
分布式全局ID
分布式全局ID
- 使用UUID作为id实现主键全局唯一性保证.
- 通过统一的ID序列表, 实现全局ID.
- 雪花算法, 全局ID.
分库分表引发的ID问题
- 每张表都有唯一标识, 通常使用id
- id通常使用自增的方式
- 在分库分表的情况下, 每张表的id都是从0开始自增
- 导致业务混乱
分布式主键UUID
通用唯一识别码(Universally Unique Identifier)
缺点:只是一个单纯的id, 没有实际意义, 长度32位.
MyCat 不支持UUID, ShardingJdbc支持的.
ShardingJdbc配置, 使用SpringBoot的方式.
# 使用自定义的分片规则
spring.shardingsphere.sharding.tables.t_order.table-strategy.standard.sharding-column=order_id
spring.shardingsphere.sharding.tables.t_order.table-strategy.standard.precise-algorithm-class-name=org.lgq.sharding.MySharding
# 配置主键生成规则
spring.shardingsphere.sharding.tables.t_order.key-generator.column=order_id
spring.shardingsphere.sharding.tables.t_order.key-generator.type=UUID
MySharding.java
package org.lgq.sharding;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingValue;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.Collection;
/**
* 自定义分片规则的类
*
* @author DevLGQ
* @version 1.0
*/
public class MySharding implements PreciseShardingAlgorithm<String> {
private static final Logger log = LoggerFactory.getLogger(MySharding.class);
@Override
public String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<String> shardingValue) {
String uuid = shardingValue.getValue();
log.info("uuid: {}", uuid);
// 对节点个数进行取余
int mode = uuid.hashCode() % availableTargetNames.size();
log.info("mode: {}", mode);
mode = Math.abs(mode);
String[] array = availableTargetNames.toArray(new String[0]);
log.info("array: {}", array.toString());
return array[mode];
}
}
Spring命名空间配置, shardingJdbc.xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:p="http://www.springframework.org/schema/p" xmlns:context="http://www.springframework.org/schema/context"
xmlns:tx="http://www.springframework.org/schema/tx" xmlns:sharding="http://shardingsphere.apache.org/schema/shardingsphere/sharding"
xmlns:master-slave="http://shardingsphere.apache.org/schema/shardingsphere/masterslave" xmlns:bean="http://www.springframework.org/schema/util"
xmlns:master-savle="http://shardingsphere.apache.org/schema/shardingsphere/masterslave" xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://shardingsphere.apache.org/schema/shardingsphere/sharding
http://shardingsphere.apache.org/schema/shardingsphere/sharding/sharding.xsd
http://shardingsphere.apache.org/schema/shardingsphere/masterslave
http://shardingsphere.apache.org/schema/shardingsphere/masterslave/master-slave.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/tx
http://www.springframework.org/schema/tx/spring-tx.xsd http://www.springframework.org/schema/util http://www.springframework.org/schema/util/spring-util.xsd">
<bean id="ds0" class="com.zaxxer.hikari.HikariDataSource" destroy-method="close">
<property name="driverClassName" value="com.mysql.cj.jdbc.Driver" />
<property name="username" value="root" />
<property name="password" value="lgq51233" />
<property name="jdbcUrl"
value="jdbc:mysql://192.168.123.26:3306/sharding_order?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&allowPublicKeyRetrieval=true&useSSL=false" />
</bean>
<bean id="slave0" class="com.zaxxer.hikari.HikariDataSource" destroy-method="close">
<property name="driverClassName" value="com.mysql.cj.jdbc.Driver" />
<property name="username" value="root" />
<property name="password" value="lgq51233" />
<property name="jdbcUrl"
value="jdbc:mysql://192.168.123.197:3306/sharding_order?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&allowPublicKeyRetrieval=true&useSSL=false" />
</bean>
<bean id="ds1" class="com.zaxxer.hikari.HikariDataSource" destroy-method="close">
<property name="driverClassName" value="com.mysql.cj.jdbc.Driver" />
<property name="username" value="root" />
<property name="password" value="lgq51233" />
<property name="jdbcUrl"
value="jdbc:mysql://192.168.123.128:3306/shard_order?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&allowPublicKeyRetrieval=true&useSSL=false" />
</bean>
<!-- 数据源 $->{0..1} 占位符 -->
<sharding:data-source id="sharding-data-source">
<sharding:sharding-rule data-source-names="ds0,ds1">
<!-- 分片规则 -->
<sharding:table-rules>
<sharding:table-rule logic-table="t_order" actual-data-nodes="ds$->{0..1}.t_order_$->{1..2}"
database-strategy-ref="datasourceStrategy" table-strategy-ref="mySharding"
key-generator-ref="uuid"
/>
</sharding:table-rules>
<!-- 全局表 广播表 -->
<sharding:broadcast-table-rules>
<sharding:broadcast-table-rule table="area" />
</sharding:broadcast-table-rules>
<!-- 绑定表 子表 -->
<sharding:binding-table-rules>
<sharding:binding-table-rule logic-tables="t_order,t_order_item" />
</sharding:binding-table-rules>
</sharding:sharding-rule>
</sharding:data-source>
<sharding:key-generator id="uuid" column="order_id" type="UUID" />
<!-- 数据库的分片规则 -->
<sharding:inline-strategy id="datasourceStrategy" sharding-column="user_id" algorithm-expression="ds$->{user_id % 2}" />
<!-- 表的分片规则 行内表达式 -->
<sharding:inline-strategy id="tableStrategy" sharding-column="user_id" algorithm-expression="t_order_$->{id % 2 + 1}" />
<!-- 表的分片规则 使用自定义类 -->
<sharding:standard-strategy id="mySharding" sharding-column="order_id" precise-algorithm-ref="myShardingClass"/>
<!-- 修改 mapper 中查询的表, 应该是逻辑表来的 -->
<bean class="org.mybatis.spring.SqlSessionFactoryBean">
<property name="dataSource" ref="sharding-data-source" />
<property name="mapperLocations" value="classpath:mapper/*.xml" />
</bean>
<bean id="myShardingClass" class="org.lgq.sharding.MySharding"/>
</beans>
统一ID序列表
- ID的值统一从一个集中的ID序列生成器中获取
- ID序列生成器MyCat支持, ShardingJdbc不支持
- MyCat中有两种方式, 本地文件方式 和 数据库方式
- 本地的方式一般用于测试, 数据库的方式用于生产
- 优点:id统一管理, 避免重复
- 缺点:并发量大时, id生产器压力大
MyCat 统一ID配置
<!-- 2 本地时间戳方式 0 是本地 1 是数据库 -->
<property name="sequenceHandlerType">0</property>
使用本地的方式, 配置 sequence_conf.properties
#default global sequence
GLOBAL.HISIDS=
GLOBAL.MINID=10001
GLOBAL.MAXID=20000
# current ID
GLOBAL.CURID=10000
# 表名
ORDER.HISIDS=
ORDER.MINID=1001
ORDER.MAXID=2000
ORDER.CURID=1000
测试
INSERT INTO `order`(id, total_amount, order_status) VALUES(
next value for mycatseq_ORDER, 98, 3)
使用数据库的方式
修改sequenceHandlerType为 1, 然后再在数据库执行MyCat根目录下的 conf/dbseq.sql 脚本.
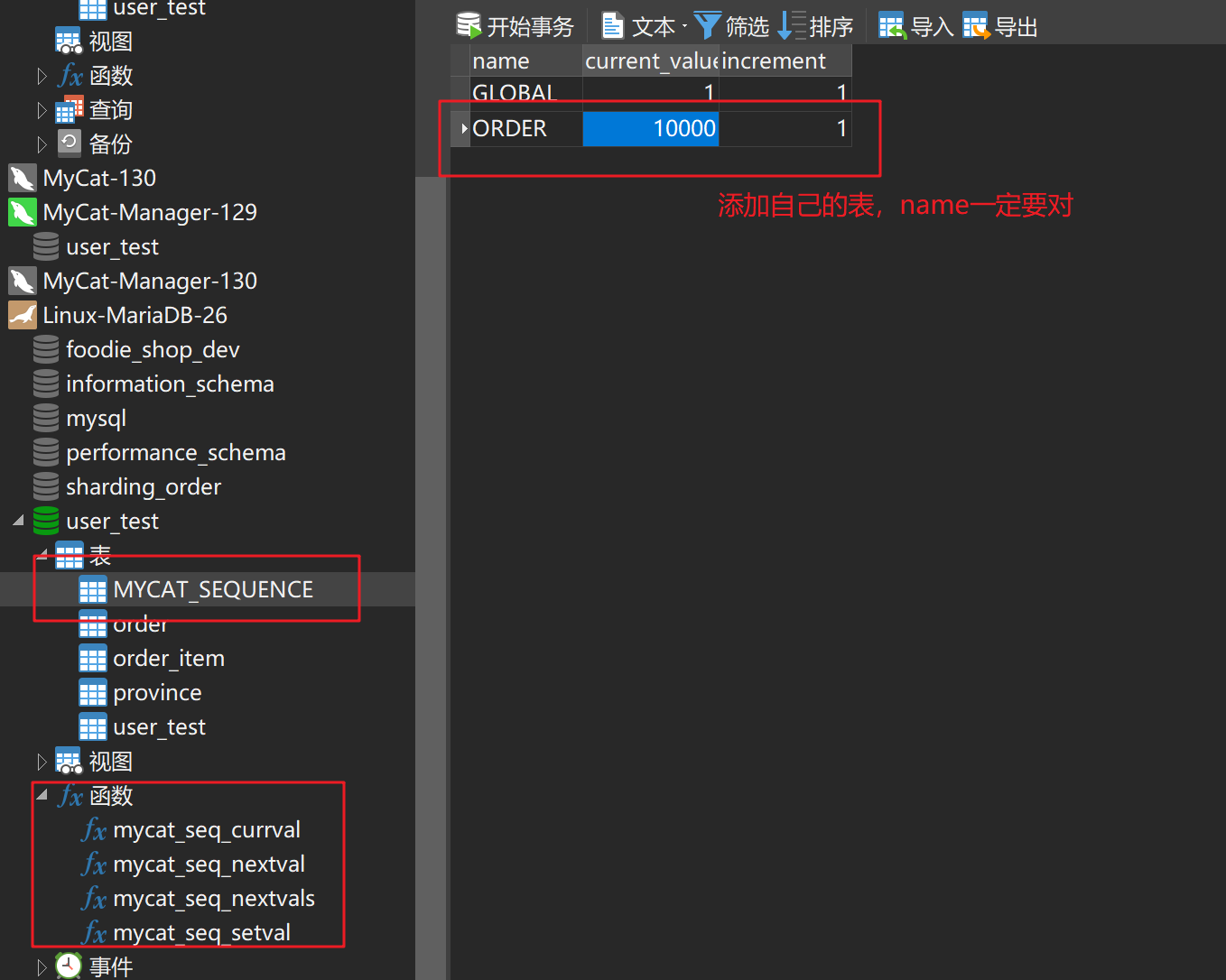
配置 sequence_db_conf.properties
#sequence stored in datanode
GLOBAL=dn1
COMPANY=dn1
CUSTOMER=dn1
ORDERS=dn1
ORDER=dn26
雪花算法
- SnowFlake 是 Twitter 提出的分布式id算法
- 一个64bit的long型数字
- 引入的时间戳, 保持自增
- 基本保持全局唯一, 毫秒级的并发最大4096个ID
- 时间回调, 可能会出现重复ID
- MyCat 和 Sharding—Jdbc 都支持雪花算法
- Sharding—Jdbc 可设置最大容忍回调时间
组成
- 1 是0, 如果第一位是1就是负数.
- 41 位时间戳, 设置的 开始时间 到 当前时间 的毫秒数. 能维持69年.
- 5 位机房id.
- 5 位机器id. 2^10, 最多1024台机器, 超过就有重复的风险了.
- 12 位序列号. 保证了同一时间同一机器下, 可以产生 2^12 = 4096 个序列. 也就是说, 在毫秒级的并发下是4096个.
MyCat 使用雪花算法
把 sequenceHandlerType 改为 2, 配置文件sequence_time_conf.properties.
# sequence depend on TIME 机器ID 注意要小于2^5(32)位.
WORKID=01
DATAACENTERID=01
ShardingJdbc 使用雪花算法
使用命名空间配置
<sharding:key-generator id="snowflake" type="snowflake" props-ref="snow" />
<bean:properties id="snow" >
<!-- 工作机器唯一id, 默认为0 -->
<prop key="work.id">678</prop>
<!-- 最大容忍时钟回退时间, 单位:毫秒. 默认为10毫秒 -->
<prop key="max.tolerate.time.difference.milliseconds">100</prop>
<!-- 最大抖动上限值, 范围[0, 4096), 默认为1. -->
<prop key="max.vibration.offset">1</prop>
</bean:properties>
使用 SpringBoot 的方式
spring.shardingsphere.sharding.tables.t_order.key-generator.type=SNOWFLAKE
spring.shardingsphere.sharding.tables.t_order.key-generator.props.worker.id=256
spring.shardingsphere.sharding.tables.t_order.key-generator.props.max.tolerate.time.difference.milliseconds=100
spring.shardingsphere.sharding.tables.t_order.key-generator.props.max.vibration.offset=1

博客内容遵循 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 协议
本文永久链接是:https://blog.lgq51233.xyz/2020/12/23/%E5%88%86%E5%B8%83%E5%BC%8F%E5%85%A8%E5%B1%80ID/