
ElasticSearch读写原理
ElasticSearch读写原理
写数据过程
- client 通过 hash 选择一个 node 发送请求,这个 node 被称作为 coordinating node(协调节点)
- 协调节点对 document 进行路由,将请求转发给对于的 primary shard
- primary shard 处理请求,将数据同步到所有的 replica shard
- 此时协调节点,发现 primary shard 和 所有的 replica shard 都处理之后,就返回给 client
写数据底层原理
- 在到达 primary shard 的时候,数据先写入内存 buffer ,此时,在 buffer 里的数据是不会被搜索到的,同时也生成一个 translog 日志文件,将操作写入 translog 里。
- 如果内存的 buffer 快满了,就会将数据 refresh 到一个新的 segment file 中,默认 es 是每隔1s就会将 buffer 里的数据写入到一个新的 segment file 中的。如果buffer没有数据,不会执行 refresh 操作。建立 segment file 的同时也建立好倒排索引了。
- 在 buffer refresh 后,buffer的数据会先进入 os cache,而这时候数据就可以被搜索到了。数据进入os cache后,buffer中的数据也会被清空的。这也是为什么es被称作是准实时(NRT,near real-time)的原因,因为写入的数据,要在1s之后才能被搜索到。可以通过 es 的 RESTFull API 手动执行 refresh 操作将 buffer 的数据 refresh 到 os cache 中,这样数据就可以立刻搜索到。
- 随着数据不断进入 buffer 和 translog,不断将数据写入到新的 segment file 中,每次 refresh 完,buffer 清空,translog 保留。这样下去,translog 就会越来越大,当到达一定长度的时候,就会触发 commit 操作。对于 translog 也是先进入 os cache 中的,然后每隔 5s 才会持久化到 translog 磁盘文件中。默认是每隔30min自动执行一次 commit。
- commit 操作第一步,就是把 buffer 的数据 refresh 到 os cache 中,清空 buffer。
- 将一个 commit point 写入磁盘文件,里面标识着所有新的 segment file。
- 强行将 os cache 中缓冲的数据 flush 到磁盘文件中去。
- 然后将现有的 translog 文件清空,再重新启用一个 translog,这样 commit 操作就完成了。commit 操作也叫做 flush 操作。
- 从上面操作可以知道,在默认的情况下,有5s的数据可能是停留在 buffer,segment file os cache 或者 translog os cache中的,不在磁盘的,这就意味着如果机器宕机了,就会损失掉这5s的数据。所以对于比较敏感的数据,可以设置参数让每次写入的数据直接写入 translog 磁盘文件,但是这样会使 es 的性能有所下降。
- 对于删除操作,commit 操作时就会生成一个 .del 文件,然后将 document 标识为 deleted 状态,client 搜索时就不会搜索到了。
- 对于更新操作,将原来的 document 标识为 deleted 状态,然后写入一条数据。
- 随着 segment file 越来越多,多到一定程度的时候,就会自动触发 merged 操作,将所有的 segment file 合并成一个 segment file,并且同时物理删除标识为 deleted 的 document。
注意点
- ES 是准实时的,默认是写入数据1s之后才能查询。
- ES 的数据可能会丢失,因为 translog 的 flush 是每隔 5s 执行的。
- translog 的作用是为了防止在 commit 之前,数据不是在 buffer 上就是在 os cache 上,如果系统宕机了,可以利用 translog 在重启系统的时候,进行恢复操作。
读数据过程
- client 发送 get 请求到任意个 node,而这个 node 称作 协调节点。
- 协调节点对document进行路由,将请求转发到对应的node,此时会使用随机轮询算法,在 primary shard 和 replica shard 中随机选择一个,让请求负载均衡。
- 接收请求的 node 返回 document 给协调节点。
- 协调节点返回 document 给 client。
搜索过程
- client 发送请求到协调节点。
- 协调节点将请求发送到所有的 shard 对应的 primary shard 或者 replica shard。
- 每个 shard 将自己搜索到的结果返回给协调节点,返回的是 document.id 或者 自定义的id,然后协调节点对数据进行合并排序操作,最终得到结果。
- 最后协调节点根据id到 shard 上拉取实际的 document 数据,最后返回给 client。
读写模型
ES 每个索引被分成很多个分片(默认每个索引5个主分片primary shard),每个分片可以有多个副本。当一个文档被添加或删除时(主分片新增或删除),其对应的复制分片之间需要同步。ES的数据复制模型是基于主从备份模型的。每个复制组中会有一个主分片,其他分片均为复制分片。主分片是所有索引操作的主要入口。一旦一个索引操作被主分片接受之后就会将其数据同步给其他复制分片。
基本写模型
ES的每个索引操作首先会进行路由选择定位到一个复制组,默认基于文档ID(routing),其基本算法为hash(routing)%(primary count)。定位到复制组之后,将该操作转发到该组的主分片(primary shard)。由主分片服务器负责验证并将其进行转发到其他副本。
副本是允许离线的,不要求一个复制组的所有复制分片都在线。所以复制不一定是复制到所有副本的。ES维护了一个当前在线的副本服务器列表,这个列表称作为in-sync副本,是由主分片维护的。所以主分片接收到一个文档之后,需要将文档复制到in-sync列表中的每一台服务器。
主分片处理流程
验证请求是否符合ES规范,如果不符号,直接拒绝。
在主分片执行操作,如果执行过程出问题,返回错误;否则将操作转发到当前同步副本集的每个副本(in-sync中可用的副本)。如果多个副本的话,并行执行。
一旦所有副本成功执行了并对主分片进行了响应,主服务器才对客户端返回成功。

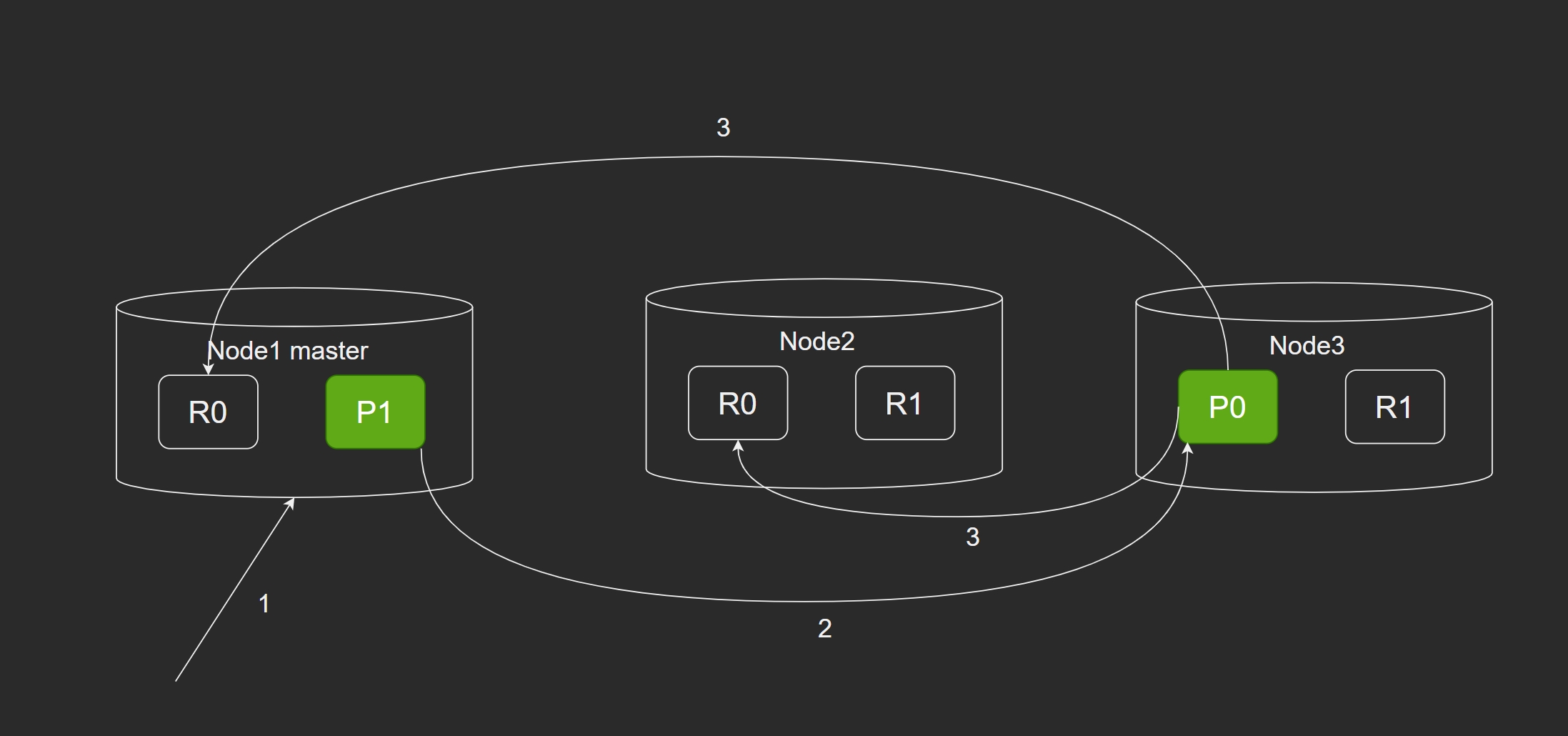
- client 向 Node1(协调节点) 发送请求(新建索引或者删除索引)。
- Node1 使用 _id 确定文档属于的 分片0 的,将请求转发给 Node3,因为 分片0 在这个节点上。
- Node3 在主分片执行请求,如果成功,就转发给相应位于 Node1 和 Node2 的复制节点上。
基本读模型
当一个节点接受到读请求时,这个节点就是协调节点,然后根据路由规则负责将其转发给相应的数据节点,对响应进行整理,最后由协调节点对客户端做出响应。
将读请求路由到相关的分片节点中。ES中一般都需要从多个分片中读取数据,每个分片代表一个不同的数据子集,ES中默认时5个主分片。
然后从每个分片复制组中选择一个副本。读请求可以是复制组中的主分片,也可以是其副本分片。默认情况下,主副分片中使用的轮询的方式进行负载均衡。
根据选择的各个分片,向选中的分片发出请求,协调节点汇聚各个分片节点返回的数据,最后返回给客户端。
异常处理:当一个分片不能响应一个读请求时,会从同一个复制组从选择另一个副本,然后发送读请求。重复的失败会导致没有分片副本可用。在某些情况下,ES更倾向于快速响应(失败后不重试),返回成功的分片数据给客户端,并在响应中指明哪些分片节点发生错误了。

博客内容遵循 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 协议
本文永久链接是:https://blog.lgq51233.xyz/2021/09/27/ElasticSearch%E8%AF%BB%E5%86%99%E5%8E%9F%E7%90%86/