

协程
协程
概念
协程是比线程, 进程更轻量的执行调度单位。
协程正在成为后台开发领域的标准技术栈。
语言层面 : Golang, Python3, C++20, Kotlin
框架层面 : Tornado(Python), LIBCO(C++), Swoole(PHP), Quasar(JavaScript)
用户态和内核态
管理计算机资源风险是很高的. 资源包括: 处理器, IO设备, 存储器, 文件等。
内核态: 运行内核相关的程序
用户态: 用户自己编写的程序
Linux设计哲学
- 对不同的操作赋予不同的执行等级
- 与系统相关的一些特别关键的操作必须由最高特权的程序来完成
四级特权, 内核态是0级, 用户态是3级.
内核态
- 内核空间: 存放的是内核代码和数据
- 进程执行操作系统内核的代码
- CPU可以访问内存所有数据, 包括外围设备
用户态
- 用户空间: 存放的是用户程序的代码和数据
- 进程在执行用户自己的代码(非系统调用之类的函数)
- CPU只可以访问有限的内存, 不允许访问外设
用户态切换到内核态 有三种方式
- 系统调用.
- 异常中断. 执行用户态程序时, 发生不可预估的异常事件.
- 外围设备中断. 磁盘(当DMA数据准备好了, 就会先CPU发出中断信号), 网卡等外围设备的中断.
计算密集型和IO密集型
sysstat工具
# 安装
sudo apt install sysstat
# 验证是否安装
sar -h
# 基本使用
# 每5s统计一次, 统计10次
sar -u 5 10
# %user 用户空间cpu占用比
# %nice 表示的是优先级
# %system 内核空间占用的cpu百分比
# %iowait cpu等待io完成的时间占比
# %steal 虚拟机相关的cpu状态
# %idle cpu空闲的时间占比
sar -b 5 10
# tps io传输总量. 等于 rtps + wtps
# rtps 读
# wtps 写
# dtps
# bread/s 从物理设备读入的数据量. 单位是 block, 块
# bwrtn/s 向物理设备写入的数据量
# bdscd/s
计算密集型
- 也称为ieCPU密集型(CPU bound)
- 完成一项任务的时间取决于CPU的速度
- CPU利用率高, 其他事情处理慢
- 游戏画面渲染, AI模型训练, 视频解码, 图片卷积处理
IO密集型
- 频繁读写网络, 磁盘等任务都属于IO密集型任务
- 完成一项任务的时间取决于IO设备的速度
- CPU利用率低, 大部分时间在等待设备完成
- Web应用(网络读写), 下载工具, 复制粘贴
线程与进程
线程的实现方式
实现方式的关键是管理线程发生的位置.
- 内核支持线程
- 用户级线程
- 组合方式线程
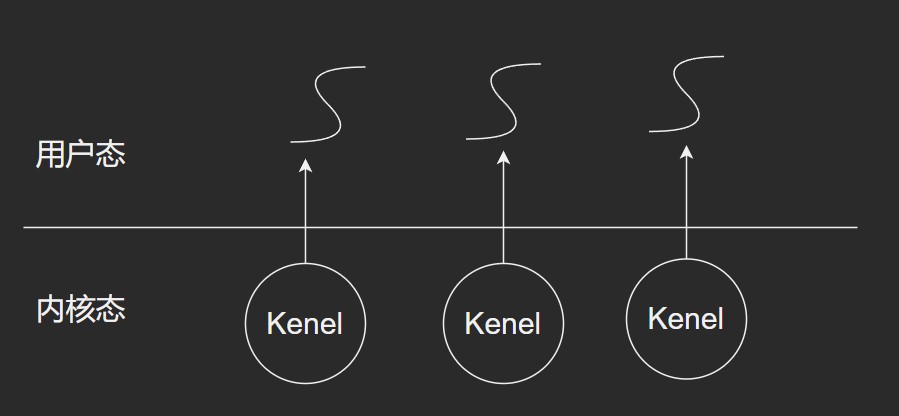
内核支持线程(KST)
内核态线程和用户态线程是一对一的关系.
- 无论是线程的创建, 撤销, 状态的切换都由内核态完成的. 操作系统本身也使用多线程.
- 调度灵活, 因为和操作系统使用的线程是一致的
- 内核线程切换成本高(平时更多逻辑集中到用户态)
用户级线程
- 线程的创建, 销毁, 线程间通信都发生在用户态, 不需要内核态的支持
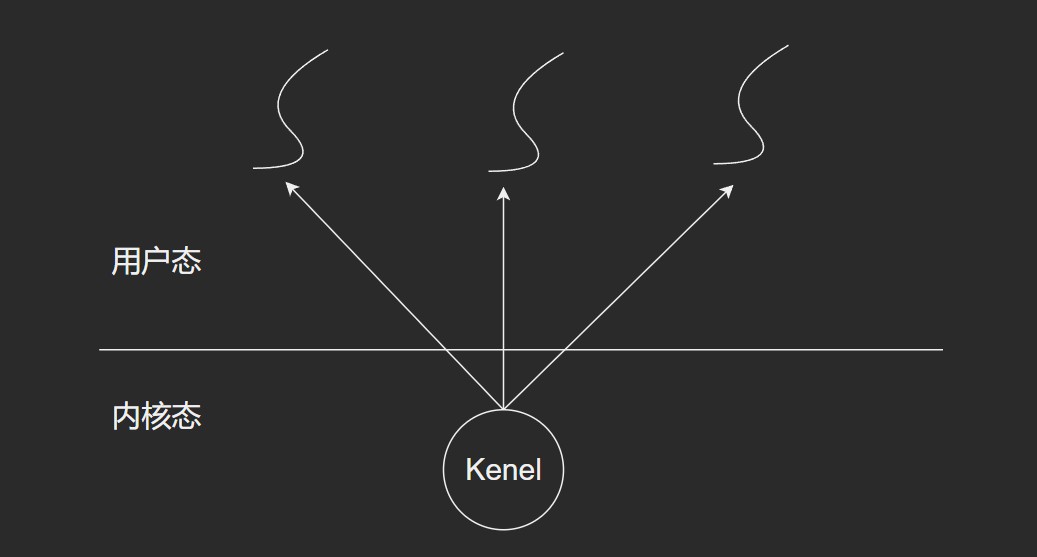
操作系统有专门的区域管理进程和线程. 相关结构就是进程控制块(PCB)和线程控制块(TCB).
因为用户态线程没有在内核态创建TCB, 所以内核态是感知不到用户级线程存在的.
所以, 从这种模型角度去看的话, 内核态线程与用户态线程是多对一的关系.
- 由用户自行调度, 内核无法干涉
- 内核线程阻塞, 所有线程无法运行
- 例如文件的读写, 要经过系统调用, 这时候逻辑就会从用户态切换到内核态. 而磁盘的速度要比CPU慢很多, 所以会阻塞, 内核线程无法感知到用户线程的存在, 所以即使阻塞了, 也无法调度.
组合方式线程
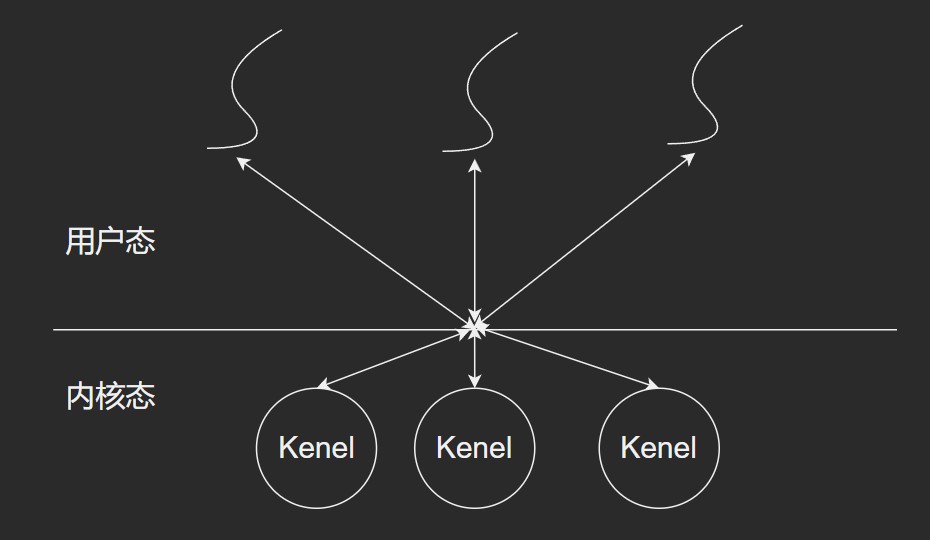
多对多关系, 解决了用户级线程和内核支持线程的问题.
常见编程语言的线程模型
C/C++, 一对一的关系
- 操作系统由C/C++实现
- 使用原生thread
Java
- Thread,Runnable对象
- JVM 封装了操作系统的Thread
JavaScript
- JavaScript是单线程的
- 通过async,yield等关键字也实现了用户级线程
Golang
- 典型的组合方式。
- 高效的G-P-M 模型。G-协程, 用户级线程; M-内核级线程; P-调度G和M的关系。
- 性能强大,并发效率高
Python
- 组合方式,提供Thread线程对象
- yield,await,async等关键字
- asyncio等协程库
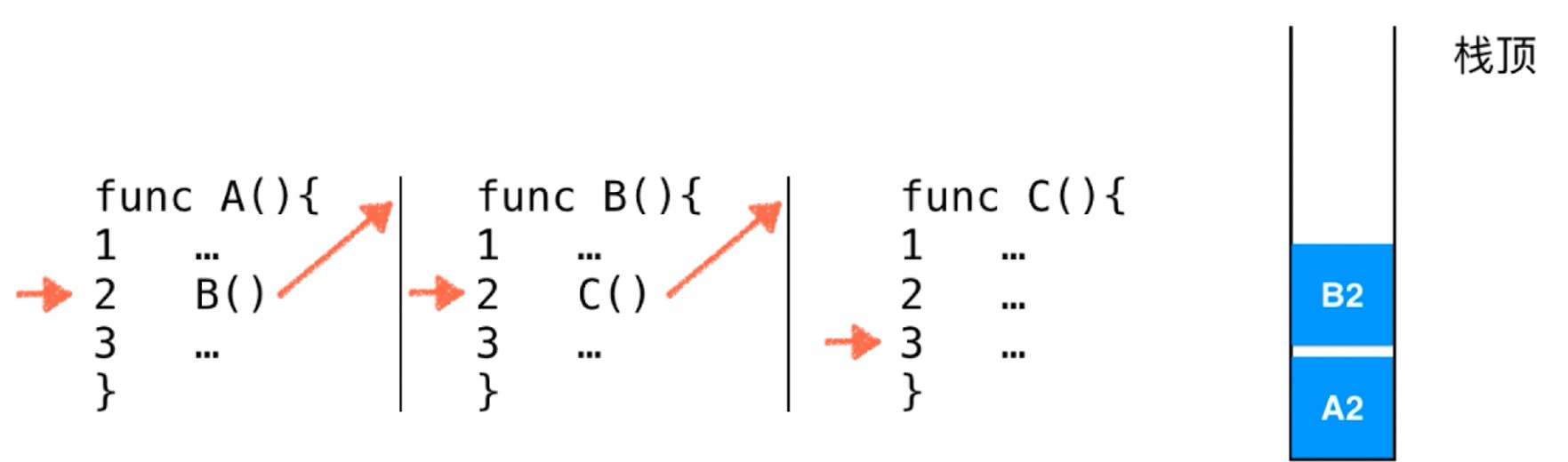
进程与线程的上下文切换
进程控制块:
- 标识符
- 状态
- 优先级
- 程序计数器
- 内存指针
- 上下文数据
- IO状态信息
- 记账信息
上下文类型:
- 寄存器级上下文
- 用户级上下文
- 系统级上下文
进程切换大致流程:
- 准备就绪进程运行数据
- 保存当前进程运行状态
- 迁出当前进程数据
- 迁入就绪进程数据
- 恢复就绪进程上一次运行状态
- 就绪进程开始运行
上下文切换成本
sar -w 1 10
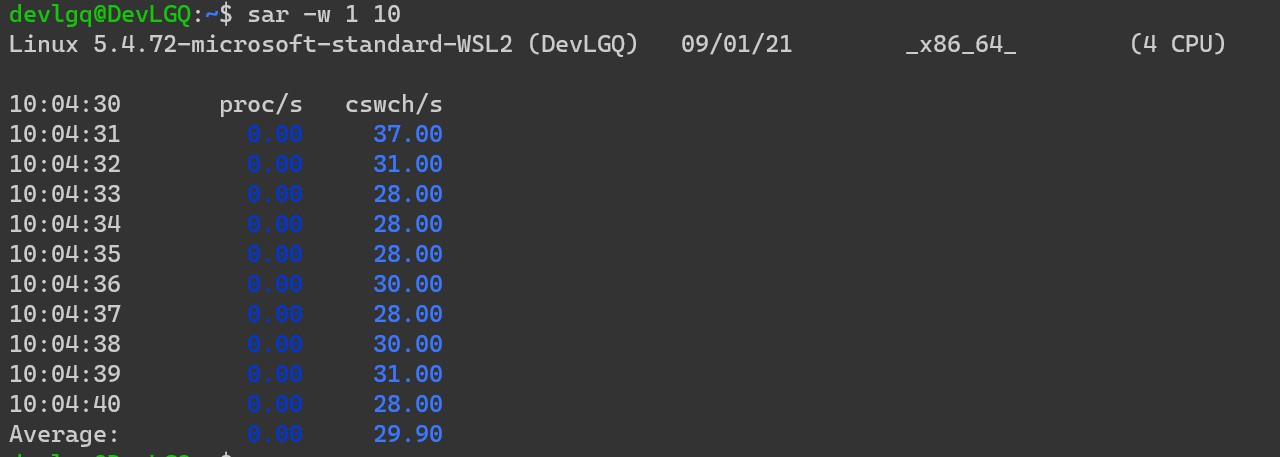
据统计,上下文切换2us ~ 5us左右。比如:8核的机器,如果每秒钟40000次切换,那么 5us * 40000 / 1000 / 8 = 25ms。
也就是说,每一核每秒钟有25ms是浪费在上下文切换的.
进程的线程共享进程资源。
- 同一进程的多线程直接切换
- 不同进程的线程之间切换(进程切换)
协程本质
协程: Coroutine
- 微线程
- 纤程
- 协作式线程
特点
- 比线程更小的粒度
- 运行效率更高
- 可以支持更高的并发
协程叫做协作式线程的原因
- 由用户自行调度, 内核无法干涉
- 两个用户级线程,协作式运行,并且相互让步

所以协程的本质就是 用户级线程
区分: 管理方式的位置。
一般提到线程都是指 内核级线程。
优缺点
- 调度, 切换, 管理更加轻量
- 内核无法感知协程的存在
解释型语言的多线程
解释型语言: Python, Ruby, Php, Lua, JavaScript, Perl, Shell
- Ruby 解释器拥有和Python类似的GIL, 伪多线程
- Php 默认不支持多线程; 安装额外C扩展以支持多线程
- Lua 只支持单线程; 可以使用多进程
- Perl 多线程在 Linux 是通过多个 Process 实现的
- Shell 没有线程的概念
- JavaScript 是单线程的; 异步接口很成熟
Java中的协程
目前Java还没正式支持协程的,JEP已经提出支持了。现在已经有EA版本了,下载地址:http://jdk.java.net/loom/。
下面测试下线程和协程的性能,测试代码如下:
package org.lgq;
import java.io.*;
import java.nio.channels.FileChannel;
import java.nio.charset.StandardCharsets;
import java.security.NoSuchAlgorithmException;
import java.security.SecureRandom;
import java.util.*;
import java.util.concurrent.ConcurrentHashMap;
/**
* 词频统计
*/
public class Main {
public static void main(String[] args) {
Main main = new Main();
// 单线程
// main.singleThread();
float totalTime = 0f;
for (int i = 0; i < 10; i++) {
// 多线程
System.out.println();
float costTime = main.commonWordCount((fileName, start, end, result) -> Thread.ofPlatform().start(new WordCountTask(fileName
, start, end, result)));
// 协程
// System.out.println();
// float costTime =
// main.commonWordCount((fileName, start, end, result) -> Thread.startVirtualThread(new WordCountTask(fileName,
// start, end, result)));
totalTime += costTime;
}
System.out.println("平均时间:" + totalTime / 10f);
}
record WordCountTask(String fileName, long start, long end, List<Map<String, Integer>> result) implements Runnable {
@Override
public void run() {
wordCount(fileName, start, end, result);
}
}
private static void wordCount(String fileName, long start, long end, List<Map<String, Integer>> result) {
try (var channel = new RandomAccessFile(fileName, "rw").getChannel()) {
var mBuf = channel.map(
FileChannel.MapMode.READ_ONLY,
start,
end - start
);
var str = StandardCharsets.US_ASCII.decode(mBuf).toString();
result.add(countByString(str));
} catch (Exception e) {
e.printStackTrace();
}
}
@FunctionalInterface
interface TaskFun {
Thread apply(String fileName, long start, long end, List<Map<String, Integer>> result);
}
/**
* 统计词频公共逻辑
*/
public float commonWordCount(TaskFun taskFun) {
var fileName = "word";
var chunkSize = 1024 * 1024 * 2;
var file = new File(fileName);
var fileSize = file.length();
long position = 0;
var startTime = System.currentTimeMillis();
var totalMap = new ConcurrentHashMap<String, Integer>();
List<Thread> allThread = new ArrayList<>();
List<Map<String, Integer>> result = Collections.synchronizedList(new ArrayList<>());
while (position < fileSize) {
var next = Math.min(position + chunkSize, fileSize);
final long start = position;
allThread.add(taskFun.apply(fileName, start, next, result));
position = next;
}
allThread.forEach(fiber -> {
try {
fiber.join();
} catch (InterruptedException e) {
e.printStackTrace();
Thread.currentThread().interrupt();
}
});
System.out.format("split to %d tasks\n", result.size());
result.forEach(map -> map.forEach((k, v) -> incKey(k, totalMap, v)));
float costTime = (System.currentTimeMillis() - startTime) / 1000f;
System.out.println("cost time: " + costTime + "s");
System.out.println("ababb: " + totalMap.get("ababb"));
System.out.println("total: " + totalMap.size());
return costTime;
}
private static Map<String, Integer> countByString(String str) {
var map = new ConcurrentHashMap<String, Integer>();
StringTokenizer tokenizer = new StringTokenizer(str);
while (tokenizer.hasMoreTokens()) {
var word = tokenizer.nextToken();
incKey(word, map, 1);
}
return map;
}
private static void incKey(String key, ConcurrentHashMap<String, Integer> map, Integer n) {
if (map.containsKey(key)) {
map.put(key, map.get(key) + n);
} else {
map.put(key, n);
}
}
/**
* 单线程
*/
public void singleThread() {
System.out.println("单线程处理开始");
var fileName = "word";
var chunkSize = 1024 * 1024 * 2;
var file = new File(fileName);
var fileSize = file.length();
long position = 0;
var startTime = System.currentTimeMillis();
var totalMap = new ConcurrentHashMap<String, Integer>();
List<Map<String, Integer>> result = Collections.synchronizedList(new ArrayList<>());
while (position < fileSize) {
var next = Math.min(position + chunkSize, fileSize);
final long start = position;
wordCount(fileName, start, next, result);
position = next;
}
System.out.format("split to %d tasks%n", result.size());
result.forEach(map -> map.forEach((k, v) -> incKey(k, totalMap, v)));
System.out.println("cost time: " + (System.currentTimeMillis() - startTime) / 1000f + "s");
System.out.println("ababb: " + totalMap.get("ababb"));
System.out.println("total: " + totalMap.size());
}
/**
* 生成测试数据
*
* @throws IOException
*/
public void gen() throws IOException {
var fileName = "word";
var bufferSize = 4 * 1024;
try (var fileOut = new BufferedOutputStream(new FileOutputStream(fileName), bufferSize)) {
Random rand = SecureRandom.getInstanceStrong();
for (int i = 0; i < 1_000_000_000; i++) {
for (int j = 0; j < 5; j++) {
fileOut.write(97 + rand.nextInt(5));
}
fileOut.write(' ');
}
} catch (NoSuchAlgorithmException e) {
e.printStackTrace();
}
}
}
编译运行
# 编译
D:\SDK\JDK\jdk-19\bin\javac.exe --enable-preview --release 19 org/lgq/Main.java
# 运行
D:\SDK\JDK\jdk-19\bin\java.exe --enable-preview -Xmx30720m -Xms30720m org.lgq.Main
多线程测试结果
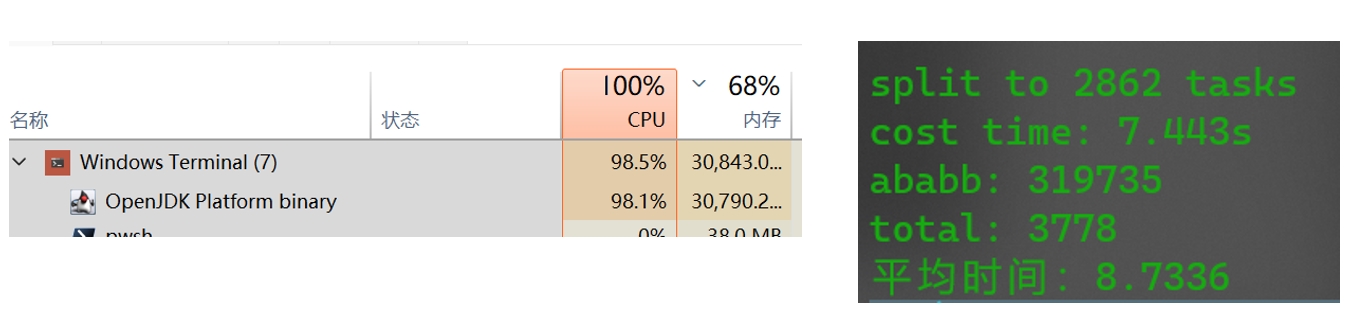
多协程测试结果
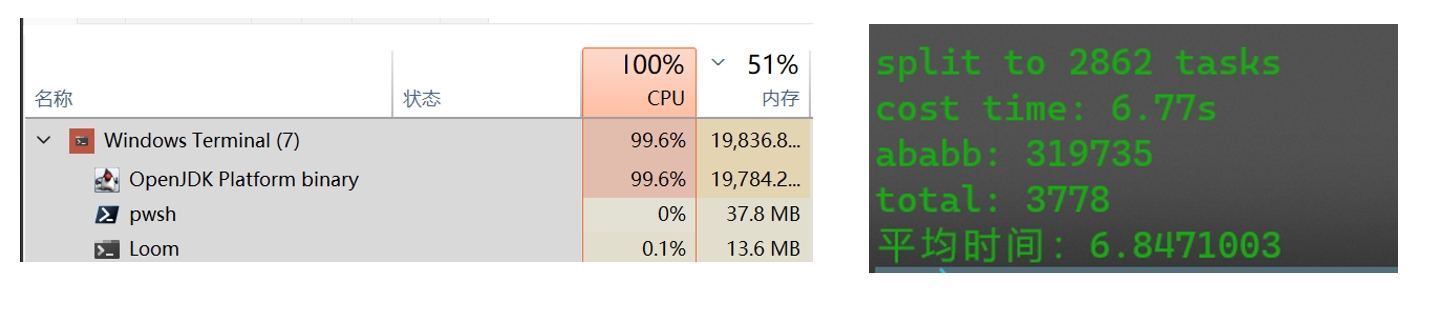
可以看到,协程的性能更优,内存占用更低。


博客内容遵循 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 协议
本文永久链接是:https://blog.lgq51233.xyz/2022/01/22/%E5%8D%8F%E7%A8%8B/