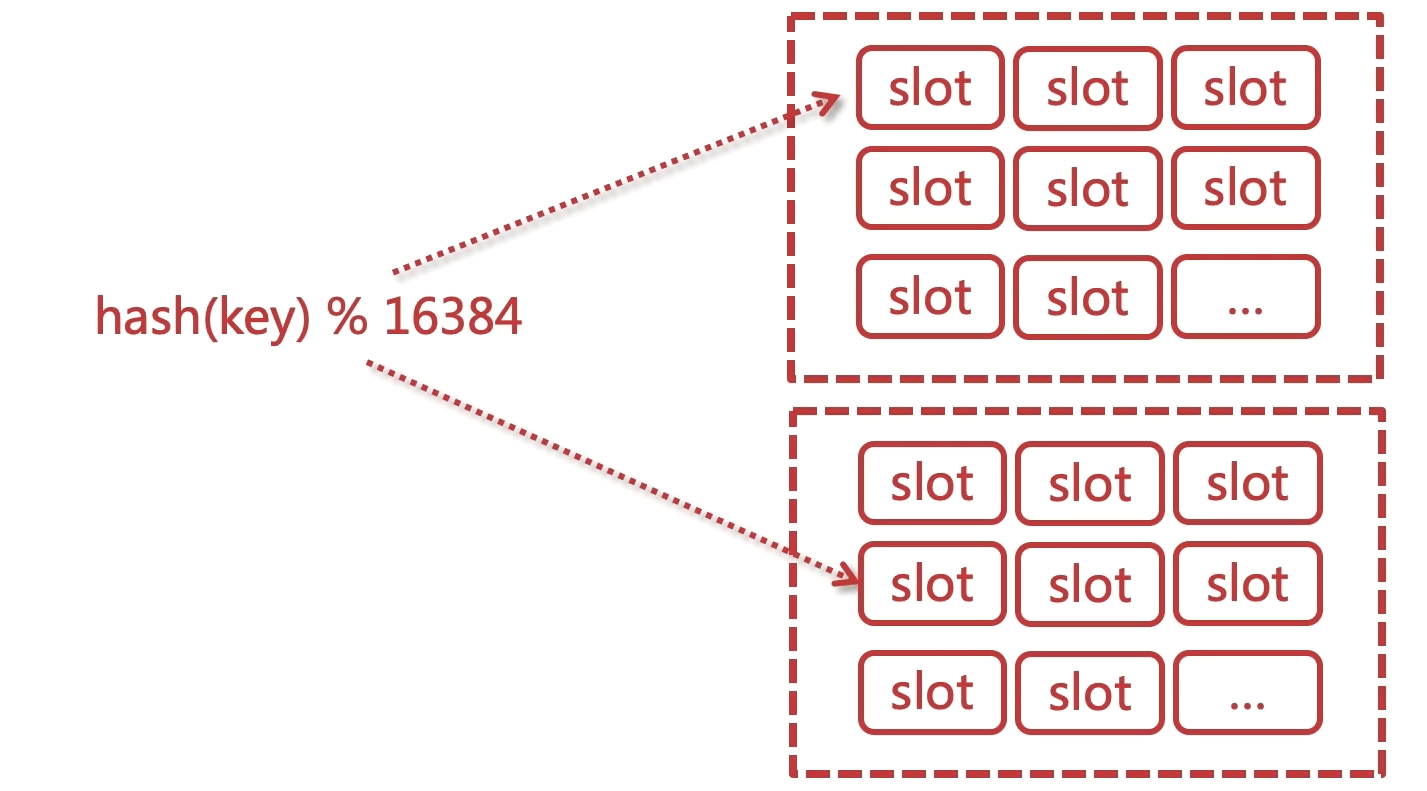
遵循一致性的hash原则。
集群测试
# 进入集群某一节点
redis-cli -c -a password -h 192.168.123.128:6379
cluster info
cluster nodes
客户端请求流程
- 请求重定向
客户端可能会挑选任意一个 redis 实例去发送命令,每个 redis 实例接收到命令,都会计算 key 对应的 slot。
如果在本地就在本地处理,否则返回moved给客户端,让客户端进行重定向。
cluster keyslot mykey,可以查看一个 key 在哪个 slot 中。
用redis-cli的时候,可以加入 -c 参数,支持自动的请求重定向,redis-cli 接收到moved之后,会自动重定向到对应的 slot 执行命令。
基于重定向的客户端,很消耗网络IO,因为大部分情况下,可能都会出现一次请求重定向,才能找到正确的节点。
本地缓存维护一份 slot -> node的映射表缓存,大部分情况下,直接走本地缓存就可以正确的 node, 不需要通过节点进行 moved重定向。
- 计算slot
计算 slot 的算法,就是根据 key 计算 CRC16 值,然后对 16384 取模,计算到对应的 slot。
也可以使用 tag 手动指定key对应的 slot,同一个 tag 下的 key,都会在一个 slot 中,,比如 set mykey1:{100} 和 set mykey2:{100}。
- slot查找
节点间通过 gossip 协议进行数据交换,就知道每个 slot 在哪个节点上。
缓存穿透
查询的key在redis中不存在, 对应的id在数据库也不存在, 此时被非法用户进行攻击, 大量的请求会直接打在db上, 造成宕机, 从而影响整个系统, 这种现象称之为缓存穿透.
解决方案:把空的数据也缓存起来, 比如空字符串, 空对象, 空数组或list.
布隆过滤器
能够迅速地判断一个元素是否在一个集合里面。
0代表不存在,1代表存在。在同一个位置上可能存在多个key。
是一种拦截器的概念。
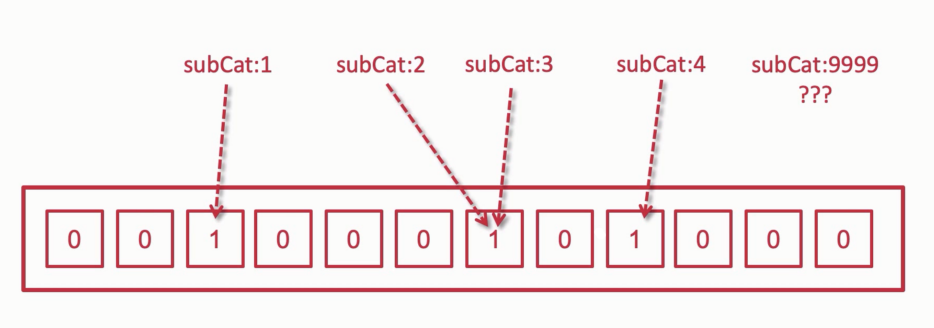
有误判率. 数组长度越长, 误判率越低, 所占空间就越大了.
做不到数据的移除. 因为多个数据会存在于一个位置.
代码的复杂度会提高.
缓存雪崩
某一时间, 大量的key到了过期时间, 不能提供缓存服务, 而恰好又有大量的不经过缓存的请求打在数据库上, 很有可能导致db宕机.
不能完全解决, 只能缓解.
预防
- 设置key永不过期, 避免大量key过期的情况出现.
- 过期时间错开.通过设置随机数来实现.
- 多缓存结合.Redis和Memcache, 查完redis没有再查memcache, Redis->Memcache->DataBase
- 采购第三方的Redis.可靠性和健壮性更高, 比起一年的运维成本可能更低.
和穿透相比,穿透是单个key, 用户的恶意攻击, 而雪崩是多个key.其实原因都是超高流量的并发, 打在数据库上造成的.
Redis批量查询
在海量数据key中进行查询, 如果直接查询会因为键的数量过多, 导致服务卡顿.
KEYS pattern : 查找所有符合给定的模式pattern的key.
# 查找符合模式的key
keys k1*
KEYS指令一次性返回所有匹配的key.- 键的数量过大会导致服务卡顿.
批量数据生成
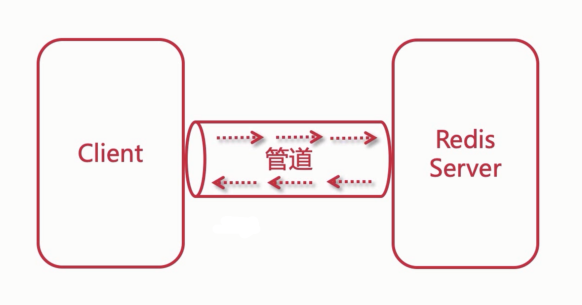
使用redis的管道, 批量生成模拟数据.
# 生成2千万条redis批量设置kv的语句(key=kn,value=vn)写入到/tmp目录下的redisTest.txt文件中
for((i=1;i<=20000000;i++)); do echo "set k$i v$i" >> /tmp/redisTest.txt ;done;
# 用vim去掉行尾的^M符号
vim /tmp/redisTest.txt
# 设置文件的格式, 通过这句话去掉每行结尾的^M符号
:set fileformat=dos
# 保存退出
:wq
# 通过redis的管道 --pipe 形式, 批量灌数据
cat /tmp/redisTest.txt | path/redis-6.18.0/src/redis-cli -h HOST_IP -p PORT --pipe -a PASS
# 结果
Last reply received from server.
errors: 0, replies: 20000000
批量查询使用
SCAN cursor [MATCH pattern] [COUNT count]
- 基于游标的迭代器, 需要基于上一次的游标延续之前的迭代过程.
- 以0作为游标开始一次新的迭代, 直到命令返回游标0完成一次遍历.
- 不保证每次执行都返回某个给定数量的元素, 支持模糊查询.
- 一次返回的数量不可控, 只能使返回结果大概率符合
count参数.
scan 0 match k1* count 10
1) "1048576" # 当前游标位置
2) 1) "k18945943"
2) "k10119920"
3) "k10656950"
4) "k16510518"
5) "k19951165"
6) "k17987079"
7) "k1549948"
8) "k12485843"
scan 1048576 match k1* count 10
# 注意有可能会出现获取重复 key 的问题, 因为游标不是递增的
# 所有要注意要去重 hashSet

博客内容遵循 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 协议
本文永久链接是:https://blog.lgq51233.xyz/2020/11/12/Redis%E5%9F%BA%E7%A1%80/