
分布式限流
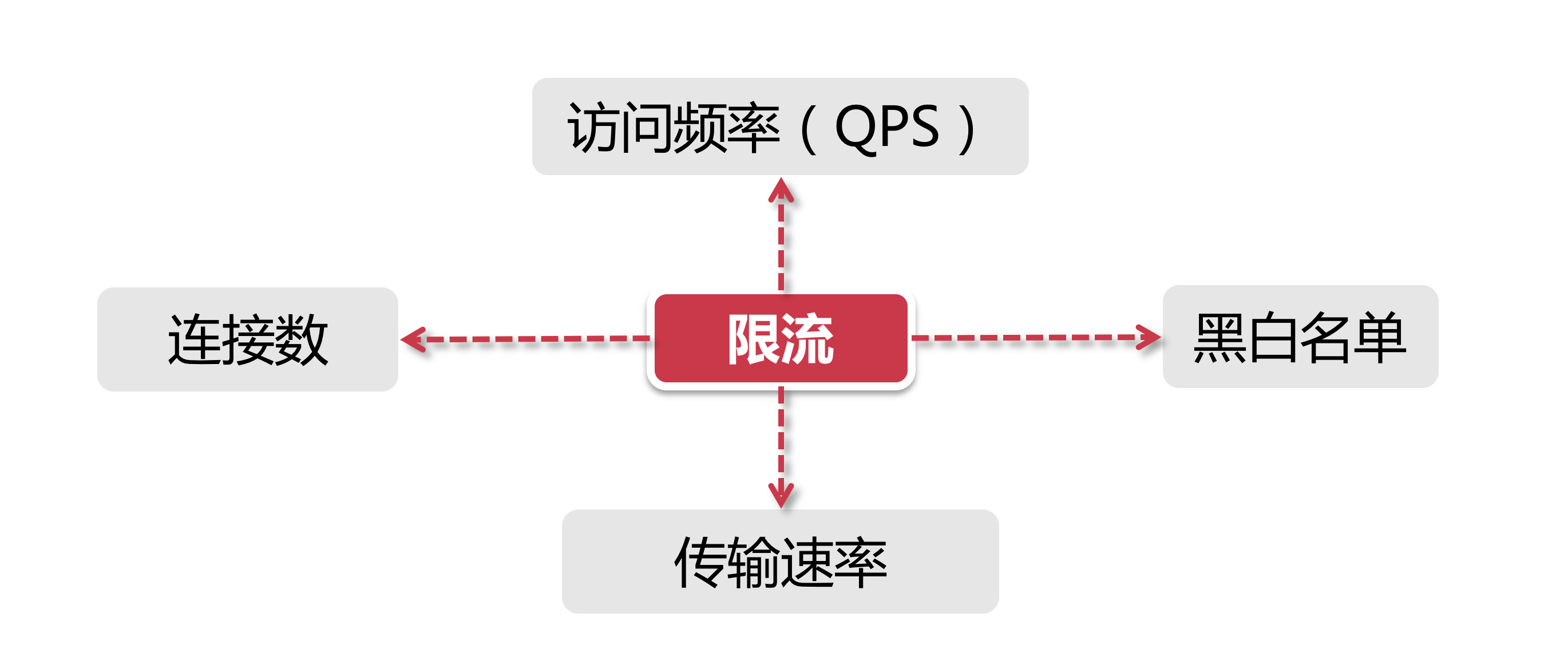
分布式限流维度
- 时间:限流基于某段时间范围或者某个时间点, 也就是我们常说的“时间窗口”, 比如对每分钟、每秒钟的时间窗口做限定.
- 资源:基于可用资源的限制, 比如设定最大访问次数, 或最高可用连接数.
上面两个维度结合起来看, 限流就是在某个时间窗口对资源访问做限制, 比如设定每秒最多100个访问请求. 主要的几种限流规则如下:
QPS和连接数控制
连接数和QPS(query per second)限流来说, 我们可以设定IP维度的限流, 也可以设置基于单个服务器的限流. 在真实环境中通常会设置多个维度的限流规则, 比如设定同一个IP每秒访问频率小于10, 连接数小于5, 再设定每台机器QPS最高1000, 连接数最大保持200. 更进一步, 我们可以把某个服务器组或整个机房的服务器当做一个整体, 设置更high-level的限流规则, 这些所有限流规则都会共同作用于流量控制.
传输速率
有的网站在这方面的限流逻辑做的更细致, 比如普通注册用户下载速度为100k/s, 购买会员后是10M/s, 这背后就是基于用户组或者用户标签的限流逻辑.
黑白名单
黑白名单是各个大型企业应用里很常见的限流和放行手段, 而且黑白名单往往是动态变化的. 举个例子, 如果某个IP在一段时间的访问次数过于频繁, 被系统识别为机器人用户或流量攻击, 那么这个IP就会被加入到黑名单, 从而限制其对系统资源的访问, 这就是我们俗称的“封IP”.
我们平时见到的爬虫程序, 比如说爬知乎上的美女图片, 或者爬券商系统的股票分时信息, 这类爬虫程序都必须实现更换IP的功能, 以防被加入黑名单. 有时我们还会发现公司的网络无法访问12306这类大型公共网站, 这也是因为某些公司的出网IP是同一个地址, 因此在访问量过高的情况下, 这个IP地址就被对方系统识别, 进而被添加到了黑名单. 使用家庭宽带的同学们应该知道, 大部分网络运营商都会将用户分配到不同出网IP段, 或者时不时动态更换用户的IP地址.
白名单就更好理解了, 相当于御赐金牌在身, 可以自由穿梭在各种限流规则里, 畅行无阻. 比如某些电商公司会将超大卖家的账号加入白名单, 因为这类卖家往往有自己的一套运维系统, 需要对接公司的IT系统做大量的商品发布、补货等等操作.
分布式环境
分布式区别于单机限流的场景, 它把整个分布式环境中所有服务器当做一个整体来考量. 比如说针对IP的限流, 我们限制了1个IP每秒最多10个访问, 不管来自这个IP的请求落在了哪台机器上, 只要是访问了集群中的服务节点, 那么都会受到限流规则的制约.
从上面的例子不难看出, 我们必须将限流信息保存在一个“中心化”的组件上, 这样它就可以获取到集群中所有机器的访问状态, 目前有两个比较主流的限流方案:
- 网关层限流 将限流规则应用在所有流量的入口处
- 中间件限流 将限流信息存储在分布式环境中某个中间件里(比如Redis缓存), 每个组件都可以从这里获取到当前时刻的流量统计, 从而决定是拒绝服务还是放行流量
分布式限流方案
Guava 限流
Guava在其多线程模块下提供了以RateLimiter为首的几个限流支持类. Guava是一个客户端组件, 也就是说它的作用范围仅限于“当前”这台服务器, 不能对集群以内的其他服务器施加流量控制.
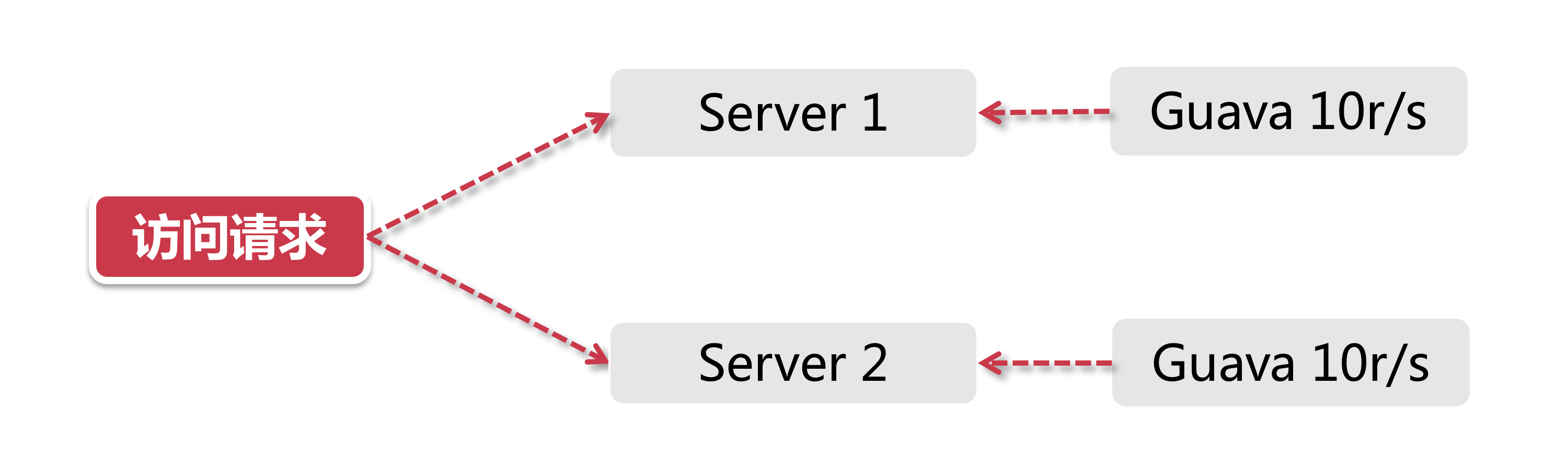
打个比方, 目前我有2台服务器[Server 1, Server 2], 这两台服务器都部署了一个登陆服务, 假如我希望对这两台机器的流量进行控制, 比如将两台机器的访问量总和控制在每秒20以内, 如果用Guava来做, 只能独立控制每台机器的访问量<=10.
网关层限流
在整个分布式系统中, 如果有这么一个“一夫当关, 万夫莫开”的角色, 非网关层莫属. 服务网关, 作为整个分布式链路中的第一道关卡, 承接了所有用户来访请求.
系统流量的分布层次抽象成一个简单的漏斗模型来看.
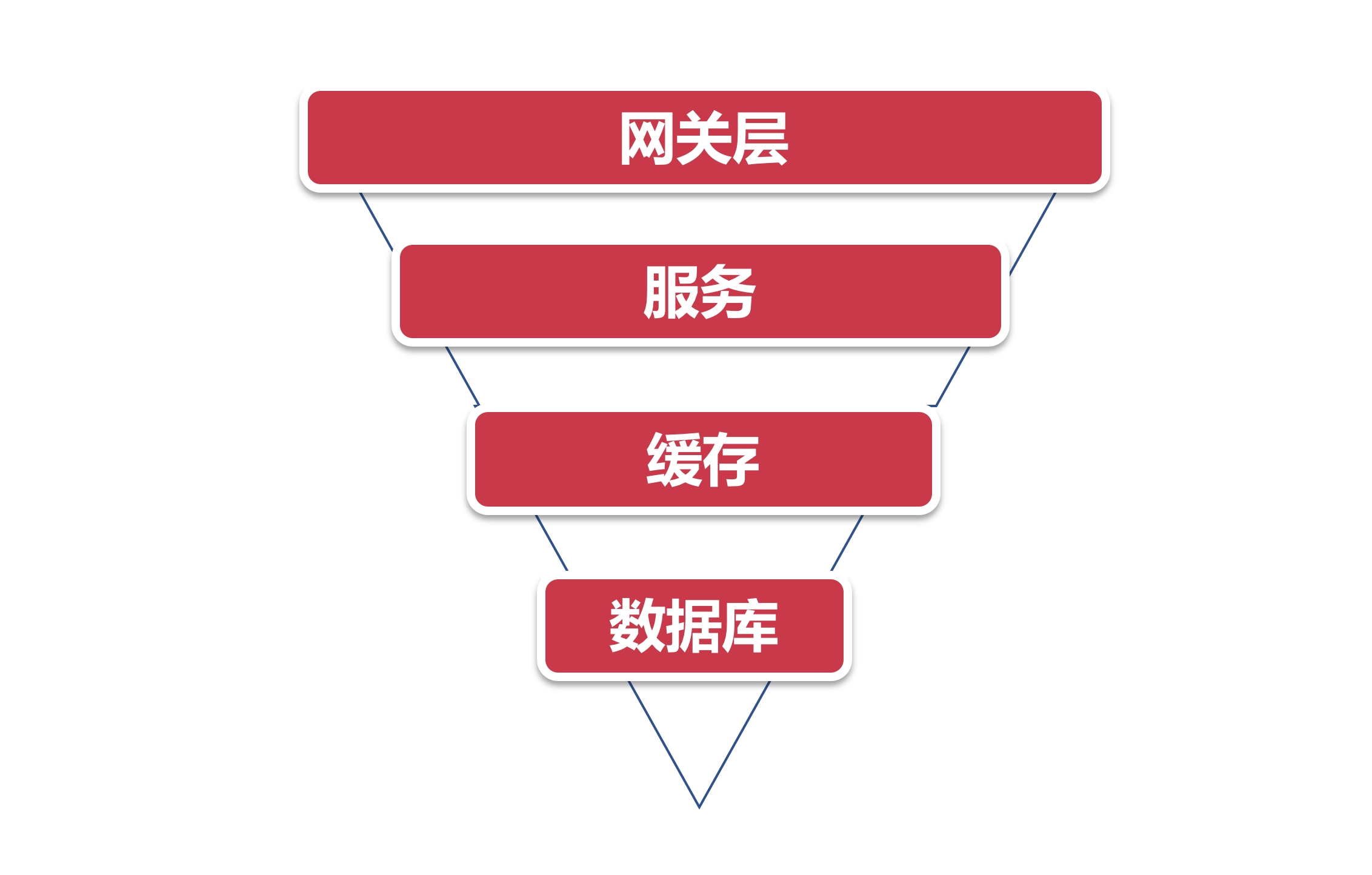
上面是一个最普通的流量模型, 从上到下的路径依次是:
- 用户流量从网关层转发到后台服务
- 后台服务承接流量, 调用缓存获取数据
- 缓存中无数据, 则访问数据库
因为流量自上而下是逐层递减的, 在网关层聚集了最多最密集的用户访问请求, 其次是后台服务. 然后经过后台服务的验证逻辑之后, 刷掉了一部分错误请求, 剩下的请求落在缓存上, 如果缓存中没有数据才会请求漏斗最下方的数据库, 因此数据库层面请求数量最小(相比较其他组件来说数据库往往是并发量能力最差的一环, 阿里系的MySQL即便经过了大量改造, 单机并发量也无法和Redis、Kafka之类的组件相比)
基于上面这个漏斗模型中做流量限制, 最适合的是网关层了. 因为它是整个访问链路的源头, 是所有流量途径的第一站. 目前主流的网关层有以软件为代表的Nginx, 还有Spring Cloud中的Gateway和Zuul这类网关层组件, 也有以硬件+软件为代表的F5.
Nginx限流的核心限流模式:
- 基于IP地址和基于服务器的访问请求限流
- 并发量(连接数)限流
- 下行带宽速率限制
中间件限流
网关层限流对他们来说貌似有点不那么受控, 有没有一个解决方案, 将限流下沉到业务层来, 让开发团队可以自行控制?
对于分布式环境来说, 无非是需要一个类似中心节点的地方存储限流数据. 打个比方, 如果我希望控制接口的访问速率为每秒100个请求, 那么我就需要将当前1s内已经接收到的请求的数量保存在某个地方, 并且可以让集群环境中所有节点都能访问.
利用Redis过期时间特性, 我们可以轻松设置限流的时间跨度(比如每秒10个请求, 或者每10秒10个请求). 同时Redis还有一个特殊技能–脚本编程, 我们可以将限流逻辑编写成一段脚本植入到Redis中, 这样就将限流的重任从服务层完全剥离出来, 同时Redis强大的并发量特性以及高可用集群架构也可以很好的支持庞大集群的限流访问.
限流组件
除了上面介绍的几种方式以外, 目前也有一些开源组件提供了类似的功能, 比如Sentinel就是一个不错的选择. Sentinel是阿里出品的开源组件, 并且包含在了Spring Cloud Alibaba组件库中.
架构维度考虑限流设计
在真实的大型项目里, 不会只使用一种限流手段, 往往是几种方式互相搭配使用, 让限流策略有一种层次感, 达到资源的最大使用率. 在这个过程中, 限流策略的设计也可以参考前面提到的漏斗模型, 上宽下紧, 漏斗不同部位的限流方案设计要尽量关注当前组件的高可用. 比如说研发了一个商品详情页的接口, 通过手机淘宝导流, app端的访问请求首先会经过阿里的mtop网关, 在网关层我们的限流会做的比较宽松, 等到请求通过网关抵达后台的商品详情页服务之后, 再利用一系列的中间件+限流组件, 对服务进行更加细致的限流控制.
限流方案常用算法
令牌桶算法
Token Bucket令牌桶算法是目前应用最为广泛的限流算法, 顾名思义, 它有以下两个关键角色:
- 令牌 获取到令牌的Request才会被处理, 其他Requests要么排队要么被直接丢弃
- 桶 用来装令牌的地方, 所有Request都从这个桶里面获取令牌
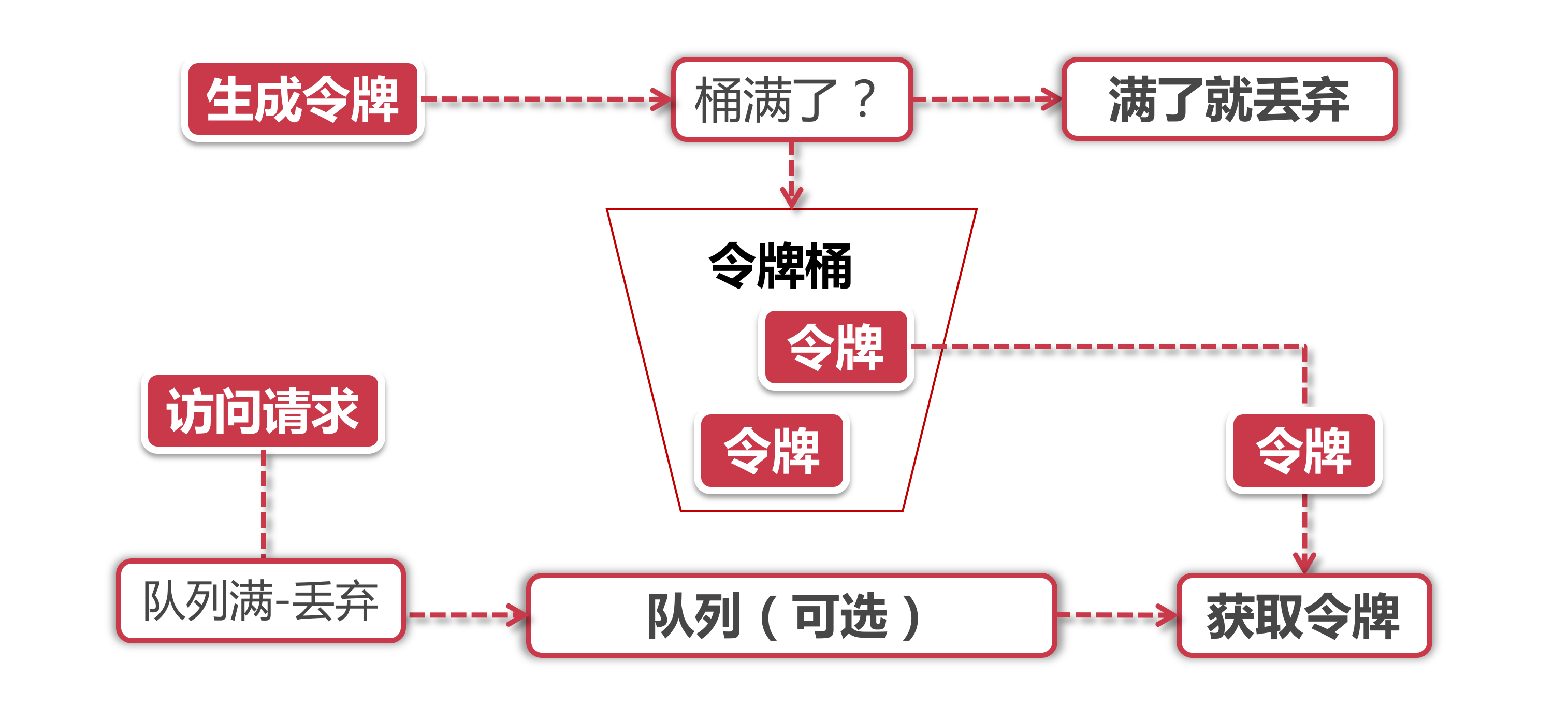
令牌生成, 这个流程涉及到令牌生成器和令牌桶, 前面我们提到过令牌桶是一个装令牌的地方, 既然是个桶那么必然有一个容量, 也就是说令牌桶所能容纳的令牌数量是一个固定的数值.
对于令牌生成器来说, 它会根据一个预定的速率向桶中添加令牌, 比如我们可以配置让它以每秒100个请求的速率发放令牌, 或者每分钟50个. 注意这里的发放速度是匀速, 也就是说这50个令牌并非是在每个时间窗口刚开始的时候一次性发放, 而是会在这个时间窗口内匀速发放.
在令牌发放器就是一个水龙头, 假如在下面接水的桶子满了, 那么自然这个水(令牌)就流到了外面. 在令牌发放过程中也一样, 令牌桶的容量是有限的, 如果当前已经放满了额定容量的令牌, 那么新来的令牌就会被丢弃掉.
令牌获取, 每个访问请求到来后, 必须获取到一个令牌才能执行后面的逻辑. 假如令牌的数量少, 而访问请求较多的情况下, 一部分请求自然无法获取到令牌, 那么这个时候我们可以设置一个“缓冲队列”来暂存这些多余的请求. 缓冲队列其实是一个可选的选项, 并不是所有应用了令牌桶算法的程序都会实现队列. 当有缓存队列存在的情况下, 那些暂时没有获取到令牌的请求将被放到这个队列中排队, 直到新的令牌产生后, 再从队列头部拿出一个请求来匹配令牌.
当队列已满的情况下, 这部分访问请求将被丢弃. 在实际应用中我们还可以给这个队列加一系列的特效, 比如设置队列中请求的存活时间, 或者将队列改造为PriorityQueue, 根据某种优先级排序, 而不是先进先出. 算法是死的, 人是活的, 先进的生产力来自于不断的创造, 在技术领域尤其如此.
漏桶算法
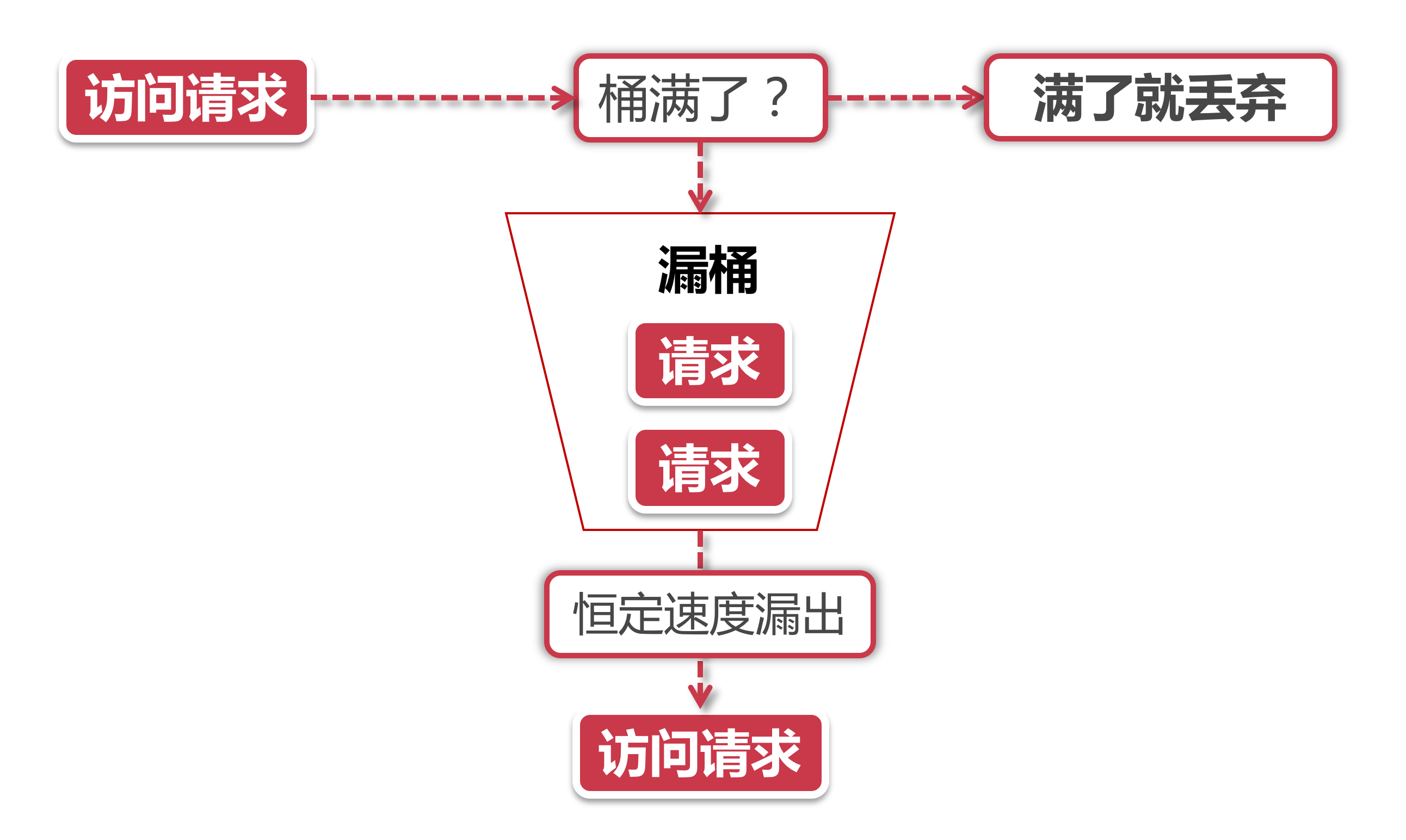
漏桶算法的前半段和令牌桶类似, 但是操作的对象不同, 令牌桶是将令牌放入桶里, 而漏桶是将访问请求的数据包放到桶里. 同样的是, 如果桶满了, 那么后面新来的数据包将被丢弃.
漏桶算法的后半程是有鲜明特色的, 它永远只会以一个恒定的速率将数据包从桶内流出. 打个比方, 如果我设置了漏桶可以存放100个数据包, 然后流出速度是1s一个, 那么不管数据包以什么速率流入桶里, 也不管桶里有多少数据包, 漏桶能保证这些数据包永远以1s一个的恒定速度被处理.
漏桶 vs 令牌桶的区别
根据它们各自的特点不难看出来, 这两种算法都有一个“恒定”的速率和“不定”的速率. 令牌桶是以恒定速率创建令牌, 但是访问请求获取令牌的速率“不定”, 反正有多少令牌发多少, 令牌没了就干等. 而漏桶是以“恒定”的速率处理请求, 但是这些请求流入桶的速率是“不定”的.
从这两个特点来说, 漏桶的天然特性决定了它不会发生突发流量, 就算每秒1000个请求到来, 那么它对后台服务输出的访问速率永远恒定. 而令牌桶则不同, 其特性可以“预存”一定量的令牌, 因此在应对突发流量的时候可以在短时间消耗所有令牌, 其突发流量处理效率会比漏桶高, 但是导向后台系统的压力也会相应增多.
滑动窗口

上图中黑色的大框就是时间窗口, 我们设定窗口时间为5秒, 它会随着时间推移向后滑动. 我们将窗口内的时间划分为五个小格子, 每个格子代表1秒钟, 同时这个格子还包含一个计数器, 用来计算在当前时间内访问的请求数量. 那么这个时间窗口内的总访问量就是所有格子计数器累加后的数值.
比如说, 我们在每一秒内有5个用户访问, 第5秒内有10个用户访问, 那么在0到5秒这个时间窗口内访问量就是15. 如果我们的接口设置了时间窗口内访问上限是20, 那么当时间到第六秒的时候, 这个时间窗口内的计数总和就变成了10, 因为1秒的格子已经退出了时间窗口, 因此在第六秒内可以接收的访问量就是20-10=10个.
滑动窗口其实也是一种计算器算法, 它有一个显著特点, 当时间窗口的跨度越长时, 限流效果就越平滑. 打个比方, 如果当前时间窗口只有两秒, 而访问请求全部集中在第一秒的时候, 当时间向后滑动一秒后, 当前窗口的计数量将发生较大的变化, 拉长时间窗口可以降低这种情况的发生概率.
基于 Guava Limiter 客户端限流
可用于对单机资源比较敏感的访问请求上.
- 非阻塞式限流方案
- 同步阻塞式限流方案
Guava RateLimiter预热模型
什么是流量预热?
我们都知道在做运动之前先得来几组拉伸之类的动作, 给身体做个热身, 让我们的身体平滑过渡到后面的剧烈运动中. 流量预热也是一样的道理, 对限流组件来说, 流量预热就类似于一种热身运动, 它可以动态调整令牌发放速度, 让流量变化更加平滑.
我们来举一个例子:某个接口设定了100个Request每秒的限流标准, 同时使用令牌桶算法做限流. 假如当前时间窗口内都没有Request过来, 那么令牌桶中会装满100个令牌. 如果在下一秒突然涌入100个请求, 这些请求会迅速消耗令牌, 对服务的瞬时冲击会比较大. 因此我们需要一种类似“热身运动”的缓冲机制, 根据桶内的令牌数量动态控制令牌的发放速率, 让忙时流量和闲时流量可以互相平滑过渡.
流量预热的做法
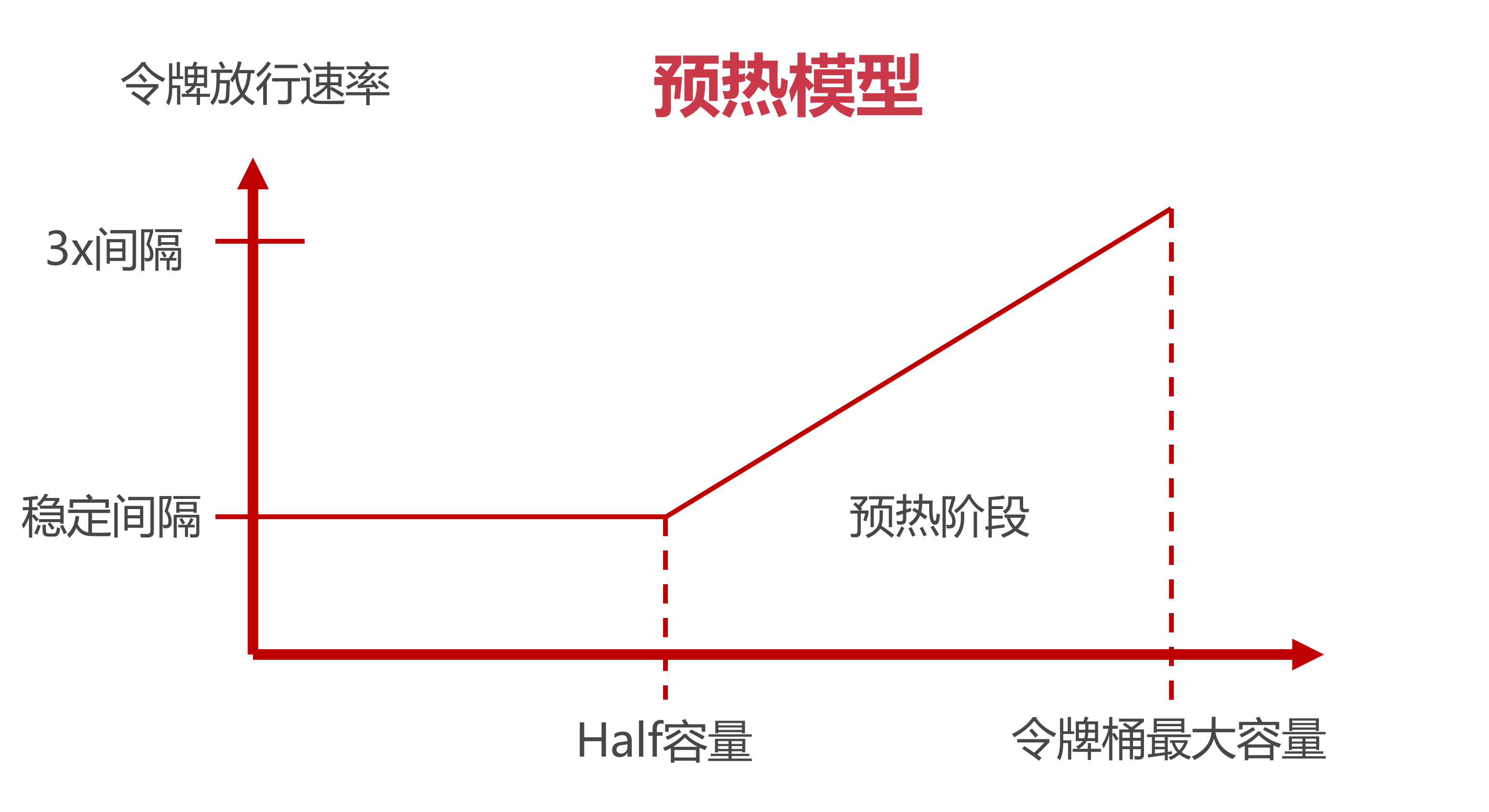
横坐标
下面两种场景会导致横坐标的变化:
- 闲时流量 流量较小或者压根没流量的时候, 横坐标会逐渐向右移动, 表示令牌桶中令牌数量增多
- 忙时流量 当访问流量增大的时候, 横坐标向左移动, 令牌桶中令牌数量变少
横轴有两个重要的坐标, 一个是最右侧的“令牌桶最大容量”, 这个不难理解. 还有一个是Half容量, 它是一个关键节点, 会影响令牌发放速率.
纵坐标
纵坐标表示令牌的发放速率, 这里有3个标线, 分别是稳定时间间隔, 2倍间隔, 3倍间隔.
这里间隔的意思就是隔多长时间发放一个令牌, 而所谓稳定间隔就是一个基准时间间隔. 假如我们设置了每秒10个令牌的限流规则, 那么稳定间隔也就是1s/10=0.1秒, 也就是说每隔0.1秒发一个令牌. 相应的, 3倍间隔的数值是用稳定间隔乘以系数3, 比如上面这个例子中3倍间隔就是0.3秒.
运作模式
继续沿用上面10r/s的限流设置, 稳定间隔=0.1s, 3x间隔是0.3s.
我们先考虑闲时到忙时的流量转变, 假定当前我们处于闲时流量阶段, 没几个访问请求, 这时令牌桶是满的. 接着在下一秒突然涌入了10个请求, 这些请求开始消耗令牌桶中的令牌. 在初始阶段, 令牌的放行速度比较慢, 在第一个令牌被消耗以后, 后面的请求要经过3x时间间隔也就是0.3s才会获取第二块令牌. 随着令牌桶中令牌数量被逐渐消耗, 当令牌存量下降到最大容量一半的时候(Half位置), 令牌放行的速率也会提升, 以稳定间隔0.1s发放令牌.
了解了横坐标和纵坐标的含义之后, 让我们来试着理解预热模型的用例. 继续沿用上面10r/s的限流设置, 稳定间隔=0.1s, 3x间隔是0.3s.
我们先考虑闲时到忙时的流量转变, 假定当前我们处于闲时流量阶段, 没几个访问请求, 这时令牌桶是满的. 接着在下一秒突然涌入了10个请求, 这些请求开始消耗令牌桶中的令牌. 在初始阶段, 令牌的放行速度比较慢, 在第一个令牌被消耗以后, 后面的请求要经过3x时间间隔也就是0.3s才会获取第二块令牌. 随着令牌桶中令牌数量被逐渐消耗, 当令牌存量下降到最大容量一半的时候(Half位置), 令牌放行的速率也会提升, 以稳定间隔0.1s发放令牌.
反过来也一样, 在流量从忙时转变为闲时的过程中, 令牌发放速率是由快到慢逐渐变化. 起始阶段的令牌放行间隔是0.1s, 随着令牌桶内令牌逐渐增多, 当令牌的存量积累到最大容量的一半后, 放行令牌的时间间隔进一步增大为0.3s.
RateLimiter正是通过这种方式来控制令牌发放的时间间隔, 从而使流量的变化更加平滑.
核心代码
实现流量预热的类是SmoothWarmingUp, 它是 SmoothRateLimiter 的一个内部类, 我们重点关注一个doSetRate方法, 它是计算横纵坐标系关键节点的方法.
SmoothRateLimiter.java
// permitsPerSecond表示每秒可以发放的令牌数量
@Override
final void doSetRate(double permitsPerSecond, long nowMicros) {
resync(nowMicros);
// 计算 稳定间隔, 使用1s除以令牌桶容量0
double stableIntervalMicros = SECONDS.toMicros(1L) / permitsPerSecond;
this.stableIntervalMicros = stableIntervalMicros;
// 调用SmoothWarmingUp类中重载的doSetRate方法
doSetRate(permitsPerSecond, stableIntervalMicros);
}
父类在这里的作用主要是计算出了稳定时间间隔(使用1s / 每秒放行数量的公式来计算得出), 然后预热时间、三倍间隔等是在子类的doSetRate方法中实现的.
SmoothWarmingUp
@Override
void doSetRate(double permitsPerSecond, double stableIntervalMicros) {
double oldMaxPermits = maxPermits;
// coldFactor 默认是 3.0
// 稳定间隔是0.1, 3倍间隔是0.3, 那么平均间隔是0.3
double coldIntervalMicros = stableIntervalMicros * coldFactor;
thresholdPermits = 0.5 * warmupPeriodMicros / stableIntervalMicros;
// maxPermits表示令牌桶内最大容量, 它由我们设置的预热时间除以稳定间隔获得
// 打个比方, 如果stableIntervalMicros=0.1s, 而我们设置的预热时间是2s
// 那么这时候maxPermits就是2除以0.1=20
maxPermits = thresholdPermits + 2.0 * warmupPeriodMicros / (stableIntervalMicros + coldIntervalMicros);
// slope的意思是斜率 速率从稳定间隔向 3x 间隔变化的斜线
slope = (coldIntervalMicros - stableIntervalMicros) / (maxPermits - thresholdPermits);
// 计算目前令牌桶的令牌个数
if (oldMaxPermits == Double.POSITIVE_INFINITY) {
// if we don't special-case this, we would get storedPermits == NaN, below
storedPermits = 0.0;
} else {
storedPermits =
(oldMaxPermits == 0.0)
? maxPermits // initial state is cold 初始化的状态是 3x 间隔
: storedPermits * maxPermits / oldMaxPermits;
}
}
为什么需要匀速限流
我们做这样一个场景假设, 在某个限流策略中我们设置了10r/s(每秒十个请求)的限流速率, 在令牌桶算法的实现中, 令牌生成器每秒会产生10个新令牌放入令牌桶. Guava的RateLimiter采用了一种“匀速”的策略生成令牌, 也就是说, 这10个令牌平均分到1秒钟的时间窗口中生成, 每0.1秒产生一个令牌. 如果在这一秒来了10个请求, 这些请求会在一秒钟以内匀速消化掉.
假如我们不采用匀速发放, 而是采用一把梭的模式发令牌, 在每一秒开始的时候把令牌一次性发放, 这样会带来什么问题呢?我们可以用两个场景来说明这种模式的弊端.
一个最明显的问题就是令牌利用率降低, 比如说我在前一秒还有9个令牌, 在下一秒刚开始就直接生产10个令牌, 这时候令牌桶明显装不下, 因此会丢弃掉9个令牌. 如果在这一秒突然涌来了15个请求, 由于这一秒的令牌都已经发放完毕, 所以这种一把梭的发牌模式最多只能在当前时间窗口内处理10个请求, 剩下的5个请求要延后到下一秒处理. 而如果我们采用匀速发牌的模式, 这15个请求会在下一秒的一开始就处理掉10个, 剩下的请求每隔0.1秒就会获取到一个新令牌, 这样一来, 15个请求在一秒内就可以处理完.
除此之外, 还有一个可能导致服务雪崩的问题.
在00:01秒和00:02秒各有10个令牌发放. 现在我化身为一个黑客, 想方设法打出高额QPS(query per second)击垮后台服务, 我想了这么一个方法, 我专挑当前这一秒和下一秒交汇的时间发起攻击, 假如在00:01秒这10个令牌没有被消耗, 那么我在这一秒快结束的时候能瞬间发起10个访问. 而在下一秒开始的时候由于又有10个新的令牌发放, 我可以在下一秒刚到的极短时间里再发起10个访问. 那么前后加起来, 我可以瞬间向后台服务打出10+10=20的瞬时流量, 当然20流量看起来并不大, 我们如果把限流策略定为每秒1w个令牌, 那么利用这种方式在理想情况下就可以打出2w的伤害, 这就是一个比较可观的数字了. 对于一些薄弱的后台服务, 很有可能造成服务响应超时, 如果发生在主链路, 甚至会进一步引发服务雪崩.
基于上面这些情况, 我们才需要将令牌按照一个“匀速”的频率放进令牌桶. 除此之外, 也可以利用前面提到的”滑动窗口“算法, 尽量使流量平滑输出, 不过即便是滑动窗口也并不能保证不会出现上面提到的人造流量峰值攻击, 所以, 使用匀速令牌桶才是理想的方案.
基于 Nginx 的IP限流
nginx文件配置
worker_processes 1;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
gzip on;
# 根据ip地址限制速度
# 1) 第一个参数 $binary_remote_addr
# binary_ 缩写内存占用量 remote_addr 表示通过IP地址进行限流
# 2) zone=iplimit:20m
# iplimit是一块内存区域 20m是内存区域的大小, 专门记录访问频率信息
# 3) rate=1r/s
# 每秒放行的请求数. 比如 100r/m 每分钟100个请求发行. 实际就是标识访问的频率.
limit_req_zone $binary_remote_addr zone=iplimit:20m rate=1r/s;
server {
server_name www.lgq-training.com;
location /access-limit/ {
proxy_pass http://127.0.0.1:10086/;
# 基于IP地址的限制
# 1) zone=iplimit 引用limit_req_zone中的zone信息
# 2) burst 设置一个大小为2的缓存区域, 当大量请求到来, 请求数量大于限制流量时, 将其放到缓存区域
# 3) nodelay 缓冲区满之后, 直接返回503异常
limit_req zone=iplimit burst=2 nodelay;
}
}
}
基于 Nginx 的连接数限制和单机限流
worker_processes 1;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
gzip on;
# 根据服务器级别进行限流
limit_req_zone $server_name zone=serverlimit:10m rate=1r/s;
# 基于连接数的配置 基于IP地址 当前的连接数, 没有时间
limit_conn_zone $binary_remote_addr zone=perip:20m;
# 基于server地址
limit_conn_zone $server_name zone=perserver:20m;
server {
server_name www.lgq-training.com;
location /access-limit/ {
proxy_pass http://127.0.0.1:10086/;
# 基于服务器级别的限制
# 通常情况下, 服务器限流速率应该比ip高的
limit_req zone=serverlimit burst=1 nodelay;
# 每个server最大连接数100个
limit_conn perserver 100;
# 每个ip最大连接数1个
limit_conn perip 1;
# 指定返回异常代码 默认是 503
limit_req_status 504;
limit_conn_status 504;
# 在100m之后限速
# limit_rate_after 100m;
# 限制速度256k
# limit_rate 256k;
}
}
}
基于 Redis+Lua 的分布式限流
- 性能十分优异.
- 线程安全 只用单线程承接网络请求(其他模块仍然多线程), 天然具有线程安全的特性, 而且对原子性操作支持到位.
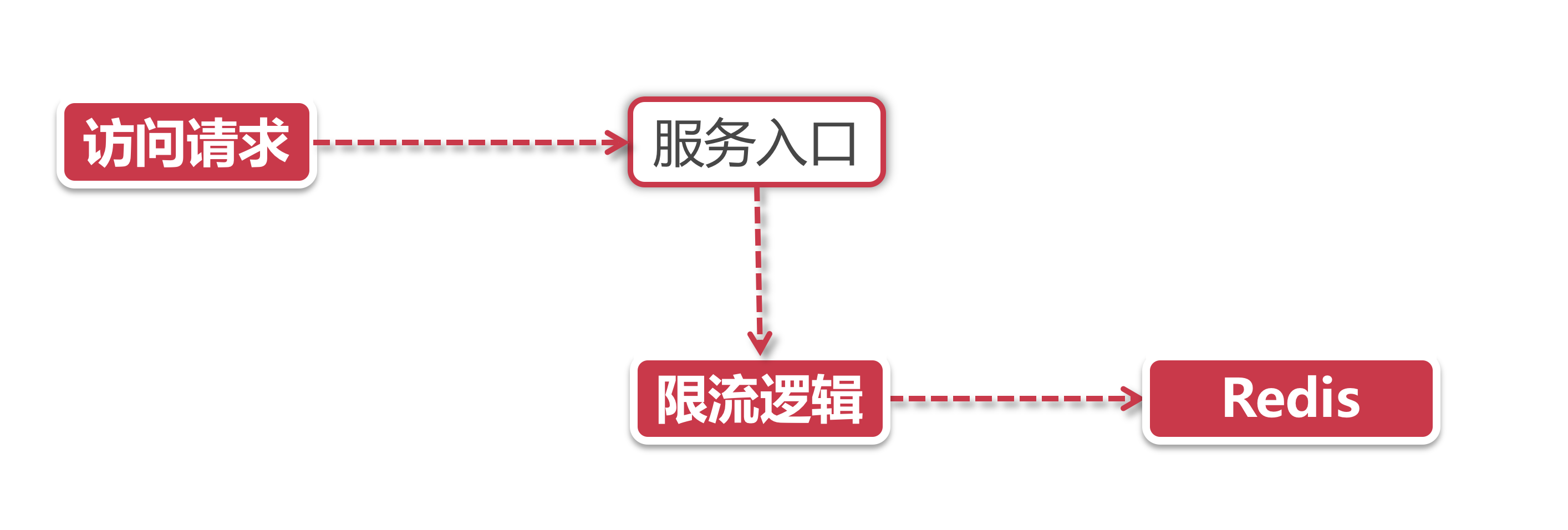
- 限流请求 需要被限流的对象
- 限流规则 定义一段程序或者脚本, 当请求到来的时候执行
- 存储介质 用来存储限流信息的地方, 比如令牌个数或者是访问请求的
Lua 基本使用
- 短小精悍
- 嵌入式开发, 插件开发
- 完美集成Redis. Redis内置lua解析器, 执行过程原子性, 脚本预编译
-- 用作限流的Key
local key = 'MY_KEY'
-- 限流的最大阈值
local limit = 2
-- 当前流量大小
local currentLimit = 2
-- 是否超过限流标准
if currentLimit + 1 > limit then
print 'reject'
return false
else
print 'accept'
return true
end
Redis 预加载 Lua
进入 redis 客户端
# 直接使用 lua 脚本
eval "return {KEYS[1], ARGV[1]}" 2 K1 K2 V1 V2
# 输出
# 1) "K1"
# 2) "V1"
# 预加载 lua 脚本
script load "return 'hello reids+lua'"
# 返回一个 93b41c5c210de48a90064447045f3880ff1318f3
# 执行预加载好的lua程序
evalsha 93b41c5c210de48a90064447045f3880ff1318f3 0
# 判断脚本是否存在
script exists 93b41c5c210de48a90064447045f3880ff1318f3
# 清空脚本预编译文件
script flush
限流组件封装
基于 Aspect 实现
注解AccessLimiter.java
package org.lgq.ratelimiterannotation.annotation;
import java.lang.annotation.*;
/**
* @author DevLGQ
* @version 1.0
*/
@Target({ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface AccessLimiter {
int limit();
String methodKey() default "";
}
注解解析AccessLimiterAspect.java
package org.lgq.ratelimiterannotation.annotation;
import com.google.common.collect.Lists;
import io.netty.util.internal.StringUtil;
import org.aspectj.lang.JoinPoint;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Before;
import org.aspectj.lang.annotation.Pointcut;
import org.aspectj.lang.reflect.MethodSignature;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.data.redis.core.script.RedisScript;
import org.springframework.stereotype.Component;
import javax.annotation.Resource;
import java.lang.reflect.Method;
import java.util.Arrays;
import java.util.stream.Collectors;
/**
* 切面流程
*
* @author DevLGQ
* @version 1.0
*/
@Aspect
@Component
public class AccessLimiterAspect {
private static final Logger log = LoggerFactory.getLogger(AccessLimiterAspect.class);
@Resource
private StringRedisTemplate redisTemplate;
@Resource
private RedisScript<Boolean> rateLimitLua;
/**
* 切点捕获
*/
@Pointcut("@annotation(org.lgq.ratelimiterannotation.annotation.AccessLimiter)")
public void cut() {
log.info("cut");
}
@Before("cut()")
public void before(JoinPoint joinPoint) {
// 获得方法签名, 作为 method key 通过反射获得注解
MethodSignature signature = (MethodSignature) joinPoint.getSignature();
Method method = signature.getMethod();
AccessLimiter annotation = method.getAnnotation(AccessLimiter.class);
if (annotation == null) {
return;
}
String key = annotation.methodKey();
Integer limit = annotation.limit();
// 如果没有设置methodKey, 从调用方法签名自动生成一个Key
if (StringUtil.isNullOrEmpty(key)) {
// 获取入参
Class<?>[] type = method.getParameterTypes();
// 获取方法名
key = method.getName();
if (type != null) {
String paramType = Arrays.stream(type).map(Class::getName).collect(Collectors.joining(","));
log.info("paramType: {}", paramType);
key += "#" + paramType;
}
}
// 调用 redis
boolean acquired = this.redisTemplate.execute(
rateLimitLua, // lua script
Lists.newArrayList(key), // Lua脚本中的Key列表
limit.toString() // Lua脚本Value列表
);
if (!acquired) {
log.error("your access is blocked, key={}", key);
throw new RuntimeException("Your access is blocked");
}
}
}
限流组件失效
再牛的系统也不能保证100%的可用性, 限流组件也不意外. 尽管Redis和Nginx都是蛮靠谱的组件, 但是明天和意外你永远不知道哪一个先来.
这是一个悖论似的问题, 继续提供服务就相当于给了外部攻击者利用流量洪峰击垮系统的机会, 而拒绝服务就相当于系统关门打烊了.
可以参考Spring Cloud和其他限流开源方案的做法, 当限流组件失效的时候, 默认不启用限流服务. 比如Spring Cloud的Gateway网关默认提供了Lua + Redis的限流功能, 当Redis服务不可用的时候, Gateway就直接将所有访问请求做放行处理.
其实道理很简单, 拒绝外部请求所造成的损失, 远大于放行请求暴露出的潜在破绽. 大家在设计自己的限流方案的同时, 一定要记得考虑异常情况, 如果是限流组件自身不可用的问题, 那么就放弃限流, 选择直接放行服务.
如何确定限流上界
对限流组件来说, 如果能“卡在”系统处理能力的上限附近, 那是再好不过的了. 因此这个数值不能靠猜, 而必须基于事实依据. 那么事实从哪里来?压力测试!
在历次阿里集团双11的大运动中, 其实早在双11前半年, 很多业务部门已经开始在为双11做技术优化了. 在双11之前的几个月, 全面压测已经在集团的全链路压测平台上紧锣密鼓的开展了. 当然, 压测和容灾演练在平时空闲的时候也会开展, 对于我们这更像是一个“常态化”的过程, 就比如集团经常冷不丁切断一个机房的设备, 倒逼各个事业部将各自的应用以异地多活的方式部署.
压测不仅仅是无脑打高流量, 找到系统的极限, 而是在基于一个合理的“预估”访问量级之下, 对系统进行全方位的摸底. 执行全链路压测, 它不仅包含压力测试, 还有故障演练, 异地多活演练(突然切断一整个机房), 弹性伸缩(紧急上线新机器提高算力), 服务降级(核心主链路降级演练, 考察系统的最低可用性)等等复杂的流程.
因此, 在确定限流上界之前, 我们要根据当前业务规模预估一个合理的访问量级, 再乘以一个系数(比如1.2)保证当前系统有一部分设计余量(预留少量弹性空间), 通过压测找到系统瓶颈加以巩固, 先确保当前系统在这个量级下的可用性. 在此之上, 向上打流量, 反复进行多次测试后分析汇总性能指标(QPS和连接数), 将限流的上界设置在指标的「平均值」或者「中位数」附近.

博客内容遵循 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 协议
本文永久链接是:https://blog.lgq51233.xyz/2020/12/28/%E5%88%86%E5%B8%83%E5%BC%8F%E9%99%90%E6%B5%81/